



第一章初认C语言\color{red}{第一章 初认C语言}第一章初认C语言
1972年,贝尔实验室在开发UNIX操作系统时设计了C语言,C语言的前生是B语言。
这里可能有有人要问了我听过Linux操作系统却不知道UNIX操作系统,Linux
和UNIX的区别在于Unix:最早由AT&T的贝尔实验室在20世纪70年代开发,是一种多用户、多任务的操作系统,传统的Unix系统是
商业软件,源代码和修改通常受到严格的许可证限制1。
Linux:由Linus Torvalds在1991年发起的一个开源项目,最初是作为一个
业余爱好,后来发展成为一个完整的操作系统内核。Linux内核是开源的,遵循
GNU通用公共许可证(GPL),允许用户自由使用、修改和分发源代码。
1.1语言标准\color{blue}{1.1 语言标准}1.1语言标准
目前,有许多c实现可用。同一的实现只有遵循了同一个标准,那么编译后运行结果才会不出错且相同。
这里的的编译怎样理解哪?
其实代码都是在编辑器上写的,比如c语言的编译器有jetBrains公司的clion 还
有 Microsoft公司的visual studio,只不过不同的编辑器集成的c语言标准不同。
编写完成之后通过编辑器集成的c编译器编译成可执行的代码。
- ANSI/ISO C标准(C89/C90):C89:1989年正式发布; C90:1990年正式发布。
- C99标准:1994年发布,尽量与C90和C++兼容
- C11标准:2011年发布
1.2编程机制\color{blue}{1.2 编程机制}1.2编程机制
输入源代码 -> 文本编译器 -> 源程序(XX.c) -> 编译器 -> 链接器 -> 可执行程序
用C语言编写程序时,编写的内容被存储在文本文件中,该文件被称为源代码文件,大部分的c系统都要求文件名以.c结尾。
编译器把源代码转换成中间代码,链接器把中间代码和其他代码合成,生成可执行文件。
第二章C语言概述\color{red}{第二章 C语言概述}第二章C语言概述
2.1简单的C程序实例\color{blue}{2.1 简单的C程序实例}2.1简单的C程序实例
程序:2.1
#include<stdio.h>
/*
这是第一个C程序
*/
int main(void) //程序的入口函数
{
int num; //定义一个名为num的数字变量
num = 1; //为num赋值
printf("hello C "); //使用printf()函数
printf("计算机\n");
printf("我最喜欢的编程语言,因为它是第%d。\n",num);
return 0; // 程序的返回值
}
如果一切正常代码应该输入
hello C 计算机
我最喜欢的编程语言,因为它是第1。
接下来,逐步解释这个程序。
2.2示例解释\color{blue}{2.2 示例解释}2.2示例解释
我们会把程序清单2.1的程序分析两遍。第一遍(快速概要)概述程序中 每行代码的作用。第二遍(程序细节)详细分析代码具体含义。
2.2.1 第1遍:快速概要
#include<stdio.h> <- 预处理器指令,包含另一个文件
该行告诉编译器把stdio.h中的内容包含在当前程序中,其实printf()函数就是调用的stdio.h中的内容。stdio.h是C编译器软件包的标准部分,它提供键盘输入和屏幕输出的支持。
int main(void) <-函数名
C程序包含一个或多个函数,它们是C程序的基本模块。int 表示main()函数返回一个整数,圆括号表示main()是一个函数名,void表示main()不带任何参数。(这里的void可以省略不写)
/*
这是第一个C程序
*/
//程序的入口函数
这里的//多用于单行注释,/* */ 多用于多行注释。
2.2.2 第2遍:程序细节
1. #include指令和头文件
这是程序的第一行。#include<stdio.h>的作用相当于把stdio.h文件中的所用内容都输入该行所在的位置。实际上,这是一种“拷贝-粘贴”的操作。include文件提供了一种方便的途径共享许多程序信息。
#include这行代码是一条C预处理指令。通常,C编译器在编译前会对源代码做一些准备工作,即预处理。
所用的C编译器软件包都提供stdio.h文件。该文件中包含了供编译器使用的输入和输出函数(如printf())信息。该文件名的含义是标准输入/输出头文件。通常,在C程序顶部的信息集被称为头文件
2. main()函数
main()是一个极其普通的名称,但是这是唯一的选择。C程序一定从main()函数开始执行。除了main()函数,你可以任意命名其他函数,但是main()函数必须是要开始的函数。圆括号的作用是用于识别main是一个函数。
int 是main()函数的返回值类型。这表明main()函数返回的值是整数。返回给了操作系统。
通常,函数名后面的圆括号中包含一些传入函数的信息。该例子中没有传递任何信息。因此,圆括号内是单词void.
如果游览旧的C代码,会发现程序以如下形式开始:main()
C90标准勉强接受这种形式,但是C99和C11标准不允许这样写。因此,即使你使用的编译器允许,也不要这样写。
第三章数据和C\color{red}{第三章 数据和C}第三章数据和C
3.1数据类型\color{blue}{3.1数据类型}3.1数据类型
C语言的数据类型关键字
| 最初K&R给出的关键字 | C90标准添加的关键字 | C99标准添加的关键字 |
|---|---|---|
| int | signed | _Bool |
| long | void | _Complex |
| short | _Imaginary | |
| unsigned | ||
| char | ||
| float | ||
| double |
在C语言中,用int关键字来表示基本的整数类型。后面三个关键字(long、short和unsigned)和C99新增的signed用于提供基本整数类型的变式,例如unsigned short int(简写unsigned short)和long long int(简写long long)。
char关键字用于指定字母和其他字符(如,#、$、%和*)。另外,char类型也可以表示较小的整数。
float、double和long double表示带小数点的数。
_Bool类型表示布尔值(true或false)。
_Complex和 _Imaginary分别表示复数和虚数。
通过这些关键字创建的类型,按计算机的存储方式可分为两大基本类型:整数类型和浮点数类型
位、字节和字的区别
位、字节和字是描述计算机数据单元或存储单元的术语。这里主要指存储单元。
最小的存储单元是位(bit),用0或1表示。字节(byte)是常用的计算机存储单元,对与几乎所有的机器,1字节均为8位。字(word)是设计计算机时给定的自然存储单位。对于8位微形计算机1个字长只有8位。计算机的字长越大,其数据转移越快,允许的内存访问也更多。
整数和浮点数
在C语言中,整数是没有小数部分和整数部分的。例如,2,-23和3456都是整数。而3.14、0.22和2.000都不是整数。计算机以二进制数字存储整数。
如图,整数7在8位字长中存储。

浮点数与数学中实数的概念差不都。2.75、3.16E7、7.00和2e-8都是浮点数。注意,在一个值后面加上一个小数点,该值就成为一个浮点值。计算机把浮点数分成小数部分和指数部分来表示,而且分开存储这两部分。
如图,存储浮点数3.14159为例。

