




目录
USOD (Unicorn Small Object Dataset)
摘要
由于在遥感应用中的小目标检测面临着特征表示不足、背景混淆以及在有限的硬件条件下优化速度和精度的挑战。
因此设计了一种高精度的小型物体检测器FFCA-YOLO,其包括三个创新的轻量级即插即用模块:特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM)。这三个模块分别提高了局部区域感知、多尺度特征融合以及跨信道和空间的全局关联等网络能力,同时尽量避免增加复杂性。因此,小物体的弱特征表示得到了增强,可混淆的背景得到了抑制。为了验证FFCA-YOLO的有效性,采用了两个公开的遥感小目标检测数据集(VEDAI和AI-TOD)以及一个自建数据集(USOD)。USOD数据集包含99.9%小于32×32像素的目标,并在低照度、阴影遮挡等条件下有丰富实例,提供了多个退化条件下的测试集,为遥感小目标检测提供了基准。除此之外,为进一步降低计算资源消耗同时保持效率,还提出了其精简版L-FFCA-YOLO,L-FFCA-YOLO速度更快、参数规模更小、计算力需求更低,而精度损失甚微,展现了良好的性能与效率平衡。
引言
YOLO系列模型在小目标检测方面的表现一直以来都是相对较弱,尤其是在较低分辨率和小物体尺寸的情况下。这是因为YOLO模型本身的设计偏向于实时检测和速度优化。由于特征表示不足和背景混淆等问题,相对遥感中的小目标检测任务更是十分艰巨。特别是当算法要在船上进行实时处理时,需要在有限的通信资源条件下对精度和速度进行大量优化。为了解决这些问题,提出了一种高效的检测器,称为特征增强、融合和上下文感知YOLO(FFCA-YOLO)。
FFCA-YOLO架构
FFCA-YOLO选择YOLOv5作为基准框架,YOLOv5的参数更少,而且在小物体检测任务中能保持一定的准确性。
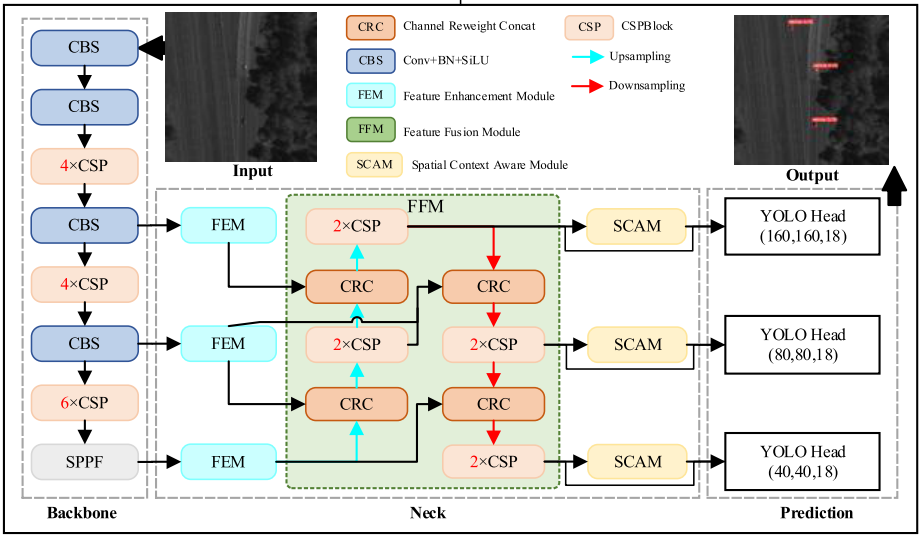
