






UTF-8的编码表示格式
1. 基本编码原理
UTF-8是一种变长编码格式,采用1-4个字节为字符进行编码:
- ASCII字符(0-127)使用1个字节
- 大部分汉字采用3个字节编码
- 少量不常用汉字采用4个字节编码
2. 不同的编码表示方式
2.1 十六进制编码
在内存或数据传输中,需要转换成十六进制的形式
转换原理说明:

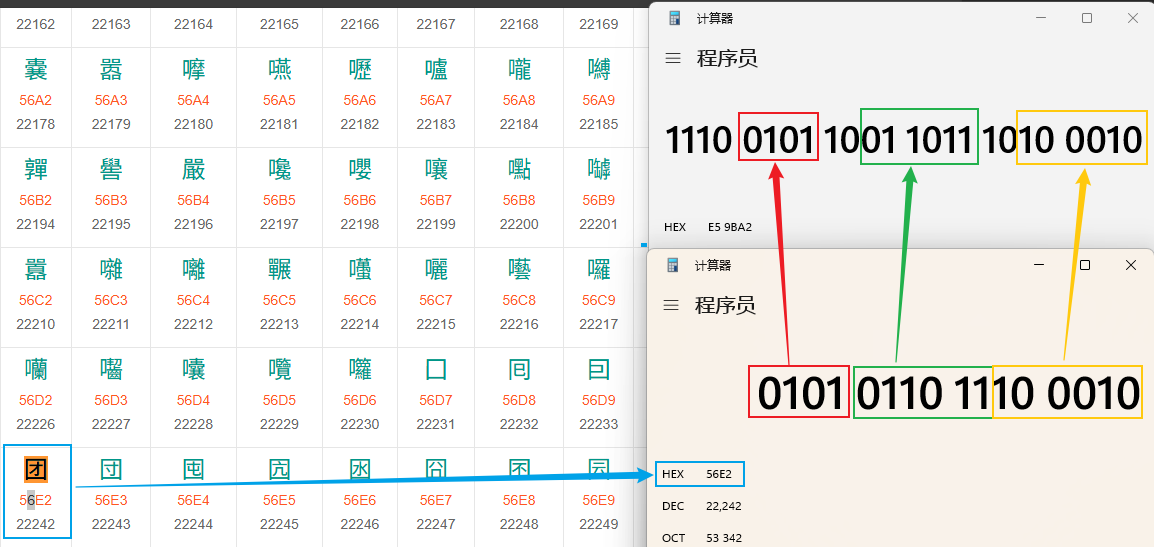
如"团"字的编码编号是:0x56e2 ,UTF-8编码转换过程如下:
- Unicode码点:
U+56E2(0x56E2 = 22242) - 根据UTF-8编码规则,这个码点落在U+0800到U+FFFF范围内,需要用3个字节表示
- 按照UTF-8编码算法计算得到:
11100101 10100110 10100010(二进制) - 转换为十六进制就是:
0xE5 0x9B 0xA2
"团"字的转换过程:
2.2 Unicode转义序列
\u56e2格式:这是Unicode转义序列的表示方式- 在许多编程语言(如Java、JavaScript、C#等)中用来表示Unicode字符
\u后面跟4位十六进制数,表示该字符的Unicode码点
2.3 Unicode码点表示
U+56E2格式:这是Unicode标准中表示字符码点的标准方式U+是Unicode码点的标准前缀- 后面跟随4位十六进制数表示字符在Unicode字符集中的位置
3. 为什么有这些不同格式
不同的编码表示方式服务于不同的用途:
-
\uXXXX格式:- 主要用于编程语言中的字符串字面量
- 让程序员能够在源代码中插入无法直接输入或显示的字符
- 是一种文本化表示Unicode字符的方法
-
U+XXXX格式:- Unicode标准规定的官方表示法
- 用于文档、规范和技术交流中标识特定字符
- 更加正式和标准化
-
十六进制格式:
- 实际存储和传输时的数据表示
- 最接近计算机内部真实存储形式的表示
这些不同的表示方式都是为了在不同场景下方便地表示和操作UTF-8编码的字符,本质上它们都指向同一个字符,只是表现形式不同。
4.参考资料:
1.这个up讲的挺好,可以看看:图一也是来源于此: 最主流的字符编码方式——UTF-8_哔哩哔哩_bilibili
2.可以在网上找一些字符编码表查询和utf-8 字符串转十六进制的网站进行测试
5.测试代码
用AI生成了一个测试程序,可以将输入的文本utf-8 十六进制编码打印出来,源代码如下:
#include <iostream>
#include <string>
#include <iomanip>
#include <sstream>
#include <cstdint>
// 函数:将UTF-8字符转换为Unicode码点
uint32_t utf8_to_unicode(const std::string& utf8_char, size_t& bytes_consumed) {
if (utf8_char.empty()) {
bytes_consumed = 0;
return 0;
}
uint8_t first_byte = static_cast<uint8_t>(utf8_char[0]);
bytes_consumed = 0;
// 单字节字符 (0xxxxxxx)
if ((first_byte & 0x80) == 0) {
bytes_consumed = 1;
return first_byte;
}