整数和浮点数区别
- 整数没有小数部分,浮点数有小数部分。
- 浮点数可以表示的范围比整数大。
- 对于一些算术运算,浮点数损失的精度更多。
3.2C语言基本数据类型\color{blue}{3.2 C语言基本数据类型 }3.2C语言基本数据类型
整数类型
| C语言整数类型 | 说明 |
|---|---|
| char类型(1字节) | char类型用于存储字符,但从技术层面看,char是整数类型,因char类型实际存储的是整数而不是字符。计算机使用数字编码来处理字符,即用特定的整数表示特定的字符。美国最常用的编码是ASCII编码,C的字符也是用ASCII编码。 |
| int(4字节) | int类型是有符号整型 |
| short(2字节) | 占用空间比int小的有符号整型 |
| long(4字节或8字节) | long类型常量在值的末尾加上l或L |
| long long | 占用空间比long大的有符号整型,至少占64位,long long类型常量在值的末尾加上ll或LL |
| unsigned int 或unsigned只用于非负值的场合 | 这种类型与有符号类型表示的范围不同,用于表示正负号的位现在用于表示另一个二进制位,所以无符号整型可以表示更大的数。 |
非打印字符
单引号只适用于字符、数字和标点符号,浏览ASCII表会发现,有些ASCII字符打印不出来,例如,一些代表行为的字符(如,退格、换行等等),C语言提供了3种办法表示这些字符。
第1种办法使用ASCII码。例如蜂鸣字符的ASCII值是7,因此可以这样写:
char beep = 7;
第2种办法是,使用特殊的符号序列表示一些特殊的字符。这些符号序列叫作转义字符。
转义字符
| 转义序列 | 含义 |
|---|---|
| \a | 警报(ANSI C) |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \\ | 反斜杠 |
| ’ | 单引号 |
| " | 双引号 |
| \? | 引号 |
| \0oo | 八进制数(oo必须是有效位的八进制,即每个o可表示0-7中的一个数) |
| \xhh | 十六进制值(hh必须是有效的十六进制数,即每个h可表示0-f中的一个数) |
_Bool类型
C99标准添加了_Bool类型,用于表示布尔值,即逻辑值true和false。因为C语言用1表示true,值0表示false,所以_Bool类型实际上也是一种整数类型。但原则上它仅占用1位存储空间,因为对于0和1而言,1位的存储就够了。
下列程序,计算输入整数的和
#include<stdio.h>
int main()
{
long num;
long sum = 0L;
_Bool input_is_good;
printf("Please enter an integer to be summed");
printf("(q to quit):");
input_is_good=(scanf("%1d",&num)==1);
while(input_is_good)
{
sum=sum+num;
printf("Please enter next integer(q to quit):");
input_is_good=(scanf("%1d",&num)==1);
}
printf("Those integers sum to %1d,\n",sum);
return 0;
}
一直以来,C都习惯用int作为标记的类型,其实新增的_Bool类型更合适。另外,如果在程序中包含了stdbool.h头文件,便可用bool代替_Bool类型,用true和false分别代替1和0,这样写出的代码可以与C++兼容,因为C++把bool、true和false定义为关键字。
可移植类型:stdint.h和inttypes.h
C语言提供了许多有用的整数类型。但是,某些类型名在不同系统中的功能不一样。C99新增了两个头文件stdint.h和inttypes.h,以确保C语言的类型在各系统中的功能相同。
float、double和long double
各种整数类型对大多数软件开发项目而言够了,然而,面向金融和数学的程序经常使用浮点数。C语言种使用的浮点类型有float、double和long double类型。
通常,系统存储一个浮点数(float)要占32位。其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数或有效值)及其符号。
double类型占用64位而不是32位,一些系统将多出的32位全部用来表示非指数部分,这不仅增加了有效数字的位数(即提高了精度),而且还减少了舍入误差。另一种系统把其中的一些位分配给指数部分,以容纳更大的指数,从而增加了可表示数的范围。
long double以满足比double类型更高的精度要求,不过C只保证long double 类型至少与double类型的精度相同。
使用整数类型或浮点数类型注意它们表示的范围,防止上溢或下溢。
3.3变量和常量数据\color{blue}{3.3变量和常量数据}3.3变量和常量数据
有些数据类型在程序使用之前已经预先设定好了,在整个程序的运行过程中没有变化(比如:圆周率,性别,身份证号码,血型等等),这些称为常量。其他数据类型在程序运行期间可能会改变或赋值,(比如:年龄,体重,薪资)这些称为变量。
第四章字符串和格式化输入/输出\color{red}{第四章 字符串和格式化输入/输出}第四章字符串和格式化输入/输出
4.1前导程序\color{blue}{4.1 前导程序}4.1前导程序
程序4.1
//talkback.c
#include<stdio.h>
#include<string.h> //提供strlen()函数的原型
#define DENSITY 62.4 //人体密度(单位:磅/立方英尺)
int main()
{
float weight,volume;
int size, letters;
char name[40]; //name是一个可容纳40个字符的数组
printf("Hi!What's your first name?\n");
scanf("%s", name);
printf("%s,what's your weight in pounds?\n", name);
scanf("%f", &weight);
size = sizeof(name);
letters = strlen(name);
volume = weight / DENSITY;
printf("Well,%s,your volume is %2.2f cubic feet.\n", name, volume);
printf("and we have %d bytes to store it.\n", size);
return 0;
}
如果是用的Visual Studio集成开发环境的话,使用scanf()函数,会报错。需要在开头加上 #define _CRT_SECURE_NO_WARNINGS
运行talkback.c程序,输入结果如下:

该程序包含以下新特性。
- 用数组存储字符串。在该程序中,用户输入大的名被存储在数组中,该数组占用内存中40个连续的字节,每个字节存储一个字符值。
- 使用%s转移说明来处理字符串的输入和输出。注意scanf()中,name没有&前缀,而wight有(往后看就会明白&wight和name都是地址)
- 用C预处理把字符常量DENSITY定义为62.4。
- 用C函数strlen()获取字符串的长度。
- string.h头文件包含多个与字符串相关的函数原型,包括strlen().
4.2字符串简介\color{blue}{4.2 字符串简介}4.2字符串简介
4.2.1 char类型数组和null字符
字符串是一个或多个字符的序列,如下所示:
“zing went”
双引号不是字符串的一部分。双引号仅告知编译器它括起来的是字符串,正如单引号用于标识单个字符一样。
如图,数组中的字符串(每个存储单元1字节):

注意图4.1中数组末尾位置的字符\0。这是空字符,C语言用它标记字符串的结束。空字符不是数字0,它是非打印字符,其ASCII码值是(或等价于)0。C中的字符串一定以空字符结束,这意味着数组的容量必须至少比待存储字符串中的数字多1。
那么,什么是数组?可以把数组看作是一行连续的多个存储单元。
4.2.2 使用字符串
程序4.2
/* praise1.c -- 使用不同类型的字符串*/
#include<stdio.h>
#define PRAISE "You are an extraordinary being."
int main()
{
char name[40];
printf("what's your name?\n");
scanf("%s",name);
printf("Hello,%s.%s\n",name,PRAISE);
return 0;
}
运行praise1.c,其输出如下所示:

