




近年来,无人机技术迅猛发展,农业植保、物流配送、城市安防、环保监测等领域全面开花:
市场规模:全球无人机市场预计2025年超3000亿元,中国占比超50%,成为核心增长引擎。
尽管需求旺盛,传统检测技术依赖人工调参(如锚框设计、NMS后处理),导致泛化性差、效率低,成为行业落地“卡脖子”难题。
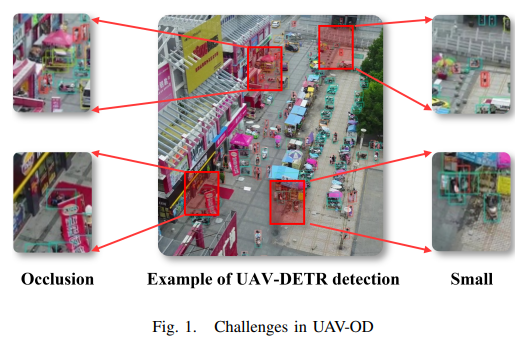
无人机航拍图像在安防、环保、农业等领域应用广泛,但传统目标检测技术面临两大难题:小物体识别难(如行人、垃圾)和遮挡场景误检率高。
2025年最新方案——UAV-DETR,通过融合空间与频率信息、优化特征对齐,显著提升检测精度,同时保持实时性!

论文链接:
https://arxiv.org/abs/2501.01855
项目地址:
https://github.com/ValiantDiligent/UAV-DETR
目录
一、技术挑战
-
小目标检测与遮挡管理
-
像素级难题:无人机图像中小目标(如垃圾、行人)仅占数像素,边缘模糊易漏检。
-
密集遮挡干扰:车辆、行人重叠区域导致特征混淆,传统模型误检率高。
-
计算效率与精度平衡
-
两阶段方法局限:从粗到细的检测流水线(如Faster R-CNN)精度高,但计算开销大,难以部署至无人机嵌入式平台。
-
单阶段模型瓶颈:YOLO系列依赖NMS后处理,引入超参数调优,速度和稳定性难以兼顾。
二、核心创新点
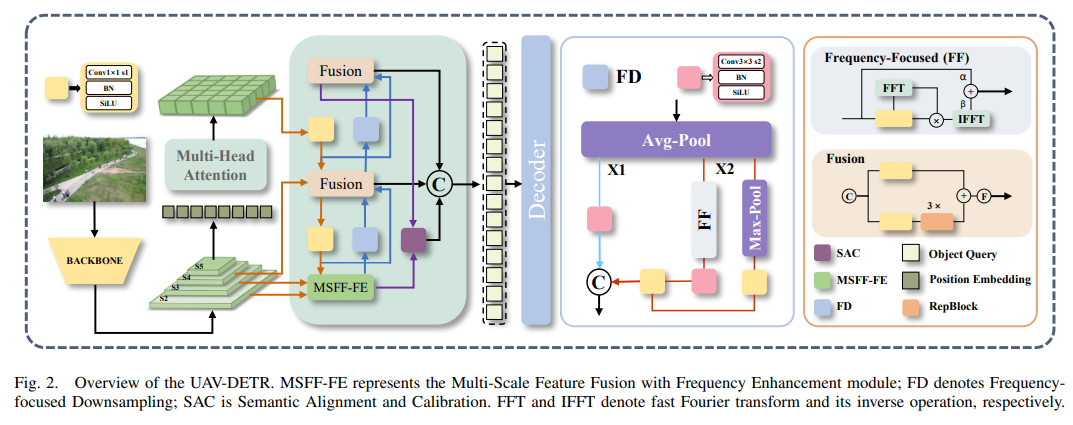
如图 2 所示,本研究提出了一种基于RT-DETR架构的UAV-DETR模型。我们通过三个组件增强了该模型,即带频率增强的多尺度特征融合、以频率为重点的下采样以及语义对齐与校准。此外,我们引入了内部Scylla交并集 (Inner-SIoU) 来取代广义交并集 (GIoU)。
-
多尺度特征融合 + 频率增强
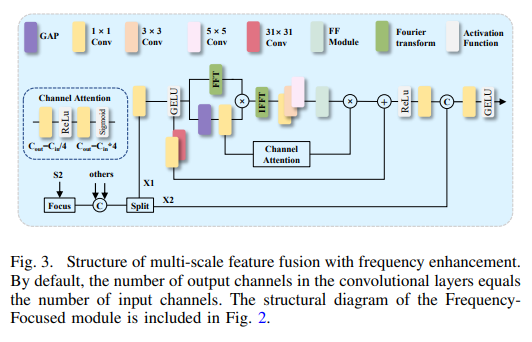
-
频域信号提取:
傅里叶变换(FFT):将输入特征图转换到频域,分离高频(边缘、纹理)与低频(背景、主体)成分。
频域增强:通过全局平均池化(GAP)和卷积层,动态放大高频信号(如垃圾边缘、车轮纹理)。
逆傅里叶变换(IFFT):将增强后的频域特征转换回空间域,生成细节更丰富的特征图。
-
多尺度卷积组合:
并行卷积核:使用1x1、3x3、5x5三种卷积核,分别捕获局部细节、中程关联和长程依赖(如密集车流中的遮挡车辆)。
动态权重融合:通过可学习参数α、β,平衡不同尺度特征的贡献,公式如下:
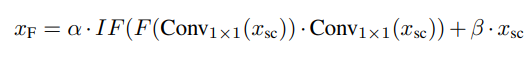
(其中,Xsc为多尺度卷积输出,F为傅里叶变换)
残差连接:保留原始特征,避免梯度消失,加速模型收敛。
-
频率聚焦下采样(FD模块)
在降低特征图分辨率时,保留关键高频信息。
-
双分支处理:
分支1(空间保留):使用3x3卷积(步长2)压缩特征图,保留空间结构。
分支2(频域增强):
频域聚焦(FF模块):对特征图进行频域滤波,强化小目标细节。
最大池化:压缩特征图尺寸,减少计算量。
-
特征融合策略:
拼接与压缩:将两分支输出拼接后,通过1x1卷积压缩通道数,减少75%计算量。
动态选择机制:根据输入特征自动调整分支权重,优先保留高频信息。
-
语义对齐与校准(SAC模块)
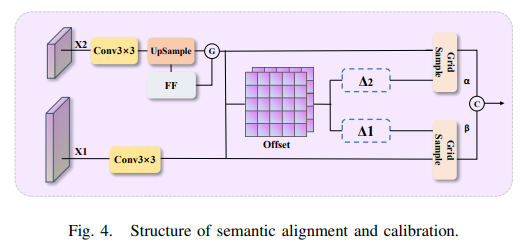
决多尺度特征图的空间错位问题(如检测框偏移)。
-
动态网格采样(GridSample):
偏移量学习:通过卷积层预测2D偏移量Δ₁、Δ₂,调整特征图坐标。
双线性插值:根据偏移量动态重采样特征,实现像素级对齐(公式如下):

-
注意力权重融合:
门控机制:生成空间注意力图G(x),加权融合对齐后的特征:
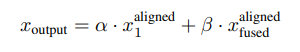
噪声抑制:通过权重分配,抑制背景干扰(如树木阴影误检为垃圾)。
三、Coovally AI模型训练与应用平台
如果你也想要使用模型进行训练或改进,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
具体操作步骤可参考:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
四、实验结果与性能对比
-
数据集选择
我们在两个对象检测数据集上进行了定量实验: VisDrone和UAVVaste。VisDrone-2019-DET 数据集包括 6,471 张训练图像、548 张验证图像和 3,190 张测试图像,所有这些图像都是,由无人机在不同高度、不同位置捕获的。每张图像都标注了十个预定义物体类别的边界框:行人、人、汽车、面包车、公交车、卡车、摩托车、自行车、遮阳篷三轮车和三轮车。
使用 VisDrone-2019-DET 训练集和验证集分别进行训练和测试。
此外,还使用 UAVVaste 数据集进一步训练 UAV-DETR 网络,以验证跨数据集的泛化能力。UAVVaste 是一个专门用于空中垃圾检测的数据集。它由 772 张图片和3716 个手工标注的注释组成,涉及城市和自然环境(如街道、公园和草坪)中的垃圾。