首先,FFCA-YOLO在特征提取上只使用了四次压缩子采样运算,这与原来的YOLOv5有所不同。其次,在YOLOv5的基础上增加了三个专门设计的模块:提出了轻量级FEM,以提高网络的局域感知能力;提出了FFM,以提高多尺度特征融合能力;设计了SCAM,以提高跨信道和空间的全局关联能力。
FEM(特征增强模块)
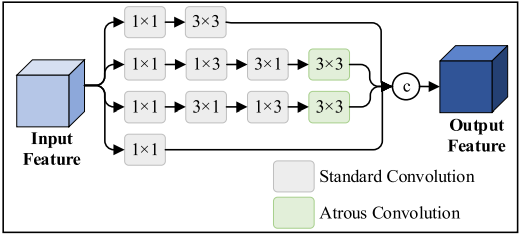
通过多分支卷积结构,FEM提取多种辨别性语义信息,从而提升小物体的特征表现。
-
扩大感受野:采用无齿卷积来扩大感受野,帮助捕捉更丰富的局部语境信息,提高小物体与背景的区分能力。
-
结构设计:FEM的灵感来源于RFB-s,但有所不同。FEM仅使用两个带无序卷积的分支,每个分支进行11卷积操作,以调整通道数,为后续处理做准备。
-
第一个分支:采用残差结构,保留小物体的关键特征信息。
-
其他分支:通过不同大小的卷积核(1×3、3×3等)进行级联,增加额外的卷积层,以提取更多上下文信息,提升特征图的丰富度。
FFM(特征融合模块)
FFM基于BiFPN结构,通过有效汇聚高层和低层特征图中的信息来增强小物体的语义表示。高层特征图通常包含较为抽象的语义信息,而低层特征图则包含更多细节。FFM通过将这两种信息融合,提高了小物体的辨识能力。
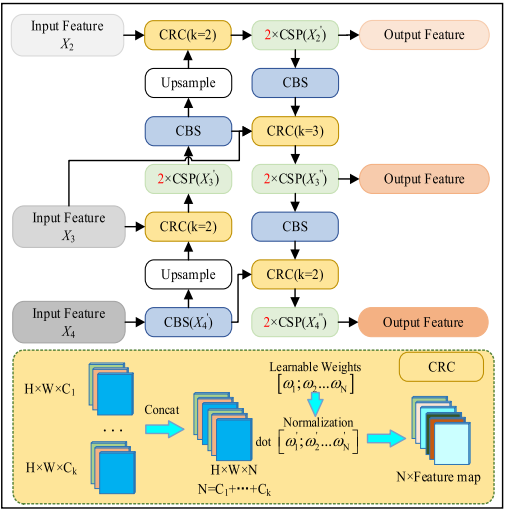
与BiFPN不同,FFM引入了CRC重新加权策略,优化了通道融合的过程。CRC通过重新加权不同通道,充分利用特征图中的信息,增强了多尺度特征的表达能力。这一策略的核心在于,针对不同特征图的通道使用不同的权重,提升了特征的多样性和精度。
-
自顶向下与自底向上的处理策略:
-
自顶向下:FFM首先处理高层特征图,通过CSPBlock进行特征提取,并上采样至与底层特征图相同的尺度,接着利用CRC融合两个特征图。这样,能够从深层流向浅层传递语义信息,确保小物体的特征不被丢失。
-