不用亲自把空白符(\0)放入字符串尾部,scanf()在读取输入时就已完成这项工作。也不用在字符串常量PRAISE末尾添加空字符,用双引号括起来的文本是一个字符串,编译器会在末尾加上空字符(\0)。
注意(这个很重要),scanf()只读取了小李 冷中的小李,它在遇到第1个空白(空格、制表符或换行符)时就不再读取输入。因此,scanf()在读到小李和冷之间的空格时就停止了。一般而言,根据%s转化说明,scanf()只会读取字符串中的一个单词,而不是一整句。C语言还有其他的输入函数(如,fgets()),用于读取一般字符串。后面会说到。
字符串常量和字符常量的不同
1. 字符常量是基本类型(char),而字符串常量是派生类型(char数组)。
2. 如果字符串常量是“c”,那么它由两个字符组成:‘c’和\0。
4.2.3 strlen()函数和sizeof运算符
- strlen()函数给出字符串中字符长度。
- sizeof是以字节为单位给出对象大小的单目运算符。如果运算符右边是变量,可以把变量用()括起来也可以不用;如果是数据类型则必须用()括起来。(sizeof返回的大小是无符号整数,所以在使用printf()函数显示时,使用%u的话可以防止一些错误)
4.3ctype.h系列的字符函数\color{blue}{4.3 ctype.h 系列的字符函数}4.3ctype.h系列的字符函数
c有一系列专门处理字符的函数,ctype.h头文件包含了这些函数的原型。这些函数接受一个字符作为参数,如果该字符属于某特殊的类别,就返回一个非零值(真);否则,返回0(假)。例如,如果isalpha()函数的参数是一个字母,则返回一个非零值。下面程序使用了这个函数。
// 替换输入的字母,非字母字符保持不变
#include<stdio.h>
#include<ctype.h> //包含isalpha()的函数原型
int main()
{
char ch;
while((ch = getchar()) != '\n')
{
if(isalpha(ch)) //如果是一个字符
putchar(ch + 1); //显示该字符的下一个字符
else //否则
putchar(ch); //原样显示
}
putchar(ch); //显示换行符
return 0;
}
下表 ctype.h头文件中的字符测试函数
| 函数名 | 如果是下列参数时,返回值为真 |
|---|---|
| isalnum() | 字母数字(字母或数字) |
| isalpha() | 字母 |
| isblank() | 标准的空白字符(空格、水平制表符或换行符)或任何其他本地化指定为空白的字符 |
| iscntrl() | 控制字符,如Ctrl+B |
| isdigit() | 数字 |
| isgraph() | 除空格之外的任意可打印字符 |
| islower() | 小写字母 |
| isprint() | 可打印字符 |
| ispunct() | 标点符号(除空格或字母数字字符以外的任意可打印字符) |
| isspace() | 空白字符(空格、换行符、换页符、回车符、垂直制表符、水平制表符或其他本地化定义的字符) |
| isupper() | 大写字母 |
| isxdigit() | 十六进制数字符 |
下表 ctype.h头文件中的字符映射函数
| 函数名 | 行为 |
|---|---|
| tolower() | 如果参数是大写字符,该函数返回小写字符;否则,返回原始参数 |
| toupper() | 如果参数是小写字符,该函数返回大写字符;否则,返回原始参数 |
4.4常量和预处理器(#define)\color{blue}{4.4常量和预处理器(\#define)}4.4常量和预处理器(#define)
#include这行代码是一条C预处理器指令。通常,C编译器在编译前会对源代码做一些准备工作,即预处理。
预处理器也可用来定义常量。只需在程序顶部添加下面一行:
#define TAXRATE 0.015
编译程序时,程序中所有的TAXRATE都会被替换成0.015。这一过程被称为编译时替换。在运行程序时,程序中所有的替换均已完成。通常,这样定义的常量也称为明示常量。
4.4.1 const限定符
C90标准新增了const关键字,用于限定一个变量为只读。其声明如下:
const int MONTHS = 12; //MONTHS 在程序中不可更改,值为12
这使得MONTHS成为一个只读值。也就是说,可以在计算中使用MONTHS,可以打印MONTHS,但是不能更改MONTHS的值。const用起来比#define更灵活。
4.4.2 明示常量
C头文件limits.h和float.h分别提供了与整数类型和浮点类型大小限制相关的详细信息。每个头文件都定义了一系列供实现使用的明示常数。例如,limits.h头文件包含以下代码:
#define INT_MAX +32767
#define INT_MIN -32768
这些明示常量代表int类型可表示的最大值和最小值。
limits.h中的一些明示常量:
| 明示常量 | 含义 |
|---|---|
| CHAR_BIT | char类型的位数 |
| CHAR_MAX | char类型的最大值 |
| CHAR_MIN | char类型的最小值 |
| SCHAR_MAX | signed char类型的最大值 |
| SCHAR_MIN | signed char类型的最小值 |
| UCHAR_MAX | unsignd char类型的最大值 |
| UCHAR_MIN | unsignd char类型的最小值 |
| SHRT_MAX | short类型的最大值 |
| SHRT_MIN | short类型的最小值 |
| USHRT_MAX | unsignd short类型的最大值 |
| INT_MAX | int 类型的最大值 |
| INT_MIN | int 类型的最小值 |
| UINT_MAX | unsigned int 的最大值 |
| LONG_MAX | long类型的最大值 |
| LONG_MIN | long类型的最小值 |
| ULONG_MAX | unsigned long 类型的最大值 |
| LLONG_MAX | long long 类型的最大值 |
| LLONG_MIN | long long 类型的最小值 |
| ULLONG_MAX | unsigned long long 类型的最大值 |
类似地,float.h头文件中也定义一些明示常量,如FLT_DIG和DBL_DIG,分别表示float类型和double类型的有效数字位数。下表列出了float.h中的一些明示常量。表中所列都与float类型相关。把明示常量名中的FLT分别替换成DBL和LDBL,即可分别表示double和long double 类型对应的明示常量。
float.h中的一些明示常量:
| 明示常量 | 含义 |
|---|---|
| FLT_MANT_DIG | float类型的尾数位数 |
| FLT_DIG | float类型的最少有效数字位数(十进制) |
| FLT_MIN_10_EXP | 带全部有效数字的float类型的最小负指数(以10为底) |
| FLT_MAX_10_EXP | float类型的最大正指数(以10为底) |
| FLT_MIN | 保留全部精度的float类型最小正数 |
| FLT_MAX | float类型的最大正数 |
| FLT_EPSILON | 1.00和比1.00大的最小float类型值之间的差值 |
4.5printf()和scanf()\color{blue}{ 4.5 printf()和scanf()}4.5printf()和scanf()
printf()函数和scanf()函数能让用户可以与程序交流,它是输入/输出函数,或简称为I/O函数。
虽然printf()是输出函数,scanf()是输入函数,但是它们的工作原理几乎相同。两个函数都使用格式字符串和参数列表。
4.5.1 printf()函数
请求printf()函数打印数据指令要与待打印数据的类型相匹配。例如打印字符时使用%d,打印字符时使用%c。这些符号被称为转移说明,它们指定了如何把数据转换成可显示的形式。
printf()的返回打印字符的个数,如果输出错误,printf()则返回一个负值。
下表列出了一些转移说明和各自对应的输出类型。
| 转移说明 | 输出 |
|---|---|
| %a或着%A | 浮点数、十六进制数和p计数法(C99/C11) |
| %c | 单个字符 |
| %d | 有符号十进制整数 |
| %e或者%E | 浮点数,e记数法 |
| %f | 浮点数,十进制记数法 |
| %g或者%G | 根据值的不同,自动选择%f或者%e。%e格式用于指数小于-4或者大于等于精度时 |
| %o | 无符号八进制整数 |
| %p | 指针 |
| %s | 字符串 |
| %u | 无符号十进制整数 |
| %x或者%X | 无符号十六进制整数,使用十六进制数0f\0F |
| %% | 打印百分号 |
警告:
格式字符串中的转移说明一定要与后面的每个项相匹配,若忘记这个基本要求会导致严重的后果。
千万别写成这样: printf("The score was Squids %d, Slugs %d.\n",score1);
这里,第2个%d没有对应任何项。系统不同,导致的结果也不同。不过,出现这种问题最好的状态是得到无意义的值。
4.5.2 printf()的转换说明修饰符
在%和转换字符之间插入修饰符可修饰基本的转换说明。
表1:
| 修饰符 | 含义 |
|---|---|
| 标记 | 下面的表格2描述了5种标记(-、+、空格、#和0),可以不使用标记或使用多个标记。示例:“%-10d” |
| 数字 | 最小字段宽度。如果该字段不能容纳待打印的数字或字符串,系统会使用更宽的字段。 示例:“%4d” |
| .数字 | 精度。示例:“%5.2”打印一个浮点数,字段宽度为5字符,其中小数点后有两位数字 |
注意:float参数的转换
一般而言,ANSI C不会把float自动转换成double。
然而,有大量的现有程序都假设float类型的参数被自动转换成double类型,为了保护这些程序,printf()函数中所有的float类型的参数
仍自动转换成double类型。所以在printf()函数中用转移说明“%f”和“%e”是相同的。
表2:
| 标记 | 含义 |
|---|---|
| - | 待打印项左对齐。即,从字段的左侧开始打印该项。示例:“%-20s” |
| + | 有符号值若为正,则在前面显示加号;若为负,则在值前面显示减号。示例:“%+6.2f” |
| 空格 | 有符号值若为正,则在前面显示前导空格(不显示任何字符);若为负,则在值前面显示减号标记并覆盖空格。示例:“% 6.2f” |
| # | 把结果转换为另一种形式。如果是%o格式,则以0开始;如果是%x或%X格式,则以0x或0X开始;对于所有的浮点格式,#保证了即使后面没有任何数字,也打印一个小数点字符。对于%g和%G格式,#防止结果后面的0被删除。示例:“%#o”、“%#8.0f” |
| 0 | 对于数值格式,用前导0代替空格填充字段宽度。对于整数格式,如果出现-标记或指定精度,则省略该标记 |
4.5.3 转移说明的意义
转移说明把以二进制格式存储在计算机中的值转换成一系列字符(字符串)以便显示。例如数字76在计算机内部的存储格式是二进制数01001100。%d转移说明将其转换成字符7和6,并显示为76;%x转换说明把相同的值(01001100)转换成十六进制记数法4c;%c转换说明把01001100转换成字符L。
转换可能会误导读者认为原始值被替换成转换后的值。实际上,转换说明是翻译说明,%d的意思是“把给定的值翻译成十进制整数文本并打印出来”。
下面以一个程序为例说明printf()函数参数传递的细节
/* floatcnv.c -- 不匹配的浮点型转换 */
#include <stdio.h>
int main()
{
float n1 = 3.0;
double n2 = 3.0;
long n3 = 2000000000;
long n4 = 1234567890;
printf("%.1e %.1e %.1e %.1e\n",n1,n2,n3,n4);
printf("%1d %1d\n",n3,n4);
printf("%1d %1d %1d %1d\n",n1,n2,n3,n4);
return 0;
}
程序运行结果:

注意:
有大量的现有程序都假设float类型的参数被自动转换成double类型,为了保护这些程序,printf()函数中所有的float类型的参数仍自动转换成double类型。
所以在printf()函数中用转移说明“%f”和“%e”是相同的。
可以看到第一个printf()函数打印的n3和n4整数(long类型)转换为浮点数出现了错误,分析:首先,%e转移说明让printf()函数认为待打印的值是double类型(本系统是为8字节)。当printf()查找n3时,除了查找n3的个字节外,还会查看n3相邻的4个字节,共8字节单元。接着,它将8字节单元中的位组合解释成浮点数,整数和浮点数存储的位组合不同(如,它把一部分位组合解释成指数)。因此,即使n3的位数正确,根据%e转换说明和%1d转换说明解释出来的值也不同,最终得到的结果是无意义的值。
第二个printf()函数使用正确的转移说明,printf()可以正确打印n3和n4。
第三个printf()函数,如果printf()语句有其他不匹配的地方,即使用对了转移说明也会生成虚假的结果。用%1d转换说明打印浮点数会失败,但是在这里,用%1d打印long类型的数也失败了,着就涉及到了参数传递的问题了。
参数传递:
下面以上面程序中的程序为例,分析参数传递的原理,函数调用如下:
printf(“%1d %1d %1d %1d\n”,n1,n2,n3,n4);
该调用告诉计算机把变量n1、n2、n3、n4的值传递给程序。这是一种常见的参数传递方式。程序把传入的值放入被称为栈的内存区域。计算机根据变量类型(不是根据转换说明)把这些值放入栈中。
因此,n1被存储在栈中,占8字节(float类型被转换成double类型)。同样,n2也在栈中占8字节,而n3和n3在栈中分别占8字节(在64为系统中)。
然后,控制转到printf()函数。该函数根据转移说明(不是根据变量类型)从栈中读取值。%ld转移说明表明printf()应该读取4字节,所以printf()读取栈中的前4字节作为第1个值,这是n1的前半部分。将被解释成一个long类型的整数。根据下一个%1d转移说明,printf()再读取4字节,这是n1的后半部份,将被解释成第2个long类型的整数。类似地,根据第3个和第4个%1d,printf()读取n2的前半部分和后半部分,并解释成两个long类型的整数。因此,对于n3和n4,虽然用对了转移说明,但printf()还是读错了字节。

