




 本文探讨了WebRTC中视频和音频接收端NACK实现的不同之处,视频NACK针对关键帧进行特殊处理,而音频NACK考虑JitterBuffer的异常恢复。重点介绍了音频NackTracker接口和调度位置,并揭示了两者在处理丢失包时的策略差异。
本文探讨了WebRTC中视频和音频接收端NACK实现的不同之处,视频NACK针对关键帧进行特殊处理,而音频NACK考虑JitterBuffer的异常恢复。重点介绍了音频NackTracker接口和调度位置,并揭示了两者在处理丢失包时的策略差异。
一、概述
发送端的音视频NACK实现没有差异,是共用一套rtp_packet_history代码,这样做的好处是,当要清空NACK队列时,音视频一起清空,可以防止出现音视频不同步异常;在接收端,音视频NACK实现细节是不一样的。
视频接收端NACK实现函数是NackModule2,音频接收端NACK实现函数是NackTracker。
音视频NACK实现差异主要有两点:
- 视频NACK满足一定条件会进行IDR帧请求:视频模块会配置nack_list的最大长度为kMaxNackPackets,即本次发送的nack包至多可以对kMaxNackPackets个丢失的包进行重传请求。如果丢失的包数量超过kMaxNackPackets,会循环清空nack_list中关键帧之前的包,直到其长度小于kMaxNackPackets。也就是说,放弃对关键帧首包之前的包的重传请求,直接而快速的以关键帧首包之后的包号作为重传请求的开始。这部分请参见如下链接实现:webrtc QOS方法一.2(接收端NACK流程实现)_CrystalShaw的博客-优快云博客1、概述webrtc接收端触发发送NACK报文有两处:1、接收RTP报文,对序列号进行检测,发现有丢包,立即触发发送NACK报文。2、定时检查nack_list_队列,2、流程实现