自底向上:此过程与自顶向下相似,但采用步长为2的卷积进行降采样,进一步减少计算量,同时融合不同尺度的特征。
-
简化的通道加权策略:FFM在通道加权策略上进行了优化,选择了将特征图连接后进行加权的第二种策略。此策略通过乘以归一化的可训练权重,有效减少了计算成本,并保持了加权的效果。
-
高效融合:通过CRC和特征图之间的重新加权,FFM实现了多尺度特征的高效融合。相比于传统的融合策略,FFM能够在不显著增加计算成本的情况下,提升小物体检测的表现。
SCAM(空间上下文感知模块)
经过FEM和FFM处理后,特征图已经包含了局部背景信息并较好地表示了小物体的特征。在此阶段,SCAM通过建模小物体与背景之间的全局关系来进一步提升物体与背景的分辨能力。SCAM利用全局上下文信息,有效抑制背景噪声,强化小物体与背景的区别。
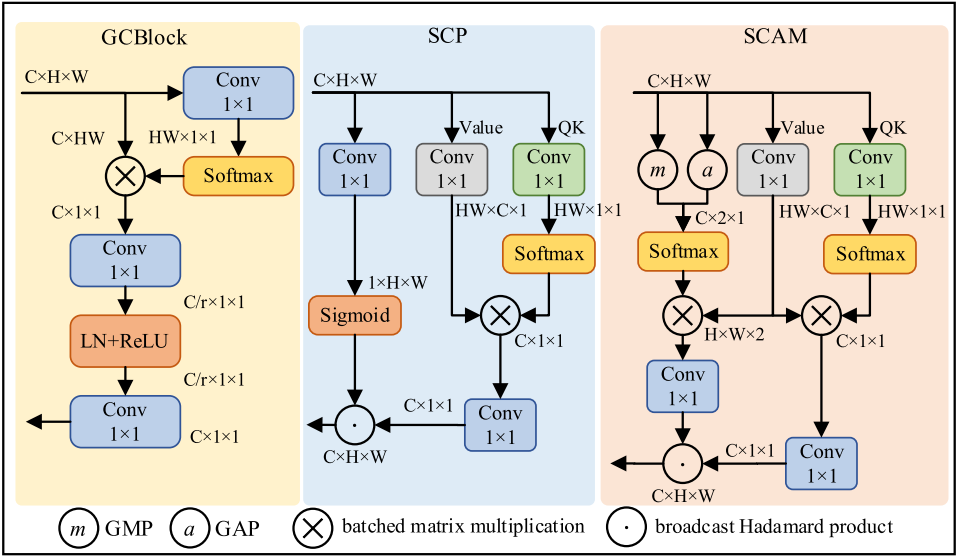
SCAM由三个分支组成,每个分支执行不同的任务:
-
第一个分支:使用全局平均池化(GAP)和全局最大池化(GMP)操作来整合全局信息。通过这两个池化操作,SCAM能够选择具有重要信息的通道,从而理解通道维度的上下文信息。
-
第二个分支:使用1×1卷积进行线性变换,生成特征图的线性表示,以捕捉特征的全局信息。
-
第三个分支:同样使用1×1卷积简化查询和键的交互,称为QK分支,用于提取跨信道和空间的上下文信息。
-
矩阵相乘与信息融合:第一和第三个分支分别与第二个分支进行矩阵相乘,得到的结果代表了跨信道和空间的上下文信息。通过这种方式,SCAM能够精确捕捉到多层次的上下文信息,进一步增强对小物体的感知能力。
-
Hadamard乘积融合:最终,两个分支的输出通过广播Hadamard乘积操作进行融合,从而得到SCAM的最终输出。哈达玛乘积有助于将跨信道和空间的上下文信息有效结合,提升整体表现。
SCAM通过上述处理步骤,使得每一层的像素空间上下文得到有效表示。SCAM不仅提升了小物体的检测精度,还加强了背景与物体之间的分辨能力,特别是在复杂背景的环境下。