4.5.4 使用scanf()
scanf()把输入的字符串转换成整数、浮点数、字符或字符串,而printf()正好与它相反,把整数、浮点数、字符和字符串转换成显示在屏幕上的文本。
scanf()和printf()类似,也使用格式字符串和参数列表。scanf()中的格式字符串表面字符输入流的目标数据类型。两个函数主要的区别在参数列表中。printf()函数使用变量、常数和表达式,而scanf()函数使用指向变量的指针。
getchar()读取每个字符,包括空格、制表符和换行符;而scanf()在读取数字时会跳过空格、制表符和换行符。
如果用scanf()读取基本变量类型的值,在变量名前加上一个&。
如果用scanf()把字符串读入字符数组中,不要使用&。
scanf()的转换说明
| 转移说明 | 含义 |
|---|---|
| %c | 把输入解释成字符 |
| %d | 把输入解释成有符号十进制整数 |
| %e、%f、%g、%a | 把输入解释成浮点数 |
| %E、%F、%G、%A | 把输入解释成浮点数 |
| %o | 把输入解释成有符号八进制整数 |
| %p | 把输入解释成指针(地址) |
| %s | 把输入解释成字符串。从第1个非空白字符开始,到下一个空白字符之前的所有字符都是输入 |
| %u | 把输入解释成无符号十进制整数 |
| %x、%X | 把输入解释成有符号十六进制整数 |
所列的转移说明中(百分号和转移字符之间)使用修饰符。如果要使用多个修饰符,必须按下表所列的顺序书写。
| 转移说明 | 含义 |
|---|---|
| * | 抑制赋值。示例:“%*d” |
| 数字 | 最大字段宽度。输入达到最大字段宽度处,或第1次遇到空白字符时停止。示例:“%10s” |
| hh | 把整数作为signed char或unsigned char类型读取。示例:“%hhd”、“%hhu“ |
| ll | 把整数作为long long或unsigned long long类型读取。示例:”%lld“、”%llu“ |
| z | 在整数转换说明后面时,表明使用sizeof的返回值类型 |
| t | 在整型转换说明后面时,表面使用表示两个指针差值的类型。示例:”%td“、”%tx“ |
1.从scanf()角度看输入
假如scanf()根据一个%d转移说明读取一个整数。scanf()函数每次读取一个字符,跳过所有的空白字符,直至遇到第1个非空白字符才开始读取。因为要 读取整数,所以scanf()希望发现一个数字字符或者一个符号(+或-)。如果找到一个数字或符号,他便保存该字符,直至遇到非数字字符。如果遇到一个非数字字符,它便认为读到了整数的末尾。然后,scanf()把非数字字符放回输入。这意味着程序在下一次读取输入时,首先读到的是上一次读取丢失的非数字字符。最后,scanf()计算已读取数字(可能还是符号)相应的数值,并将计算后的值放入指定的变量中。
如果使用字段宽度,scanf()会在字段结尾或第1个空白字符处停止读取。
如果第1个非空白字符是A而不是数字,会发生什么情况?scanf()将停在那里,并把A放回输入中,不会把值赋给指定变量。程序在下一次读取输入时,首先读到的字符是A。如果程序只使用%d转移说明,scanf()就一直无法超越A读下一个字符。另外,如果使用带多个转移说明的scanf(),C规定在第1个出错处停止读取输入。
用其他数值匹配的转移说明读取输入和用%d的情况相同。区别在于scanf()会把更多字符识别成数字的一部分。例如,%x转义字符要求scanf()识别十六进制数a-f和A-F。浮点数转换说明要求scanf()识别小数点、e记数法(指数记数法)和新增的p记数法(十六进制指数记数法)。
如果使用%s转移说明,scanf()会读取除空白以外的所有字符。scanf()跳过空白开始读取第1个非空白字符,并保存非空白字符直到再次遇到空白。这意味着scanf()根据%s转换说明读取一个单词,即不包含空白字符的字符串。如果使用字段宽度,scanf()在字段末尾或第1个空白字符处停止读取。无法利用字段宽度让只有一个%s的scanf()读取多个单词。最后要注意一点:当scanf()把字符串放进指定数组中时,它会在字符序列的末尾加上’\0’,让数组中的内容成为一个C字符串。
实际上,在C语言中scanf()并不是最常用的输入函数。这里重点介绍它是因为它能读取不同类型的数据。C语言还有其他的输入函数,如getchar()和fgets()。这这两个函数更适合处理一些特殊情况,如读取单个字符或包含空格的字符串,后面的章节中讨论这些函数。目前,无论程序中需要读取整数、小数、字符还是字符串,都可以使用scanf()函数。
2. 格式字符串中的普通字符
scanf()函数允许把普通字符放在格式字符串中。除空格字符外的普通字符必须与输入字符串严格匹配。例如,假设在两个转移说明中添加一个逗号:
scanf(“%d,%d”,&n,&m);
scanf()函数将其解释成:用户将输入一个数字、一个逗号,然后再输入一个数字。也就是说,用户必须像下面这样输入两个整数:
88,121
由于格式字符串中,%d后面紧跟逗号,所以必须在输入88后再输入一个逗号。但是,由于scanf()会跳过整数前面的空白,所以下面两种输入方式都可以:
88, 121
和
88,
121
格式字符串中的空白意味着跳过下一个输入项前面的所有空白。
除了%c,其他转换说明都会自动跳过待输入值前面所有的空白。因此,scanf(“%d%d”,&n,&m)与scanf(“%d %d”,&n,&m)的行为相同。对于%c,在格式字符串中添加一个空格字符会有所不同。例如,如果把%c放在格式字符串中的空格前面,scanf()便会跳过空格,从第1个非空白字符开始读取。也就是说,scanf(“%c”,&ch)从输入中的第1个字符开始读取,而scanf(" %c",&ch)则从第1个非空白字符开始读取。
3. scanf()的返回值
scanf()函数返回成功读取的项数。如果没有读取任何项,且需要读取一个数字而用户却输入一个非数值字符串,scanf()便返回0。当scanf()检测到“文件结尾”时,会返回EOF(EOF是stdio.h中定义的特殊值,通常用#define指令把EOF定义为-1)。
4.4.5 printf()和scanf()的*修饰符
printf()和scanf()都可以使用*修饰符来修改转换说明的含义。但是,它们的用法不太一样。首先,我们来看printf()的*修饰符。
如果你不想预先指定字段宽度,希望通过程序来指定,那么可以用*修饰符代替字段宽度。但还是要用一个参数告诉函数,字段宽度应该是多少。也就是说,如果转换说明是%*d,那么参数列表中应包含*和d对应的值。这个技巧也可用于浮点值指定精度和字段宽度。
#include <stdio.h>
int main()
{
unsigned width ,precision;
int number = 256;
double weight = 242.5;
printf("Enter a field width:\n");
scanf("%d",&width);
printf("The number is :&*d:\n",width,number);
printf("Now enter a width and a precision:\n");
scanf("%d %d",&width,&precision);
printf("weight=%*.*f\n",width,precision,weight);
printf("Done!\n");
}
变量width提供字段宽度,number是待打印的数字。因为转移说明中*在d的前面,所以在printf()的参数列表中,width在number的前面。同样,width和precision提供打印weight的格式化信息。
下面是一个运行实例:

scanf()中的*用法与此不同。把*放在%和转移字符之间时,会使得scanf()跳过相应的输出项。下面举一个例子:
#include <stdio.h>
int main()
{
int n;
printf("Please enter three integers:\n");
scanf("%*d %*d %d",&n);
printf("The last integer was %d\n",n);
return 0;
}
上述程序的scanf()提示:跳过两个整数,把第3个整数拷贝给n,下面是一个运行实例:

