




 本文介绍了如何使用Python爬虫从简书网站抓取文章标题、摘要和链接。首先分析了页面结构,利用XPath处理获取的XML文本。接着解决了动态加载的翻页问题,通过识别XHR请求URL实现多页爬取。此外,还讨论了应对网站访问限制的策略,包括设置请求头、使用代理IP和设置延迟请求。最后提供了完整的爬虫代码示例。
本文介绍了如何使用Python爬虫从简书网站抓取文章标题、摘要和链接。首先分析了页面结构,利用XPath处理获取的XML文本。接着解决了动态加载的翻页问题,通过识别XHR请求URL实现多页爬取。此外,还讨论了应对网站访问限制的策略,包括设置请求头、使用代理IP和设置延迟请求。最后提供了完整的爬虫代码示例。
这段时间在做的事情需要从网上获得一点资讯类似文章啊、电影啊、新闻啊等等,看了很久感觉用简书这个网址来做爬虫相对来说简单一点,可以不需要设置登录啥的就能够获取到内容,相比较起来已经很容易了。
(一)分析页面结构
我选择了一个简书的专题,就是固定的一个url,专题里面文章也比较多,如果需要多个专题,把专题链接复制下来写在一个数组里面让爬虫循环爬就可以。本次就举一个固定的url为例来写。
打开Chrome的开发者工具,就会出现页面的结构。(之前用火狐浏览器感觉也挺方便的)一层层打开可以找到显示文章的标签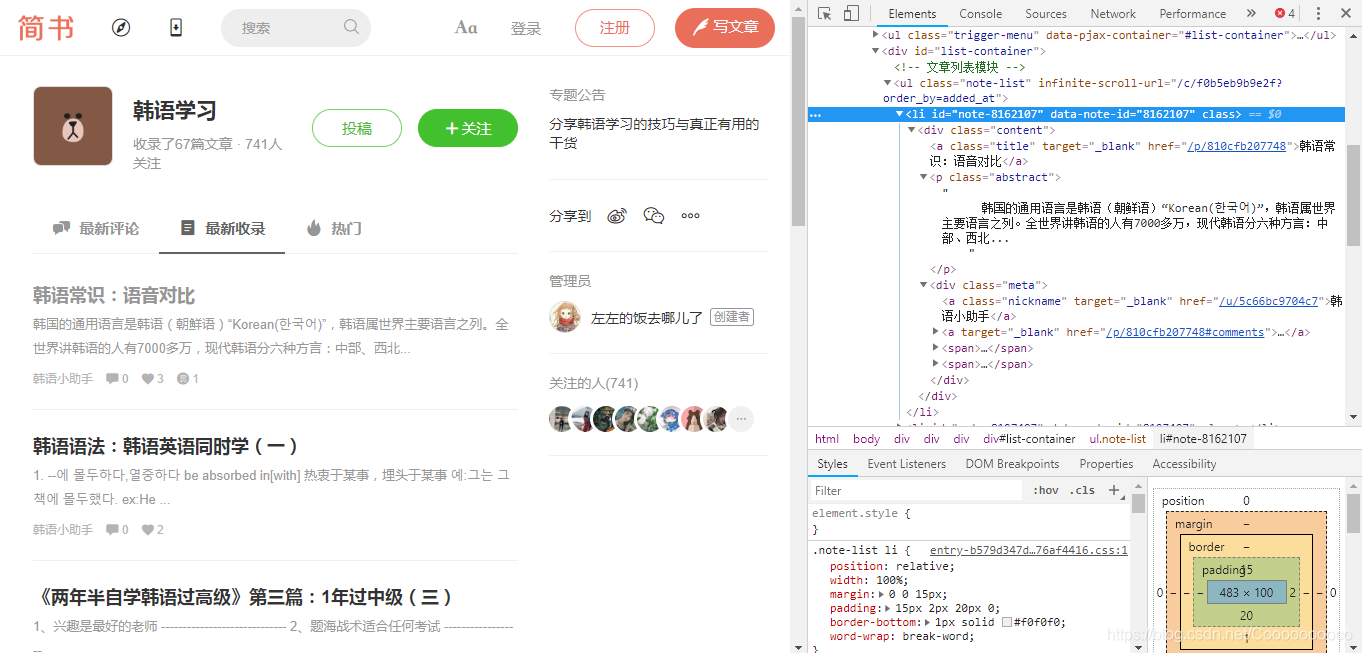
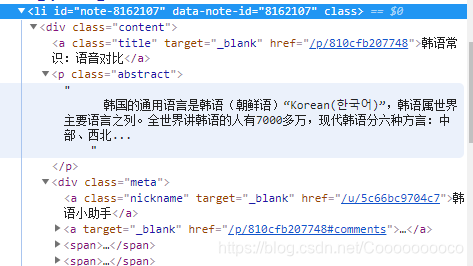
可以发现需要爬取的文章在<li>这个标签下,<a>标签为标题和链接,<p>为文章摘要,下面还有作者名字、点赞数等等,我主要需要获取标题、摘要以及文章链接即可。
(二)处理获取到的文本
爬虫爬下来的是整个页面的xml文本,需要找到我们所需要的东西还得经过处理才行,这里选择用xpath来处理,我觉得还挺好用的。
xpath相关语法可以参照这个:http://www.w3school.com.cn/xpath/xpath_syntax.asp
先设置各个路径如下:
#获取所有 li标签
xpath_items = '//ul[@class="note-list"]/li'
#对每个 li标签再提取
xpath_link = './div/a/@href'
xpath_title = './div/a[@class="title"]/text()'
xpath_abstract='./div/p/text()'
使用request的get方法获取页面,之后进行处理:
items1 = dom1.xpath(xpath_items)
for article in items1:
t = {}
t['link'] = 'https://www.jianshu.com'+article.xpath(xpath_link)[0]
t['title'] = article.xpath(xpath_title)[0]
t['abstract']=article.xpath(xpath_abstract)[0]
print(t)(三)解决页面自动翻页问题
第一次爬的时候只爬取到了第一页的文章,大概5、6?篇的样子,后来看了好久,也在网上搜了搜发现是属于Ajax动态加载(https://zhuanlan.zhihu.com/p/27346009),翻页时页面url不变。此时需要打开Chrome的Network,这种技术的文档属于XHR文件,打开后可以看到一个新的request url,其中添加了order_by =added_at 和page=2,方法还是get方法。往下继续翻可以看到只是page在改变,这样的网站简直简单多了。٩꒰▽ ꒱۶⁼³₌₃
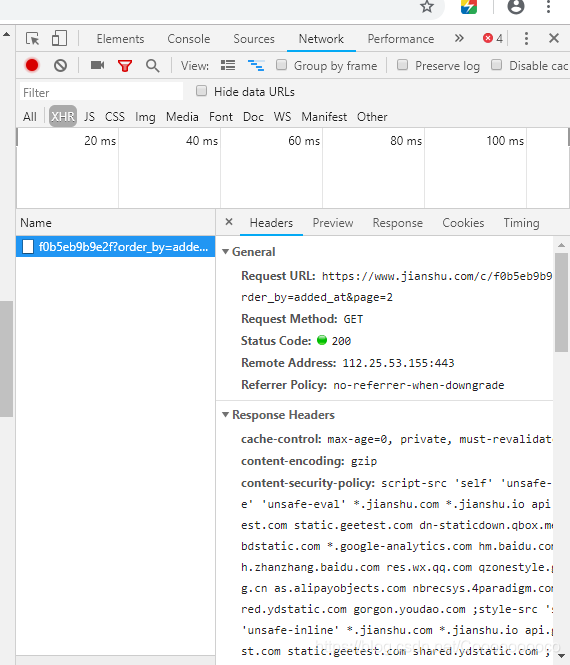
那么可以设置一个循环来实现页面的增加
a='added_at'
count=1
#获取和解析网页
while count<5:
r1 = requests.get('https://www.jianshu.com/c/f0b5eb9b9e2f?order_by={}&page={}'.format(a,count))
print('https://www.jianshu.com/c/f0b5eb9b9e2f?order_by={}&page={}'.format(a,count))
r1.encoding = r1.apparent_encoding
dom1 = etree.HTML(r1.text)
print(r1.status_code)
#获取所有的文章标签
items1 = dom1.xpath(xpath_items)
for article in items1:
t = {}
t['link'] = 'https://www.jianshu.com'+article.xpath(xpath_link)[0]