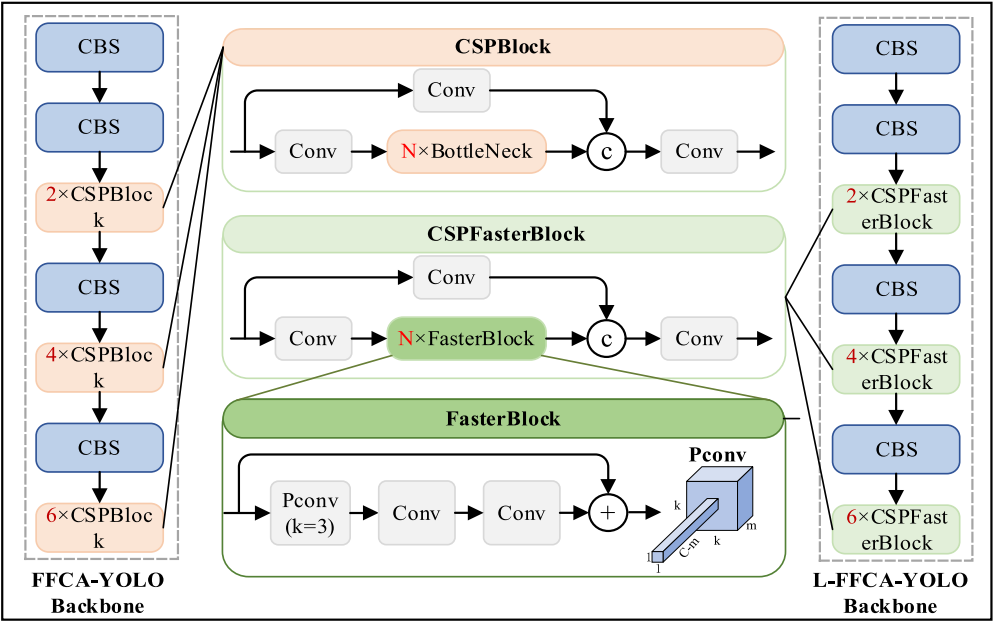
L-FFCA-YOLO(轻量级版本)
-
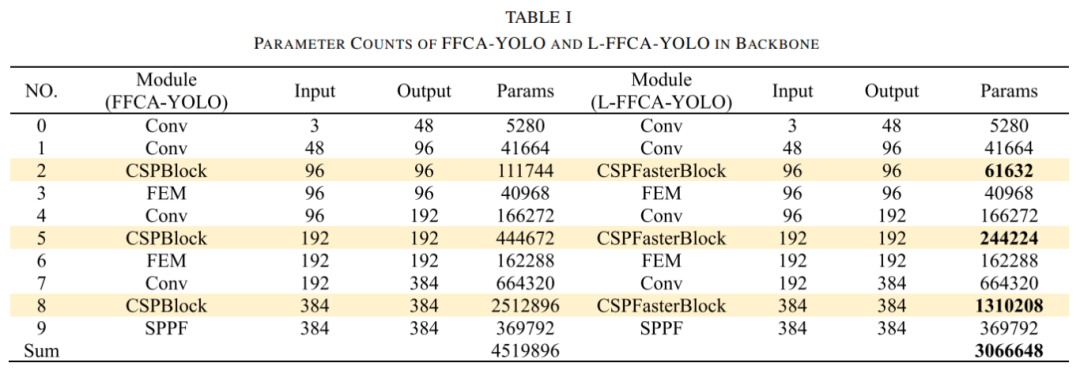
参数量减少:L-FFCA-YOLO的主干网相比FFCA-YOLO减少了30%的参数量,提升了计算效率。
-
CSPFasterBlock:在主干网中使用了CSPFasterBlock,结合了FasterNet中的FasterBlock设计,采用部分格式(PConv)来优化计算,减少动画计算并提高速度。
-
结构优化:通过缩小通道数和采用通道缩放比,同时减少计算量,保持特征信息的限度,保证精度损失最小。
USOD (Unicorn Small Object Dataset)
本文中除了采用VEDAI数据集,团队还自建了一个数据集USOD。

-
数据来源与多模态计划:USOD基于UNICORN2008数据集,包含来自光电传感器的可见光图像和合成孔径雷达图像,未来可能扩展为多模态数据集。
-
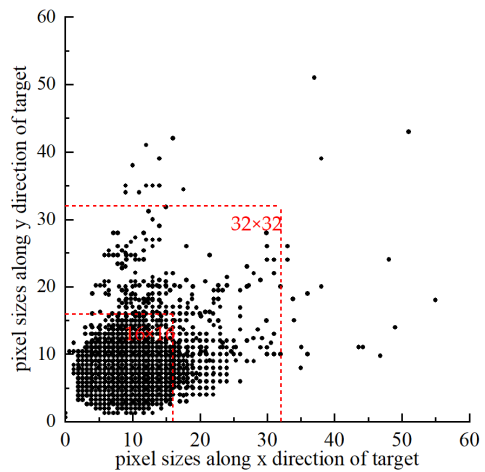
小物体比例高:USOD中小于16×16像素的物体占96.3%,小于32×32像素的物体占99.9%,小物体比例明显高于其他数据集(如AI-TOD的97.9%)。
-
数据集规模:USOD包含3000幅图像和43378个车辆实例,训练集与测试集按7:3比例划分。
-
挑战性条件:数据集中有许多车辆实例处于低照度和阴影遮挡环境,有助于验证模型在复杂条件下的表现。
-
鲁棒性验证:包含多个测试集,考虑了模糊、高斯噪声、条纹噪声和雾等图像退化因素,用于验证模型的鲁棒性。
USOD作为遥感小目标检测的基准数据集,提供了丰富的挑战和多样化的测试条件,适用于验证小物体检测算法的性能。
USOD数据集下载
在Coovally AI Hub公众号后台回复「USOD」或参考USOD数据集文章,即可获取下载链接!