4.6getchar()和putchar()\color{blue}{4.6 getchar()和putchar()}4.6getchar()和putchar()
使用scanf()和printf()根据%c转移说明读取字符,用下面介绍的一对字符输入\输出函数:getchar()和putchar()也可以读取字符。
getchar()函数不带任何参数,它从输入队列中返回下一个字符。例如,下面的语句读取下一个字符输入,并把该字符的值赋值给变量ch;
ch = getchar();
该语句与下面的语句效果相同:
scanf(“%c”, &ch);
putchar()函数打印它的参数。例如,下面的语句把之前赋给ch的值作为字符打印出来:
putchar(ch);
给语句与下面的语句效果相同:
printf(“%c” ch);
由于这些函数只处理字符,所以它们比更通用的scanf()和printf()函数更快、更简洁。而且,注意getchar()和putchar()不需要转换说明,因为它们只处理字符。这两个函数通常定义在stdio.h头文件中(而且,它们通常是预处理宏,而不是真正的函数)
下面编写一个程序来说明这两个函数是如何工作的。该函数把一行输入重新打印出来,但是每个非空格都被替换成原字符在ASCII序列中的下一个字符,空格不变。这一过程可描述为“如果字符是空白,原样打印;否则,打印原字符在ASCII序列中的下一个字符”。
//cypher1.c -- 更改输入,空格不变
#include<stdio.h>
#define SPACE ''
int main()
{
char ch;
ch = getchar(); //读取一个字符
while (ch != '\n') //当一行末结束时
{
if (ch == SPACE) //留下空格
putchar(ch); //该字符不变
else
putchar(ch + 1); //改变其他字符
ch = getchar(); //获取下一个字符
}
putchar(ch); //打印换行符
return
}
第五章运算符、表达式和语句\color{red}{第五章 运算符、表达式和语句}第五章运算符、表达式和语句
| 赋值运算符 | |
|---|---|
| = | 将其右侧的值赋给左侧的变量 |
| 算术运算符: | |
|---|---|
| + | 将其左侧的值与右侧的值相加 |
| - | 将其左侧的值减去右侧的值 |
| - | 作为一元运算符,改变其右侧值的符号 |
| * | 将其左侧的值乘以右侧的值 |
| / | 将其左侧的值除以右侧的值,如果两数都是整数,计算结果将被截断 |
| % | 当其左侧的值除以右侧的值时,取其余数(只能应用于整数) |
| ++ | 对其右侧的值加1(前缀模式),或对其左侧的值加1(后缀模式) |
| – | 对其右侧的值减1(前缀模式),或对其左侧的值减1(后缀模式) |
| 关系运算符 | 每个关系运算符都把它左侧的值和右侧的值进行比较 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| == | 等于 |
| >= | 大于或等于 |
| > | 大于 |
| != | 不等于 |
| 赋值运算符 | |
|---|---|
| += | 把右侧的值加到左侧的变量上 |
| -= | 从左侧的变量中减去右侧的值 |
| *= | 把左侧的变量乘以右侧的值 |
| /= | 把左侧的变量除以右侧的值 |
| %= | 左侧变量除以右侧值得到的余数 |
| 逻辑运算符 | |
|---|---|
| && | 与 |
| ||或 | |
| ! | 非 |
| 条件运算符:?: | |
|---|---|
| x=(y<0)?-y:y | 该语句的意思是“如果y小于0,那么x=-y;否则,x=y” |
| 其他运算符 | |
|---|---|
| sizeof | 获得其右侧运算符对象的大小(以字节为单位),运算对象可以是一个被圆括号括起来的类型说明符,如sizeof(float),或者是一个具体的变量名、数组名等,如sizeof foo |
| (类型名) | 强制类型转换运算符将其右侧的值转移成圆括号中指定的类型,如(float)9 把整数9转换成浮点数9.0 |
| 逗号运算符 | 逗号运算符把两个表达式连接成一个表达式,并保存最左边的表达式最先求值,逗号运算符通常在for循环头的表达式中用于包含更多的信息,整个逗号表达式的值是逗号右侧表达式的值。 |
第六章C控制语句:循环\color{red}{第六章 C控制语句:循环}第六章C控制语句:循环
6.1while语句\color{blue}{6.1 while语句}6.1while语句
while语句创建了一个循环,重复执行直到测试表达式为假或0,while语句是一种入口条件循环,也就是说,在执行多次循环之前已决定是否执行循环,因此,循环有可能不被执行。循环体可以是简单语句,也可以是复合语句。
6.2for语句\color{blue}{6.2 for语句}6.2for语句
for语句使用3个表达式控制循环过程,分别用分号隔开, initialize表达式在执行for语句之间只执行一次;然后对test表达式求值,如果表达式为真(或非零),执行循环一次;接着对update表达式求值,并再次检查test表达式。for语句是一种入口条件循环,即在执行循环之前就决定了是否执行循环。因此,for修环可能一次都不能执行。statement部分可以是一条简单语句或复合语句。
形式:
for(initialize;test;update)
statement
在test为假或0之前,重复执行statement部分。
6.3dowhile语句\color{blue}{6.3 do while语句}6.3dowhile语句
do while语句创建一个循环,在expression为假或0之前重复执行循环体中的内容。do while 语句是一种出口条件循环,即在执行完循环体后才根据测试条件决定是否再次执行循环。因此,该循环至少必须执行一次。statement部分可是一条简单语句或复合语句。
形式:
do
statement
while(expression);
在test为假或0之前,重复执行statement部分。
6.4循环辅助:continue和break\color{blue}{6.4 循环辅助:continue和break}6.4循环辅助:continue和break
一般而言,程序进入循环后,在下一次循环测试之前会执行完循环体中的所有语句。continue和break语句可以根据循环体中的测试结果来忽略一部分循环内容,甚至结束循环。
3种循环都可以使用continue语句。执行到该语句时,会跳过本次迭代的剩余部分,并开始下一轮迭代。如果continue语句在嵌套循环内,则只会影响包含该语句的内层循环。
程序执行到循环种的break语句时,会终止包含它的循环,并继续执行下一阶段。
第7章C控制语句:分支和跳跃\color{red}{第7章 C控制语句:分支和跳跃}第7章C控制语句:分支和跳跃
7.1if、else\color{blue}{7.1 if、else }7.1if、else
下面各形式中,statement可以是一条简单语句或复合语句。表达式为真说明其值是非零值。
形式1:
if(expression)
statement
如果expression为真,则执行statement部分。
形式2:
if(expression)
statement1
else
statement2
如果expression为真,执行statement1部分;否则,执行statement2部分。
形式3:
if(expression1)
statement1
else if(expression2)
statement2
else
statement3
如果expression1为真,执行statement1部分;如果expression2为真,执行statement2部分;否则,执行statement3部分。
从技术角度看,if else语句作为一条单独的语句,不必使用花括号。外层if也是一条单独的语句,也不必使用花括号。但是,当语句太长时,使用花括号能提高大妈的可读性,而且还可防止今后在if循环中添加其他语句时忘记加花括号。
7.2多重选择:switch和break\color{blue}{7.2 多重选择:switch 和 break }7.2多重选择:switch和break
使用条件运算符和if else语句很容易编写二选一的程序。然而,有些程序需要在多个选项中进行选择。可以用if else if…else来完成。但是,大多数情况下使用switch语句更方便。
形式:
switch(expression)
{
case label1 : statement1 //使用break跳出switch
case label2 : statement2
default : statement3
}
可以有多个标签语句、default语句可选择。
程序根据exression的值跳转至对应的case标签处,然后,执行剩下的所有语句,除非执行到break语句进行重定向。expression和case标签都必须是整数值(包含char类型),标签必须是常量或完全由常数组成的表达式。如果没有case标签与expression的值匹配,控制则转至标有default的语句(如果有的话);否则,将转至执行紧跟在switch语句后面的语句。
7.2.1 switch和 if else
何时使用switch?何时使用if else?你经常会别无选择。如果是根据浮点类型的变量或表达式来选择,就无法使用switch.如果根据变量在某范围内决定程序流的去向,使用switch就很麻烦,这种情况用if就很方便:
if (integer < 1000 && integer > 2)
使用switch要覆盖以上范围,需要为每个整数(3-999)设置case标签。但是使用switch,程序通常运行快一些,生成的代码小一些。
第八章字符输入/输出和输入验证\color{red}{ 第八章 字符输入/输出和输入验证}第八章字符输入/输出和输入验证
8.1单字符I/O:getchar()和putchar()\color{blue}{8.1 单字符I/O:getchar()和putchar()}8.1单字符I/O:getchar()和putchar()
第7章中提到过,getchar()和putchar()每次只处理一个字符。可能认为这种方法实在太笨拙了,毕竟与我们的阅读方式相差甚远。但是,这种方法很适合计算机。而且,这是绝大多数文本(即,普通文字)处理程序的核心方法。为了帮助读者回忆这些函数的工作方式,请看程序下面程序,该程序获取从键盘输入的字符,并把这些字符发送到屏幕上。程序使用while循环,当读到#字符时停止。
#include<stdio.h>
int main()
{
char ch;
while((ch=getchar())!='#')
putchar(ch);
return 0;
}
自从ANS C标准发布以后,C就把stdio.h头文件与使用getchar()和putchar()相关联,这就是为什么程序中要包含这个头文件的原因(其实,getchar()和putchar()都不是真正的函数,它们被定义为供预处理器使用的宏,在第16章中在详细讨论)
8.2缓冲区\color{blue}{8.2 缓冲区}8.2缓冲区
如果在老式系统运行8.1的程序,你输入文本时可能显示如下:

以上行为是个例外。像这样回显用户输入的字符后立即重复打印该字符是属于无缓冲(或直接)输入,即正在等待的程序可立即使用输入的字符。对于该例,大部分系统在用户按下Enter键之前不会重复打印刚输入的字符,这种输入形式属于缓冲输入。用户输入的字符被收集并储存在一个被称为缓冲区(buffer)的临时存储区,按下Enter键后,程序才可使用用户输入的字符。下面图比较了两种输入。
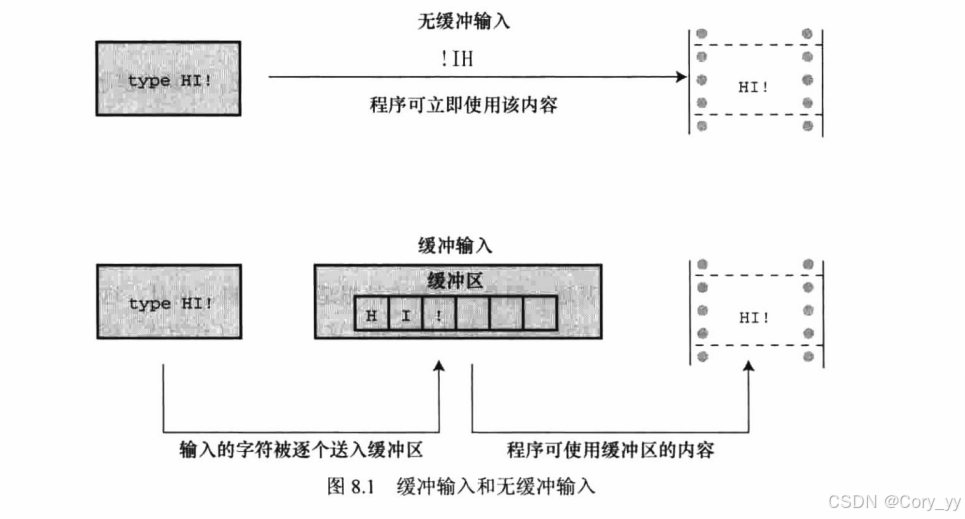
为什么要有缓冲区?首先,把若干字符作为一个块进行传输比逐个发送这些字符节约时间。其次,如果用户打错字符,可以直接通过键盘修正错误。当最后按下Enter键时,传输的是正确的输入。
虽然缓冲输入好处很多,但是某些交互程序也需要无缓冲输入。例如,在游戏中,你希望按下一个键就执行相应的指令。因此,缓冲输入和无缓冲输入都有用武之地。
缓冲分为两类:完全缓冲I/O和行缓冲I/O。完全缓冲输入指的是当缓冲区被填满时才刷新缓冲区(内容被发送至目的地),通常出现在文件输入中。缓冲区的大小取决于系统,常见的大小是512字节和4096字节。行缓冲I/O指的是在出现换行符时刷新缓冲区。键盘输入通常是行缓冲输入,所以在按下Enter键后才刷新缓冲区。
8.3结束键盘输入\color{blue}{8.3 结束键盘输入}8.3结束键盘输入
在8.1中的程序中,只要输入的字符中不含#,那么程序在读到#时才会结束。但是#也是一个普通的字符,有时不可避免要用到。应该用一个在文本中用不到的字符来标记输入完成,这样的字符不会无意间出现在输入中,在你不希望结束程序的时候终止程序。C的确提供了这样的字符,不过在此之前,先来了解一下C处理文件的方式。
8.3.1 文件、流和键盘输入
文件(file)是存储器中储存信息的区域。通常,文件都保存在某种永久存储器中(如,键盘、U盘或DVD等)。毫无疑问,文件对于计算机系统相对重要。
不同的系统储存文件的方式不同。有些系统把文件的内容存储在一处,而文件相关的信息储存在另一处;有些系统在文件中创建一份文件描述。在处理文件方面,有些系统使用单个换行符标记行末尾,而其他系统可能使用回车符和换行符的组合来表示行末尾。有些系统用最小字节来衡量文件的大小,有些系统则以字节块的大小来衡量。
如果使用标准I/O包,就不用考虑这些差异。因此,可以用if (ch == ‘\n’)检查换行符。即使系统实际用的是回车符和换行符的组合来标记行末尾,I/O函数会在两种表示法之间相互转换。
从概念上看,C程序处理的是流而不是直接处理文件。流(stream)是一个实际输入或输出映射的理想化数据流。这意味着不同属性的不同种类的输入,由属性更统一的流来表示。于是,打开文件的过程就是把流与文件相关联,而且读写都通过流来完成。
8.3.2 文件结尾
计算机操作系统要以某种方式判断文件的开始和结束。检测文件结尾的一种方法是,在文件末尾放一个特殊的字符标记文件结尾。如今,这些操作系统可以使用内嵌的Ctrl+Z字符来标记文件结尾。这曾静是操作系统使用的唯一标记,不过现在有一些其他的选择,例如记录文件的大小。所以现代的文本文件不一定有嵌入的Ctrl+Z,但是如果有,该操作系统会将其视为一个文件结尾标记。下图演示了这种方法。