 https://blog.youkuaiyun.com/CrystalShaw/article/details/107003142
https://blog.youkuaiyun.com/CrystalShaw/article/details/107003142 - 音频NACK因为JitterBuffer有kAccelerate(加速播放)、kExpand(减速播放)、kAlternativePlc(丢包补偿)、kMerge(融合)的异常恢复操作,不是所有报文都需要重传。所以需要在解码端需要更新nack_list的出包时间戳。
二、代码走读
1、音频接收端NACK的NackTracker对外接口函数说明
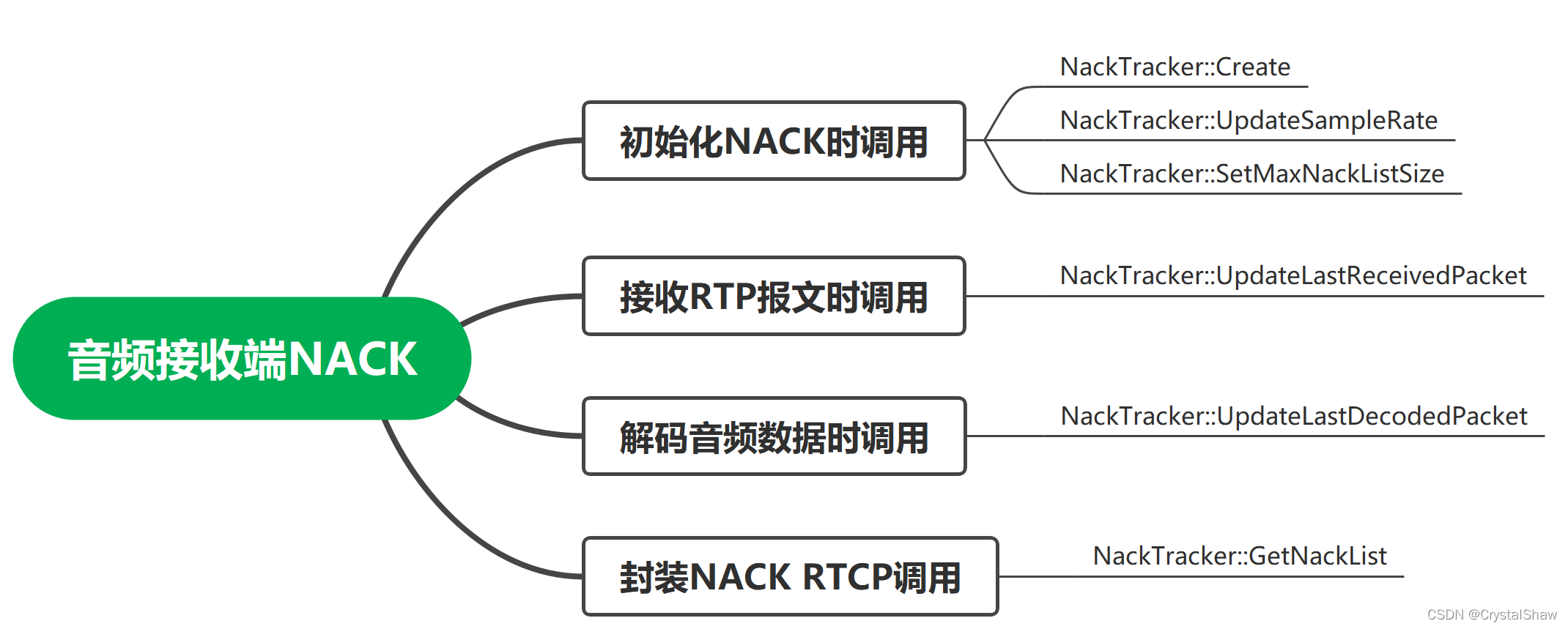
2、音频接收端NACK在系统调度位置
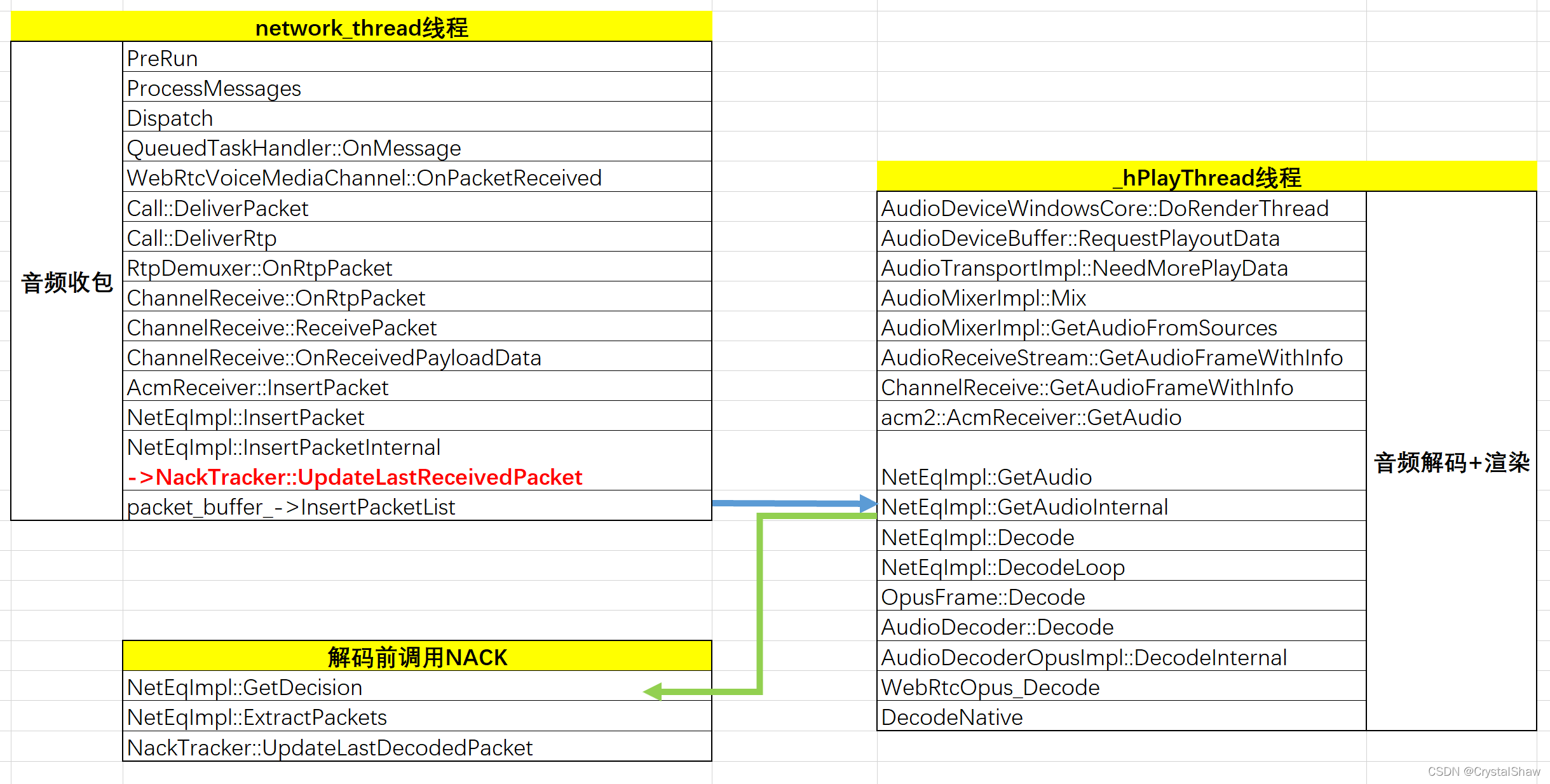
接收端检测出有丢包后,不是立刻发送NACK报文请求,首先判断这个报文离播放还有多久时间,若该包离播放时间小于一个RTT,就不申请重传了,因为即便传过来也已经过时了;若前面已经发送了一个NACK请求,判断报文尚未收到,再次发送NACK的时候,会判断两次NACK的间隔时间,是否大于阈值(这个阈值要综合考虑当前实际丢包情况,进行适当的调整),防止报文还在路上,引入的超发问题。


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