Coovally AI模型训练与应用平台
如果你也想要进行模型改进或模型训练,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
实验结果
FFCA-YOLO和L-FFCA-YOLO在三个数据集(VEDAI、AI-TOD和USOD)上的实验结果表明,这两种模型在遥感小目标检测任务中表现出色,尤其是在复杂背景和低照度条件下的检测能力显著优于其他现有方法。

-
VEDAI数据集
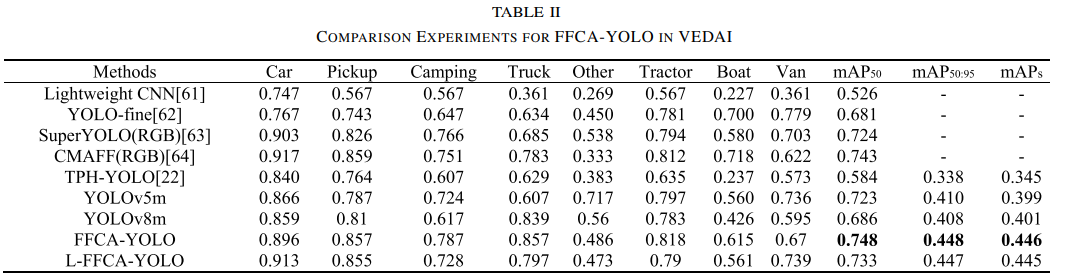
FFCA-YOLO在mAP50指标上比CMAFF提高了0.005。
与YOLOv5m相比,FFCA-YOLO在mAP50、mAP50:95和mAPs上分别提高了0.025、0.038和0.047。
特别是在mAPs上的显著提升,表明FFCA-YOLO在遥感小目标检测方面具有明显优势。
-
USOD数据集
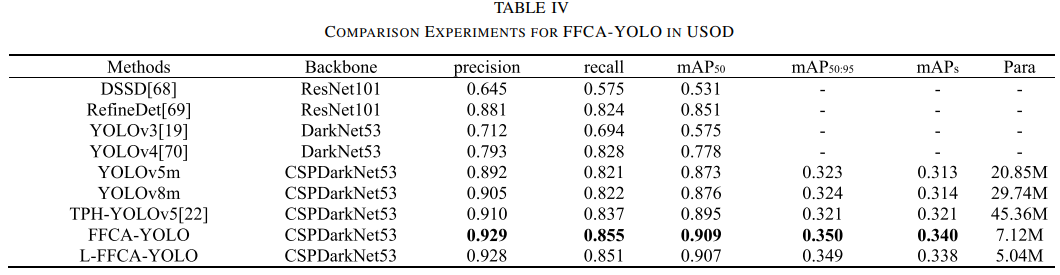
FFCA-YOLO在相同的训练条件下,参数数量更少,性能更高。
L-FFCA-YOLO将参数数量减少了约30%(从7.12M降至5.04M),但准确度指标没有明显下降。
在低照度和阴影遮挡场景中,FFCA-YOLO表现出更好的检测能力,避免了YOLOv5m和TPH-YOLO的检测遗漏问题。
-
AI-TOD数据集
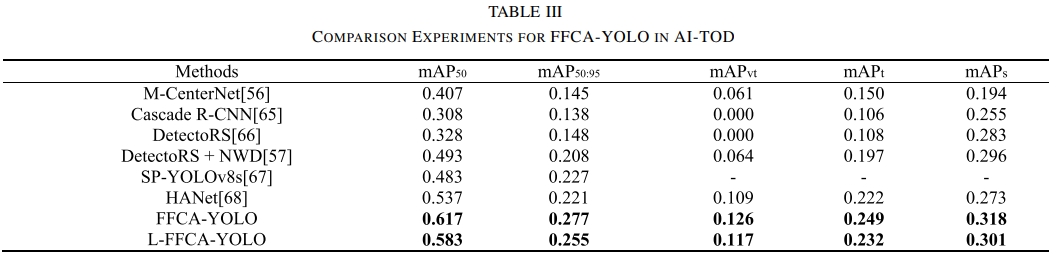
FFCA-YOLO在mAP50上达到了0.617,比当前最好的模型HANet高出0.08。
在mAP50:95、mAPvt、mAPt和mAPs上分别提升了0.056、0.015、0.027和0.045。
这些结果进一步证明了FFCA-YOLO在小目标检测中的卓越性能。
-
消融实验
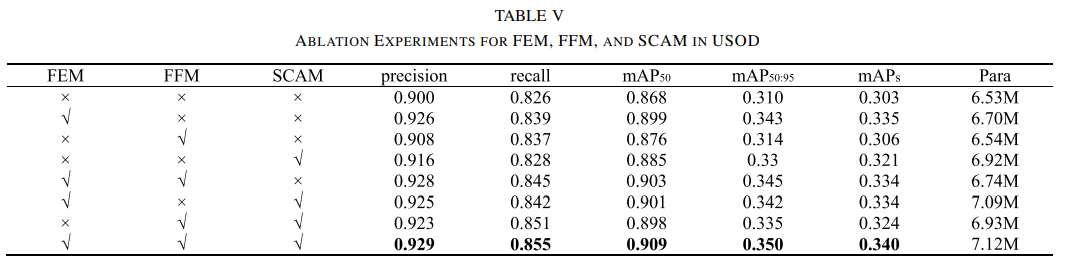