t['title'] = article.xpath(xpath_title)[0]
t['abstract']=article.xpath(xpath_abstract)[0]
print(t)
#解析完毕
count=count+1
print(count)
r1.close()(四)解决一些爬虫常见问题
①解决了翻页问题但是却逃不过被网站拒绝访问qwq,需要设置请求头和代理。请求头很简单,复制一下就ok。
设置代理这个,,我觉得得(dei)看运气(:3[▓▓] 一个代理ip网址:https://www.kuaidaili.com/free/(其实有很多,收费的比免费的更稳定)
最开始随便选择了几个,打算采取随机选取的方法,让访问的时候随机选择一个ip,这样不太容易被识别出来,但失败次数还是蛮高的。试了好几个以后发现有一个ip访问这个每次都是成功的,然后找了几个相似的居然成功率还挺高。不知道现在这个还行不行(。⊙౪⊙。)。因为简书的网址是https的,所以选择代理ip的时候也需要选择对应的。
#代理
proxy_list = [
{"https" : "218.60.8.98:3129"},
{"https" : "218.60.8.83:3129"},
{"https" : "218.60.8.99:3129"}
]
②避免太频繁,除了多设几个代理ip以外,还可以加一个沉睡时间(单位为s级)
time.sleep(5)(五)完整代码(暂时只翻了5页,获取到的数据没有写进文件,可以改改)
#-*- coding: utf-8 -*
import requests
from lxml import etree
import time
import random
import socket
socket.setdefaulttimeout(20)
#请求头
headers1 = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Content-Type': 'application/x-www-form-urlencoded',
'Proxy-Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36',
}
#代理
proxy_list = [
{"https" : "218.60.8.98:3129"},
{"https" : "218.60.8.83:3129"},
{"https" : "218.60.8.99:3129"}
]
#获取所有 li标签
xpath_items = '//ul[@class="note-list"]/li'
#对每个 li标签再提取
xpath_link = './div/a/@href'
xpath_title = './div/a[@class="title"]/text()'
xpath_abstract='./div/p/text()'
a='added_at'
count=1
#获取和解析网页
while count<5:
proxy = random.choice(proxy_list)
print(proxy)
r1 = requests.get('https://www.jianshu.com/c/f0b5eb9b9e2f?order_by={}&page={}'.format(a,count), headers=headers1,proxies=proxy)
print('https://www.jianshu.com/c/f0b5eb9b9e2f?order_by={}&page={}'.format(a,count))
r1.encoding = r1.apparent_encoding
dom1 = etree.HTML(r1.text)
print(r1.status_code)
#获取所有的文章标签
items1 = dom1.xpath(xpath_items)
for article in items1:
t = {}
t['link'] = 'https://www.jianshu.com'+article.xpath(xpath_link)[0]
t['title'] = article.xpath(xpath_title)[0]
t['abstract']=article.xpath(xpath_abstract)[0]
print(t)
#解析完毕
count=count+1
print(count)
r1.close()
time.sleep(5)
结果用json文件存的,比较方便传数据库


















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