操作系统使用的另一种方法是储存文件大小的信息。如果文件有3000字节,程序在读到3000字节时便达到文件的末尾。MS-DOS及其相关系统使用这种方法处理二进制文件,因为用这种方法可以在文件中储存所有的字符,包括Ctrl+Z。新版的DOS也使用这种方法处理文本文件。UNIX使用这种方法处理所有的文件。
无论是操作系统实际使用何种方法检测文件结尾,在C语言中,用getchar()读取文件检测到文件结尾时将返回一个特殊的值,即EOF (end of file的缩写)。scanf()函数检测到文件结尾时也返回EOF。通常,EOF定义在stdio.h文件中:
#define EOF (-1)
为什么是-1?因为getchar()函数的返回值通常都介于0-127,这些值对应标准字符集。但是,如果系统能识别扩展字符集,该函数的返回值可能在0-255之间。无论哪种情况,-1都不对应任何字符,所以,该值用于标记文件结尾。
那么如何在程序中使用EOF?把getchar()的返回值和EOF作比较。如果两值不同,就说明没有到达文件结尾。也就是说,可以使用下面这样的表达式:
while (( ch = getchar() ) != EOF)
如果正在读取的是键盘输入不是文件会怎样?绝大部分系统(不是全部)都有办法通过键盘模拟文件结尾条件。了解这些以后,可以重写程序清单8.1的程序,如程序清单8.2所示。
程序清单8.2
#include<stdio.h>
int main()
{
int ch;
while (( ch = getchar()) != EOF)
putchar(ch);
return 0;
}
注意下面几点:
- 不用定义EOF,因为stdio.h中已经定义过了。
- 不用担心EOF的实际值,因为EOF在stdio.h中#define预处理指令定义,可直接使用,不必再编写代码假定EOF为某值。
- 变量ch的类型从char变为int,因为char类型的变量只能表示0-255的无符号整数,但是EOF的值是-1.
- 由于getchar()函数的返回类型是int,如果把getchar()的返回值赋给char类型的变量,一些编译器会警告可能丢失数据。
- ch是整数不会影响putchar(), 该函数仍然会打印等价的字符。
- 使用给程序进行键盘输入,要设法输入EOF字符。不能只输入字符EOF,也不能只输入-1(输入-1会传送两个字符:一个连字符和一个数字1)。正确的方法是,必须找出当前系统的要求。例如,在大多数UNIX和Linux系统中,在一行开始处按下Ctrl+D会传输文件结尾信号。
8.4重定向和文件\color{blue}{8.4 重定向和文件}8.4重定向和文件
程序可以通过两种方式使用文件。第一种方法是,显示使用特定的函数打开文件、关闭文件、读取文件、写入文件,诸如此类。在第13章中在详细介绍这种方法。第2种方法是,设计能与键盘和屏幕互动的程序,通过不同的渠道重定向输入至文件和从文件输出。换言之,把stdin流重新赋给文件。继续使用getchar()函数从输入流中获取数据,但它并不关心从流的什么位置获取数据。
重定向的一个主要问题与操作系统有关,与C无关。
8.4.1 UNIX、Linux和DOS重定向
UNIX(运行命令行模式时)、Linux(ditto)和window命令行提示(模仿旧式DOS命令行环境)都能重定向输入、输出。重定向输入让程序使用文件而不是键盘来输入,重定向输出让程序输出至文件而不是屏幕。
1.重定向输入
假设已经编译了echo_eof.c程序,并把可执行版本放入一个名为echo_eof(或者在Windows系统中名为echo_eof.exe)的文件中。运行该程序,输入可执行文件名:
echo_eof
该程序的运行情况和前面描述的一样,获取用户从键盘输入的输入。现在,假设你要用该程序处理名为words的文本文件。文件的内容可以是一篇散文或者C程序。内含机器语言指令的文件(如储存可执行程序的文件)不是文本文件。由于程序的操作对象是字符,所以要使用文本文件。只需要下面的命令代替上面的命令即可:
echo_eof < words
<符号是UNIX和DOS/Windows的重定向运算符。该运算符使words文件与stdin流相关联,把文件中的内容导入echo_eof程序。

2.重定向输出
现在假设要用echo_eof把键盘输入的内容发送到名为mywords的文件中。然后,输入以下命名并开始输入:
echo_eof > mywords
>符号是第2个重定向运算符。它创建了一个名为mywords的新文件,然后把echo_eof的输出(即,你输入字符的副本)重定向至该文件中。重定向把stdout从显示设备(即,显示器)赋给mywords文件。如果已经有一个名为mywords文件,通常会擦除该文件的内容,然后替换新的内容。所有出现在屏幕的字母都是你刚才输入的,其副本储存在文件中。在下一行的开始处按下Ctrl+D(UNIX)或Ctrl+Z(DOS)即可结束该程序。如果不知道输入什么内容,可参考下面的示例。这里我们使用UNIX提示符$,记住在每行的末尾单机Enter键,这样才能把缓冲区的内容发送给程序。

3.组合重定向
现在,假设你希望制作一份mywords文件的副本,并命名为savewords。只需输入以下命令即可:
echo_eof < mywords > savewords
下面的命令也起作用,因为命令与重定向运算符的顺序无关:
echo_eof > savewords < mywords
注意:在一条命令中,输入文件名和输出文件名不能相同。
echo_eof < mywords > mywords <—错误
原因是> mywords在输入之前已导致原mywords的长度被截断为0.
总之,在UNIX、Liunx或Windows/DOS系统中使用两个重定向运算符(<和>)时,要遵循以下原则:
- 重定向运算符连接一个可执行程序(包含标准操作系统命令)和一个数据文件,不能用于连接一个数据文件和另一个数据文件,也不能用于连接一个程序和另一个程序。
- 使用重定向运算符不能读取多个文件的输入,也不能把输出定向至多个文件。
- 通常,文件名和运算符之间的空格不是必须的,除非是偶尔在UNIX shell、Linux shell或Windows命令行提示模式中使用的有特殊含义的字符。
UNIX、Linux或Windows/DOS还有>>运算符,该运算符可以把数据添加到现有文件的末尾,而 | 运算符能把一个文件的输出连接到另一个文件的输入。欲了解所有相关运算符的内容,请参阅UNIX的相关书籍。
8.5创建更友好的用户界面\color{blue}{8.5 创建更友好的用户界面}8.5创建更友好的用户界面
8.5.1 使用缓冲输入
缓冲输入用起来比较方便,因为在把输入发送给程序之前,用户可以编辑输入。但是,在使用输入的字符时,它也会给程序员带来麻烦。前面示例中看到的问题是,缓冲输入要求用户按下Enter键发送输入。这一动作也传送了换行符,程序必须妥善处理这个麻烦的换行符。我们以一个猜谜程序为例。用户选择一个数字,程序猜用户选中的数字是多少。该程序使用的方法单调乏味,先不要在意算法,我们关注的重点在输入和输出。查看程序清单8.4,这是猜谜程序的最初版本,后面我们会改进。
程序清单8.4
#include<stdio.h>
int main()
{
int guess = 1;
printf("Pick an integer from 1 to 100, I will try to guess");
printf("it.\nRespond with a Y if my guess is right and with");
printf("\nan n if is wrong.\n");
printf("Uh...is your number %d?\n",guess);
while(getchar() != 'y') // 获取响应,与y做对比
printf("Well,then, is it %d?\n",++guess);
printf("I knew I could do it!\n");
return 0;
}
下面是程序的运行示例:

撇开这个程序糟糕的算法不谈,我们先选择一个数字。注意,每次输入n时,程序打印了两条消息。这是由于程序读取n作为用户否定了数字1,然后还读取了一个换行符作为用户否定了数字2。
一种解决方案是,使用while循环丢弃输入行最后剩余的内容,包含换行符。这种方法的优点是,能把no和no way 这样的响应视为简单的n。程序清单8.4的版本会把no当作两个响应。下面用循环修正这个问题:

这的确是解决了换行符的问题。但是,该程序还是会把f被视为n。我们用if语句筛选其他响应。首先,添加一个char类型的变量存储存响应:
char response;
修改后的循环如下:

在编写交互式程序时,应该事先预料到用户可能会输入错误,然后设计程序处理用户的错误输入。在用户出错时通知用户再次输入。
8.5.2 混合数值和字符输入
假设程序要求用getchar()处理字符输入,用scanf()处理数值输入,这两个函数都能很好地完成任务,但是不能把它们混用。因为getchar()读取每个字符,包括空格、制表符和换行符;而scanf()在读取数字时会跳过空格、制表符和换行符。
我们通过程序清单8.5来解释这种情况导致的问题。该程序读入一个字符和两个数字,然后根据输入的两个数字指定的行数和列数打印该字符。
程序清单 8.5
/* 有较大I/O问题的程序*/
#include<stdio.h>
void display(char cr, int lines, int width);
int main()
{
int ch; //待打印字符
int rows, cols; //行数和列数
printf("Enter a character and two integers:\n");
while((ch = getchar()) != '\n')
{
scanf("%d %d",&rows, &cols);
display(ch, rows, cols);
printf("Enter another character and two integers;\n");
printf("Enter a newline to quit.\n");
}
printf("Bye.\n");
return 0;
}
void display(char cr, int lines, int width)
{
int row, col;
for(row = 1; row <= lines; row++)
{
for(col = 1; col <= width; col++)
putchar(cr);
putchar('\n'); //结束一行并开始新的一行
}
}
注意,该程序以int类型读取字符(这样做可以检测EOF),但是却以char类型把字符传递给display()函数。因为char比int小,一些编译器会给出类型转换的警告。可以忽略这些警告,或者用下面的强制类型转换消除警告:
display(char(ch), rows, cols);
在程序中,main()负责获取数据,display()函数负责打印数据。下面是该程序的一个运行实例,看看有什么问题:

该程序开始时运行良好。你输入c 2 3 ,程序打印c字符2行3列。然后,程序提示输入第2组数据,还没等你输入数据程序退出了!这是什么情况?又是换行符在捣乱,这次是输入行中紧跟在3后面的换行符。scanf()函数把这个换行符留在输入队列中。和scanf()不同,getchar()不会跳过换行符,所以在进入下一轮迭代时,你还没来得及输入字符,它就读取了换行符,然后将其赋给ch。而ch是换行符正式终止循环的条件。
要解决这个问题,程序要跳过一轮输入结束与下一轮输入开始之间的所有换行符或空格。另外,如果该程序不在getchar()测试时,而在scanf()阶段终止程序会更好。修改后的版本如程序清单8.6所示。
程序清单8.6 showchar2.c程序
//按指定的行列打印字符
#include<stdio.h>
void display(char cr, int lines, int width);
int main(void)
{
int ch; //待打印字符
int rows,cols; //行数和列数
printf("Enter a character and two integers:\n");
while((ch=getchar())!='\n')
{
if(scanf("%d %d",&rows,&cols) != 2)
break;
display(ch, rows, cols);
while(getchar() != '\n')
continue;
printf("Enter another character and two integers;\n");
printf("Enter a newline to quit.\n");
}
printf("Bye.\n")
return 0;
}
void display(char cr, int lines, int width)
{
int row, col;
for(row = 1; row <= lines; row++)
{
for(col = 1;col <= width; col++)
putchar(cr);
putchar('\n'); //结束一行并开始新的一行
}
}
while循环实现了丢弃scanf()输入后面所有字符(包括换行符)的功能,为循环的下一轮读取做好了准备。该程序的运行示例如下:

在if语句中使用一个break语句,可以在scanf()的返回值不等于2时终止程序,即如果一个或两个输入值不是整数或者遇到文件结尾就终止程序。
8.6 输入验证
在实际应用中,用户不一定会按照程序的指令行事。用户的输入和程序期望的输入不匹配时常发生,这会导致程序运行失败。作为程序员,除了完成编程的本职工作,还要事先预料一些可能的输入错误,这样才能编写出能检测并处理这些问题的程序。
例如,假如你编写了一个处理非负数整数的循环,但是用户很可能输入一个负数。你可以使用关系表达式来排除这种情况:
long n;
scanf(“%ld”, &n); //获取第1个值
while (n >= 0) //检测不在范围内的值
{
//处理n
scanf(“%ld”, &n); //获取下一个值
}
另一类潜在的陷阱是,用户可能输入错误类型的值,如字符q。排除这种情况的一种方法是,检查scanf()的返回值。回忆一下,scanf()返回成功读取项的个数。因此,下面的表达式当且仅当用户输入一个整数时才为真:
scanf(“%ld”, &n) == 1
结合上面的while循环,可改进为:
long n;
while(scanf(“%ld”, &n) == 1 && n >= 0)
{
处理n
}
while循环条件可以描述为“当输入是一个整数且该整数为正时”。
对于最后的例子,当用户输入错误类型的值时,程序结束。然后,也可以让程序友好些,提示用户再次输入正确类型的值。在这种情况下,要处理有问题的输入。如果scanf()没有成功读取,就会将其留在输入队列中。这里要明确,输入实际上是字符流。可以使用getchar()函数逐字符地读取输入,甚至可以把这些想法都结合在一个函数中,如下所示:
long get_long(void)
{
long input;
char ch;
while(scanf(“%ld”, &input) != 1)
{
while((ch = getchar()) != ‘\n’)
putchar(ch); //处理错误的输入
printf(" is not an integer.\nPlease enter an ");
printf("integer value, such as 25, -178, or 3: ");
}
return input;
}
该函数把一个int类型的值读入变量input中。如果读取失败,函数则进入外层while循环体。然后内层循环逐字符地读取错误的输入。注意,该函数丢失该输入行的所有剩余内容。还有一个方法是,只丢失下一个字符或单词,然后该函数提示用户再次输入。然后该函数提示用户再次输入。外层循环重复运行,直到用户成功输入整数,此时scanf()的返回值为1.
在用户输入整数后,程序可以检查该值是否有效。考虑一个例子,要求用户输入一个上限和一个下限来定义值的范围。在该例中,你可能希望程序检查第1个值是否大于第2个值(通常假设第1个值是较小的那个值),除此之外还要检查这些值是否在允许的范围内。例如,当前的档案查找一般不会接受1958年以前和2014年以后的查询任务。这个限制可以在一个函数中实现。
假设程序中包含了stdbool.h头文件。如果当前系统不允许使用_Bool,把bool替换成int,把true替换成1,把false替换成0即可。注意,如果输入无效,该函数返回true,所以函数名为bad_limits():
bool bad_limits(long begin, long end, long low, long high)
{
bool not_good = false;
if(begin > end)
{
printf(“%1d isn’t smaller than %1d.\n”, begin, end);
not_good = true;
}
if(begin < low || end < low)
{
printf(“Values must be %1d or greater.\n”, low);
not_good = true;
}
if(begin > high || end > high)
{
printf(“Values must be %1d or less.\n”, high);
not_good = true;
}
return not_good;
}
程序清单8.7使用了上面的两个函数为一个进行算术运算的函数提供整数,该函数计算特定范围内所有整数的平方和。程序限制了范围的上限是100000000,下限是-100000000。
程序清单8.7
#define _CRT_SECURE_NO_WARNINGS
//checking.c 输入验证
#include<stdio.h>
#include<stdbool.h>
//验证输入是一个整数
long get_long(void);
//验证范围的上下限是否有效
bool bad_limits(long begin, long end, long low, long high);
//计算a-b之间的整数平方和
double sum_squares(long a, long b);
int main()
{
const long MIN = -10000000L; //范围的下限
const long MAX = +10000000L; //范围的上限
long start; //用户指定的范围最小值
long stop; //用户指定的范围最大值
double answer;
printf("This program computes the sum of the squares of"
"integers in a range.\nThe lower bound should not "
"be less than -10000000 and\nthe upper bound "
"should not be more than +10000000.\nEnter the "
"limits (enter 0 for both limits to quit):\n"
"upper limit: ");
start = get_long();
printf("lower limit: ");
stop = get_long();
while (start != 0 || stop != 0)
{
if (bad_limits(start, stop, MIN, MAX))
printf("Please try again.\n");
else
{
answer = sum_squares(start, stop);
printf("The sum of the squares of the integers");
printf("from %d %d is %f\n",
start, stop, answer);
}
printf("Enter the limits (enter 0 for both limits to quit):\n");
printf("lower limit:");
start = get_long();
printf("upper limit: ");
stop = get_long();
}
printf("Done.\n");
return 0;
}
long get_long()
{
long input;
char ch;
while (scanf("%ld", &input) != 1)
{
while ((ch = getchar()) != '\n')
putchar(ch); //处理错误输入
printf(" is not an integer. \nPlease enter an ");
printf("integer value, such as 25, -178, or 3:");
}
return input;
}
double sum_squares(long a, long b)
{
double total = 0;
long i;
for (i = a; i <= b; i++)
total += (double)i * (double)i;
return total;
}
bool bad_limits(long begin, long end, long low, long high)
{
bool not_good = false;
if (begin > end)
{
printf("%d isn't smaller than %d.\n", begin, end);
not_good = true;
}
if (begin < low || end < low)
{
printf("Values must be %d or greater.\n", low);
not_good = true;
}
if (begin > high || end > high)
{
printf("Values must be %d of less.\n", high);
not_good = true;
}
return not_good;
}
8.6.1 分析程序
虽然checking.c程序的核心计算部分(sum_squares()函数)很短,但是输入验证部分比以往程序示例要复杂。接下来分析其中的一些要素,先着重讨论程序的整体结构。
程序遵循模板化的编程思想,使用独立函数(模块)来验证输入和管理显示。程序越大,使用模块化编程就越重要。
main()函数管理程序流,为其他函数委派任务。它使用get_long()获取值、while循环处理值、badlimits()函数检查值是否有效、sum_squres()函数处理实际的计算。
8.6.2 输入流和数字
在编写处理错误输入的代码时(如程序清单8.7),应该很清楚C是如何处理输入的。考虑下面的输入:
is 28 12.4
在我们眼中,这就像是一个由字符、整数和浮点数组成的字符串。但是对C语言而言,这是一个字节流。第1个字节是字母i的字符编码,第2个字节是字母s的字符编码,第3个字节是空格字符的字符编码,第4个字节是数字2的字符编码,等等。所以,如果get_long()函数处理这一行输入,第1个字符是非数字,那么整行输入都会被丢弃,包括其中的数字,因为这些数字只是该输入行中的其他字符:
while((ch = getchar()) != ‘\n’)
putchar(ch); //处理错误的输入
虽然输入流由字符组成,但是也可以设置scanf()函数把它们转换成数值。
简而言之,输入由字符组成,但是scanf()可以把输入转换成整数值或浮点数值。使用转换说明(如%d或%f)限制了可接受输入的字符类型,而getchar()和使用%c的scanf()接受所有的字符。
8.7 菜单浏览
许多计算机程序都把菜单作为用户界面的一部分。菜单给用户提供方便的同时,却给程序员带来了一些麻烦。我们看看其中涉及了哪些问题。
菜单给用户提供了一份响应程序的选择。假设有下面一个例子:
Enter the letter of your choice:
a. advice b. bell
c. count q. quit
理想状态是,用户输入程序所列选项之一,然后程序根据用户所选项完成任务。作为一名程序员,自然希望这一过程能顺利进行。因此,第1个目标是:当用户遵循指令时程序顺利运行;第2个目标是:当用户没有遵循指令时,程序也要顺利运行。显而易见,要实现第2个目标难度较大,因为很难预料用户在使用程序时的所有错误情况。
8.7.1 任务
我们来更具体地分析一个菜单程序需要执行哪些任务。它要获取用户的响应,根据响应选择要执行的动作。另外,程序应该提供返回菜单的选项。C的switch 语句是根据选项决定行为的好工具,用户的每个选项都可以对应一个特定的case标签。使用while语句可以实现重复访问菜单的功能。因此,我们写出以下伪代码:
获取选项
当选项不是‘q’时
转至响应的选项并执行
获取下一个选项
8.7.2 使执行更顺利
当你决定实现这个程序时,就要开始考虑如何让程序顺利运行(顺利运行指的是,处理正确输入和错误输入时都能顺利运行)。例如,你能做的是让“获取选项”部分的代码筛选掉不合适的响应,只把正确的响应传入switch。这表面需要为输入过程提供一个只返回正确响应的函数。结合while循环和switch语句。其程序结构如下:
#include<stdio.h>
char get_choice();
void count();
int main()
{
int choice;
while((choice = get_choice()) != 'q')
{
switch(choice)
{
case 'a':printf("Buy low, sell high.\n");
break;
case 'b':putchar('\a');
break;
case 'c':count();
break;
default:printf("Program error!\n");
break;
}
}
return 0;
}
定义get_choice()函数只能返回‘a’、‘b’、'c’和‘q’。get_choice()的用法和getchar()相同,两个函数都是获取一个值,并与终止值(该例中是‘q’)作比较。我们尽量简化实际的菜单选项,以便读者把注意力集中在程序结构上。稍后再讨论count()函数。default语句有助于发现问题所在。
get_choice()函数
下面的伪代码是设计这个函数的一种方案:
显示选项
获取用户的响应
当响应不合适时
提示用户再次输入
获取用户的响应
下面是一个简单而笨拙的实现:
char get_choice(void)
{
int ch;
printf("Enter the letter of your choice:\n");
printf("a. advice b. bell\n");
printf("c. count q. quit\n");
ch = getchar();
while((ch< 'a' || ch > 'c') && ch != 'q')
{
printf("Please respond with a, b, c, or q,\n");
ch=getchar();
}
return ch;
}
缓冲输入依旧带来些麻烦,程序把用户每次按下Return键产生的换行符视为错误响应。为了让程序的界面更顺畅,该函数应该跳过这些换行符。
这类问题有很多种解决方案。
这类问题有很多种解决方案。一种是用名为get_first()的新函数替换getchar()函数,读取一行的第1个字符并丢弃剩余的字符。这种方法的优点是,把类似act这样的输入视为简单的a,而不是继续把act中的c作为选项c的一个有效的响应。我们重写输入函数如下:
char get_choice(void)
{
int ch;
printf("Enter the letter of your choice:\n");
printf("a. advice b. bell\n");
printf("c. count q. quit\n");
ch = get_first();
while((ch < 'a' || ch > 'c') && ch != 'q')
{
printf("Please respond with a, b, c, or q.\n");
ch = getfirst();
}
return ch;
}
char get_first(void)
{
int ch;
ch = getchar(); //读取下一个字符
while(getchar() != '\n')
continue; //跳过该行剩下的内容
return ch;
}
8.7.3 混合字符和数值输入
前面分析混合字符和数值输入会产生一些问题,创建菜单也有这样的问题。例如,假设count()函数(选择c)的代码如下:
void count(void)
{
int n, i;
printf("Count how far? Enter an integer:\n");
scanf("%d",&n);
for(i = 1; i <= n; i++)
printf("%d\n", i);
}
如果输入3作为响应,scanf()会读取3并把换行符留在输入队列中。下次调用get_choice()将导致get_first()返回这个换行符,从而导致我们不希望出现的行为。
重写get_first(),使其返回下一个非空白字符而不仅仅是下一个字符,即可修复这个问题。另一种方法是,在count()函数中清理换行符,如下所示:
void count(void)
{
int n, i;
printf("Count how far? Enter an integer:\n");
n = get_int();
for (i = 1; i<= n; i++)
printf("%d\n", i);
while(getchar() != '\n')
continue;
}
该函数借鉴了程序清单8.7中的get_long()函数,将其改为get_int()获取int类型的数据而不是long类型的数据。回忆一下,原来的get_long函数如何检查有效输入和让用户重新输入。程序清单8.8演示了菜单程序的最终版本。
程序清单8.8 menuette.c程序
// menuette.c --菜单程序
#include<stdio.h>
char get_choice(void);
char get_first(void);
int get_int(void);
void count(void);
int main(void)
{
int choice;
void count(void);
while((choice=get_choice()) != 'q')
{
switch (choice)
{
case 'a': printf("Buy low, sell high.\n");
break;
case 'b': putchar('\a'); //ANSI
break;
case 'c': count();
break;
default: printf("Program error!\n");
break;
}
}
printf("Bye.\n");
return 0;
}
void count(void)
{
int n, i;
printf("Count how far? Enter an integer:\n");
n = get_int();
for (i = 1; i <= n; i++)
printf("%d\n",i);
while (getchar() != '\n')
continue;
}
char get_choice(void)
{
int ch;
printf("Enter the letter of your choice:\n");
printf("a. advice b. bell\n");
printf("c. count q. quit\n");
ch = get_first();
while((ch < 'a' || ch > 'c') && ch != 'q')
{
printf("Please respond with a, b, c, or q.\n");
ch = get_first();
}
return ch;
}
char get_first(void)
{
int ch;
ch = getchar();
while (getchar() != '\n')
continue;
return ch;
}
int get_int(void)
{
int input;
char ch;
while (scanf("%d", &input) != 1)
{
while((ch = getchar()) != '\n')
putchar(ch); //处理错误输出
printf(" is not an integer.\nPlease enter an ");
printf("integer value, such as 25, -178, or 3:");
}
return input;
}
要写出一个自己十分满意的菜单界面并不容易。但是,在开发了一种可行的方案后,可以在其他情况下复用这个菜单界面。
学完以上程序示例后,还要注意在处理复杂的任务时,如何让函数把任务委派给另一个函数。这样让程序更模块化。
8.8 关键概念
C程序把输入作为传入的字节流。getchar()函数把每个字符解释成一个字符编码。scanf()函数以同样的方式看待输入,但是根据转换说明,它可以把字符输入转换成数值。许多操作系统都提供重定向,允许用文件替换键盘输入,用文件代替显示器输出。
程序

















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