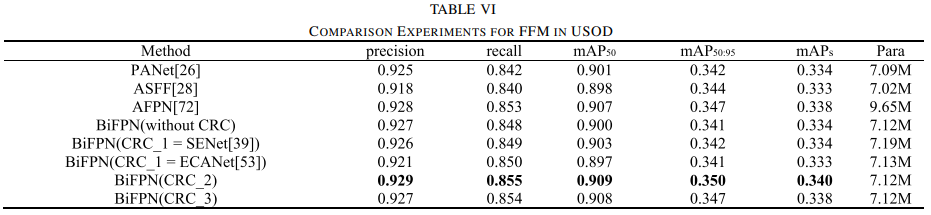

FEM、FFM和SCAM模块的加入均显著提升了模型的性能。特别是FEM增强了小物体与背景的分辨率,FFM提高了召回率,特别是在多尺度特征融合方面,CRC_2策略表现最佳。而SCAM进一步优化了特征图,增强了小物体的检测能力,并抑制了背景干扰,进一步提升了模型的整体性能。
-
鲁棒性实验
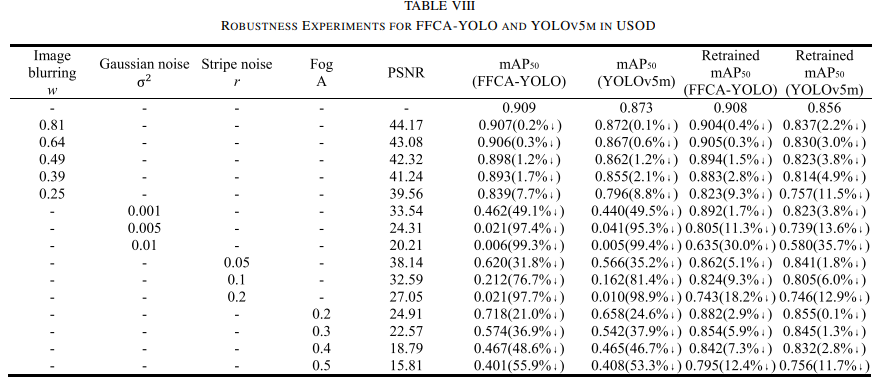
FFCA-YOLO在图像模糊和雾霾等条件下表现出较好的鲁棒性。在图像模糊和雾气条件下表现优于YOLOv5m。尽管对于高斯噪声和条纹噪声,FFCA-YOLO的抗干扰能力较弱,但通过数据增强和重新训练,模型的抗噪声能力有所提升。
-
轻量级对比实验
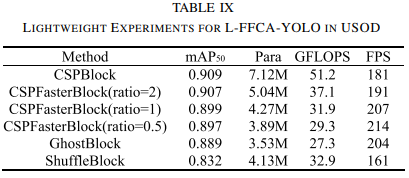
L-FFCA-YOLO在保持较高性能的同时,显著减少了参数数量,特别是在使用CSPFasterBlock时,虽然计算复杂度相对较高,但在精度和速度的平衡上表现出色。与GhostBlock和ShuffleBlock相比,CSPFasterBlock在相似的GFLOPs下提供了更快的速度和更优的内存效率。
总结
总体来说,FFCA-YOLO通过创新性地融合FEM、FFM和SCAM模块,不仅有效提升了小物体检测的精度,还增强了模型在复杂环境下的鲁棒性。无论是在遥感数据集中的应用,还是在低照度和遮挡场景中的表现,FFCA-YOLO都展现出了明显的优势。同时,L-FFCA-YOLO在保持高性能的基础上,通过轻量化设计进一步优化了计算效率,适应了对实时性和资源消耗有更高要求的应用场景。因此,FFCA-YOLO为小物体检测提供了一种更加高效且精准的解决方案,具有广泛的应用潜力。



















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