-
对比实验
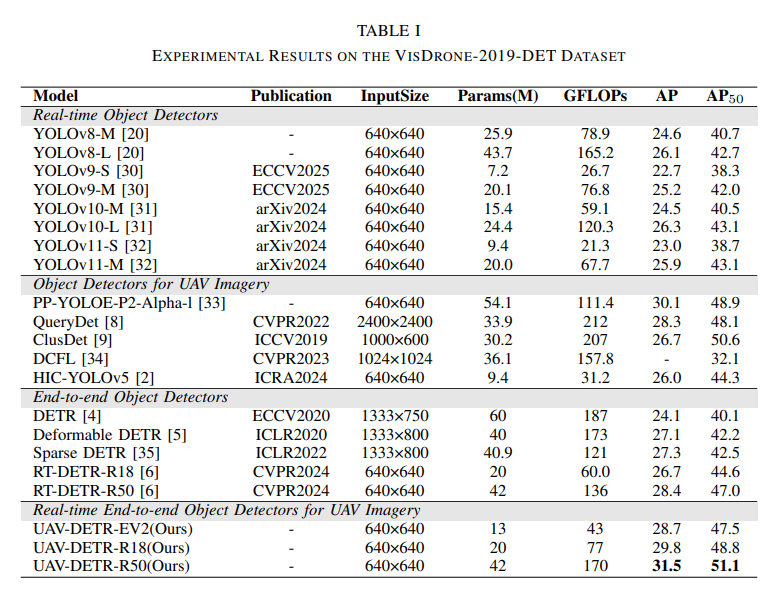
与基线 RT-DETR-R18 相比,UAV-DETR-R18的AP提升3.1%,AP50 提升了 4.2%,验证频域融合的有效性。UAVDETR-R18 优于所有计算成本低于 100 GFLOPs 的方法,在同类方法中达到了最佳精度。值得注意的是,即使与PP-YOLOE-P2-Alpha-l等通常得益于大量预训练的方法相比,我们的方法仍然表现出色。
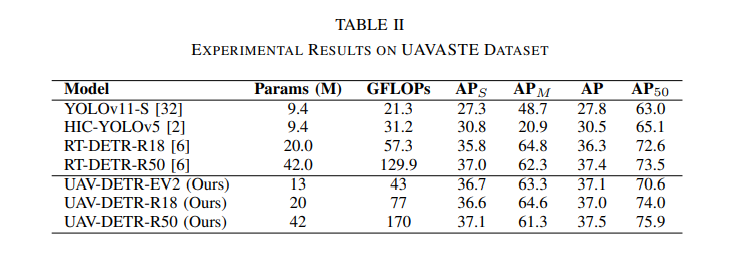
为了进一步证明 UAV-DETR 的通用性,我们还在 UAVVaste 数据集上对该方法进行了评估。结果见表二。值得注意的是,与其他模型相比,UAV-DETR 仍然保持着的竞争优势。
-
消融实验
基线 RT-DETR-R18 的 AP 为 26.7,AP50 为 44.6。
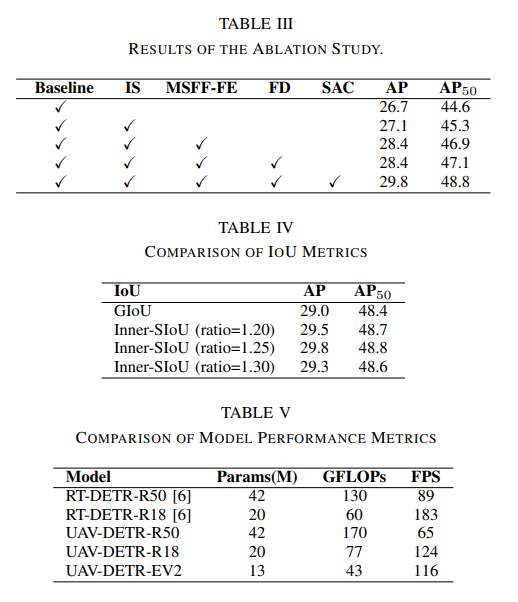
在加入Inner-SIoU损失函数后,,AP 增加到 27.1,这表明改进损失函数对性能有积极影响。加入 MSFF-FE 模块后,AP 进一步提高到 28.4,这表明,加入多尺度特征融合和频率增强的好处。添加 FD模块后,AP50提高到 47.1。综合所有组件,UAV-DETRR18 的性能最高,AP 为 29.8,AP50 为 48.8,这显示了每个模块对检测精度的累积影响
-
可视化分析
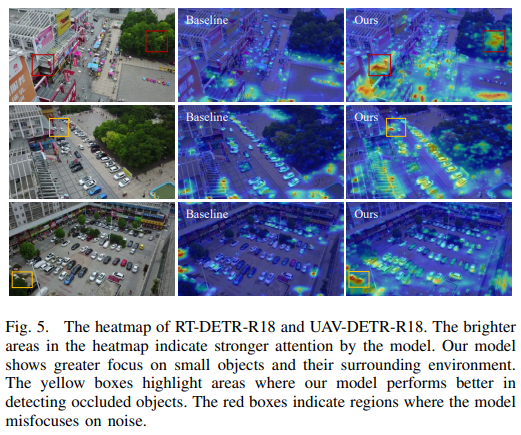
与基线模型相比,UAV-DETR 的小物体定位能力显著提升。在模型的热图中,小物体的热度值更高,这表明该模型能够更有效地捕捉这些小物体的特征。此外,可以观察到 UAVDETR 更加关注小物体的周围信息,这表明该模型在检测过程中能够更好地利用上下文信息。因此,UAV-DETR 在遮挡物体定位方面也表现良好。UAV-DETR 不会严重降低基线模型的实时性能。
五、总结
UAV-DETR通过空间-频域双域融合、动态特征对齐与高效计算设计,这种方法能够为如何在 UAV-OD 任务中更好地利用频率信息提供参考。显著提升无人机图像中小目标检测精度,兼顾实时性,为环保、交通、农业等场景提供高性价比AI解决方案。


















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