// 双字节字符 (110xxxxx 10xxxxxx)
else if ((first_byte & 0xE0) == 0xC0) {
if (utf8_char.length() < 2) return 0; // 不完整的序列
uint32_t code_point = ((first_byte & 0x1F) << 6) |
(static_cast<uint8_t>(utf8_char[1]) & 0x3F);
bytes_consumed = 2;
return code_point;
}
// 三字节字符 (1110xxxx 10xxxxxx 10xxxxxx)
else if ((first_byte & 0xF0) == 0xE0) {
if (utf8_char.length() < 3) return 0; // 不完整的序列
uint32_t code_point = ((first_byte & 0x0F) << 12) |
((static_cast<uint8_t>(utf8_char[1]) & 0x3F) << 6) |
(static_cast<uint8_t>(utf8_char[2]) & 0x3F);
bytes_consumed = 3;
return code_point;
}
// 四字节字符 (11110xxx 10xxxxxx 10xxxxxx 10xxxxxx)
else if ((first_byte & 0xF8) == 0xF0) {
if (utf8_char.length() < 4) return 0; // 不完整的序列
uint32_t code_point = ((first_byte & 0x07) << 18) |
((static_cast<uint8_t>(utf8_char[1]) & 0x3F) << 12) |
((static_cast<uint8_t>(utf8_char[2]) & 0x3F) << 6) |
(static_cast<uint8_t>(utf8_char[3]) & 0x3F);
bytes_consumed = 4;
return code_point;
}
// 无效的UTF-8序列
return 0;
}
// 函数:将单个字符转换为十六进制表示
std::string char_to_hex(uint8_t ch) {
std::stringstream ss;
ss << "0x" << std::hex << std::uppercase << std::setw(2) << std::setfill('0') << static_cast<int>(ch);
return ss.str();
}
int main() {
//程序中可以直接使用 utf-8 字符码码点
//虽然不知道干嘛用,但是觉得有点意思,应该是编译器做了转换了
std::cout << "\u56e2\n";
std::cout << "请输入一个包含UTF-8字符的字符串: ";
std::string input;
std::getline(std::cin, input);
std::cout << "\n字符分析结果:" << input << ",length:"<< input.length() << std::endl;
std::cout << "----------------------------------------\n";
std::cout << "字符\t|\t码点\t|\tUTF-8十六进制序列\n";
