自己写的网站非常好,却不会展现给别人? 简直是英雄无用武之地啊!!! 来看这里 超详细教程教你部署网站!!!
最新推荐文章于 2024-07-29 09:57:12 发布




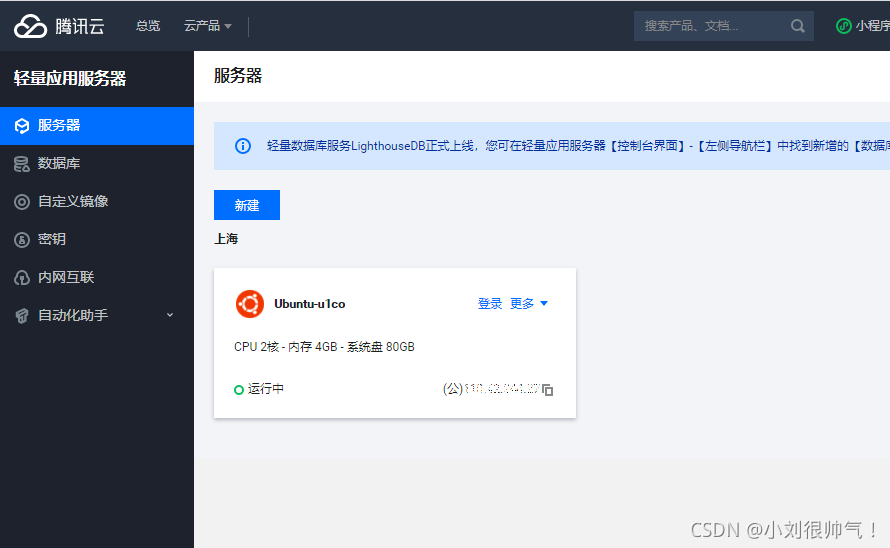
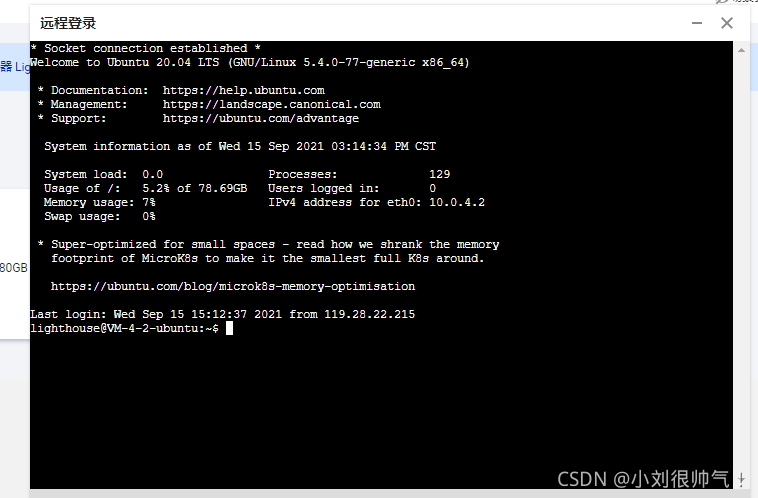
 本文指导新手如何在腾讯云购买轻量应用服务器,通过SSH登录Linux界面,简单部署HTML网页,无需深入学习Linux系统。只需几步完成个性化网站展示。
本文指导新手如何在腾讯云购买轻量应用服务器,通过SSH登录Linux界面,简单部署HTML网页,无需深入学习Linux系统。只需几步完成个性化网站展示。
本文指导新手如何在腾讯云购买轻量应用服务器,通过SSH登录Linux界面,简单部署HTML网页,无需深入学习Linux系统。只需几步完成个性化网站展示。
本文指导新手如何在腾讯云购买轻量应用服务器,通过SSH登录Linux界面,简单部署HTML网页,无需深入学习Linux系统。只需几步完成个性化网站展示。
 1825
471
5731
1825
471
5731























 到【灌水乐园】发言
到【灌水乐园】发言






