




强化学习(一)——专业术语及OpenAI Gym介绍
1. 专业术语
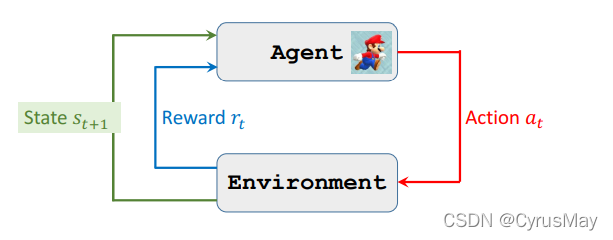
1.1 Agent(智能体)
强化学习的控制对象。
1.2 Environment(环境)
与智能体交互的对象。
1.3 State s(状态)
智能体所处状态。
1.4 Action a(动作)
智能体所能执行的操作。
1.5 Reward r(奖励)
智能体执行动作后获得奖励。
1.6 Policy π(策略函数)
动作的抽样函数。
1.7 State transition p(s’ |s, a)(状态转移函数)
Agent执行动作后获得的新状态。
1.8 Return U(回报)
未来的累计折扣奖励: U t = R t + γ R t + 1 + γ 2 R t + 2 + ⋅ ⋅ ⋅ U_t = R_t+\gamma R_{t+1}+ \gamma ^2R_{t+2} + ··· Ut=Rt+γRt+1+γ2Rt+2+⋅⋅⋅
1.8 Action-value function(动作价值函数)
Q π ( s t , a t ) = E [ U t ∣ a t , s t ] Q_π(s_t,a_t)=E[U_t|a_t,s_t] Qπ(st,at)=E[Ut∣at,st]
1.9 Optimal action-value function(最优动作价值函数)
Q π ∗ ( s t , a t ) = max π Q π ( s t , a t ) Q_π^*(s_t,a_t)=\displaystyle\max_{π}Q_π(s_t,a_t) Qπ∗(st,at)=πmaxQπ(st,at)
1.10 State-value function(状态价值函数)
V π ( s t ) = E A [ Q π ( s t , A ) ] V_π(s_t)=E_A[Q_π(s_t,A)] Vπ(st)=EA[Qπ(st,A)]
2. OpenAI Gym
2.1 安装
conda create -n gym python=3.6.0
pip install gym matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 简单使用
import gym
import time
env = gym.make("CartPole-v0")
state = env.reset()
for epoch in range(100):
env.render()
time.sleep(1)
action = env.action_space.sample()
state,reward,done,info = env.step(action)
if done:
print("Finish!")
break
env.close()
本文为参考B站学习视频书写的笔记!
by CyrusMay 2022 03 28
青春是挽不回的水
转眼消失在指尖
——————五月天(疯狂世界)——————

















 1492
1492




 到【灌水乐园】发言
到【灌水乐园】发言