std::cout << "----------------------------------------\n";
size_t i = 0;
while (i < input.length()) {
// 获取下一个UTF-8字符
size_t bytes_consumed = 0;
std::string utf8_char = input.substr(i);
uint32_t unicode_code_point = utf8_to_unicode(utf8_char, bytes_consumed);
if (bytes_consumed == 0) break;
// 提取当前字符
std::string current_char = input.substr(i, bytes_consumed);
// 显示字符
std::cout << (current_char == " " ? "[空格]" : current_char) << "\t|\t";
// 显示Unicode码点
std::cout << "U+" << std::hex << std::uppercase << std::setw(4) << std::setfill('0')
<< unicode_code_point << "\t|\t";
// 显示UTF-8十六进制序列
for (size_t j = 0; j < bytes_consumed; ++j) {
std::cout << char_to_hex(static_cast<uint8_t>(input[i + j])) << " ";
}
std::cout << "\n";
i += bytes_consumed;
}
std::cout << "----------------------------------------\n";
return 0;
}
编译测试:
#编译源码
$ g++ -std=c++11 -o utf8_encoder main.cpp
$ ./utf8_encoder
请输入一个包含UTF-8字符的字符串: 你好utf-8
字符分析结果:你好utf-8,length:11
----------------------------------------
字符 | 码点 | UTF-8十六进制序列
----------------------------------------
你 | U+4F60 | 0xE4 0xBD 0xA0
好 | U+597D | 0xE5 0xA5 0xBD
u | U+0075 | 0x75
t | U+0074 | 0x74
f | U+0066 | 0x66
- | U+002D | 0x2D
8 | U+0038 | 0x38
----------------------------------------
可以看到 ASCII 码,内存十六进制是单个字节;而中文是三个字节。
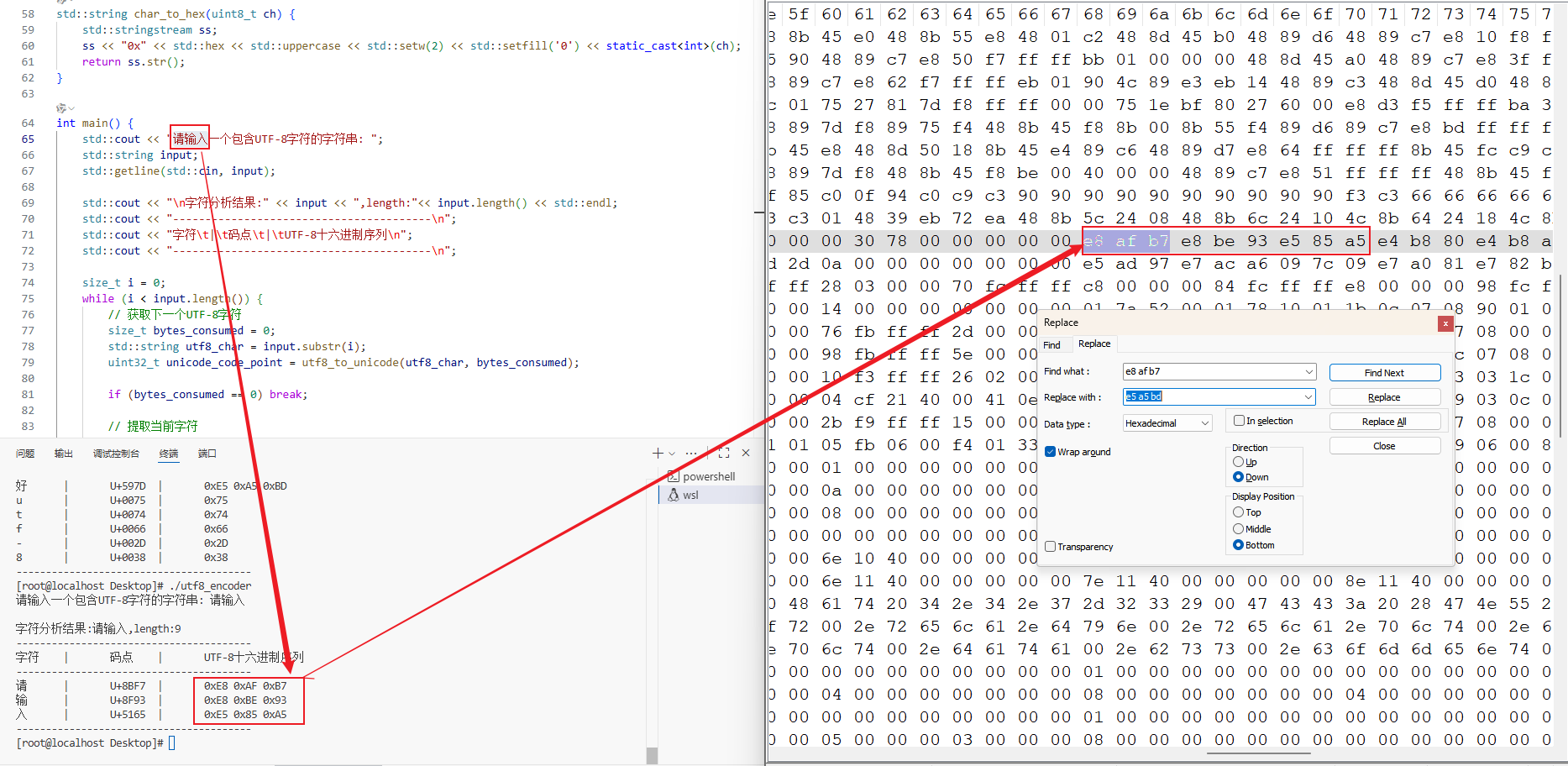
6.拓展实验
这边用十六进制编辑器,打开 utf8_encoder 程序文件。搜索可以找到程序文件中的,对应字符位置。可见程序文件中是以utf-8形式存储的静态文字数据。
可以进行替换,不编译直接再次运行时,文本会变成替换的文字。

















 3641
3641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









