



🔥“你是否面对海量机器学习模型时,总感觉像在迷宫里打转?线性回归和逻辑回归到底差在哪?XGBoost凭什么称霸Kaggle?无监督学习的聚类和降维如何真正落地?别慌!你缺的不是知识,而是一张系统化的机器学习模型导航地图!
先参考一张图,来追根溯源,理清常用模型的根源。图片来源:【机器学习基础】机器学习模型与算法最全分类汇总!-优快云博客
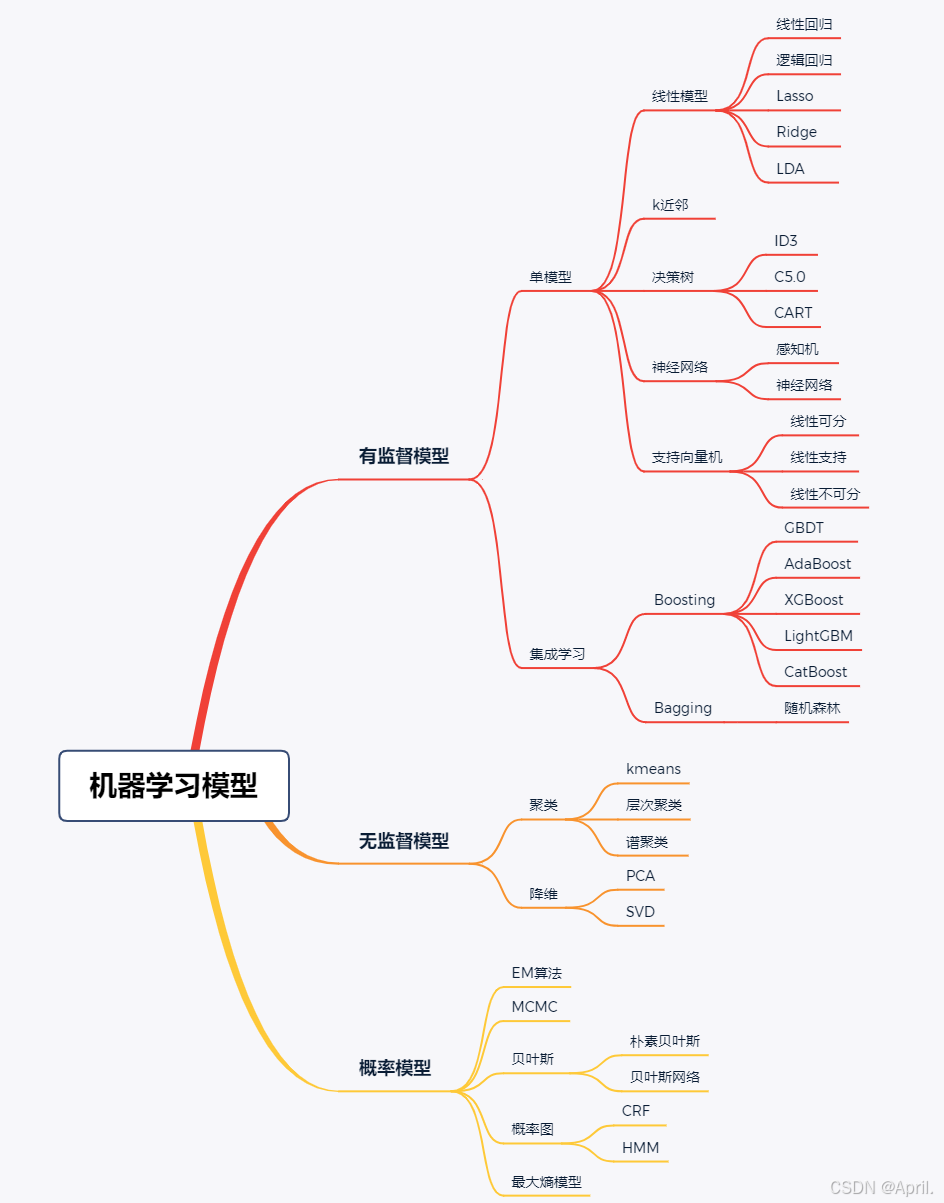
🔥本文将为你彻底拆解35+核心模型与技术,从线性回归到贝叶斯网络,从单模型到集成学习,从监督到无监督,用一张清晰的知识框架图(文末附高清版),帮你告别碎片化学习!无论你是想面试突击、项目实战,还是构建完整知识体系,这篇全网最干的机器学习模型百科全书,都能让你在10分钟内抓住本质,效率碾压90%的同行!
先将一些通识性的东西,后面步步深入展开来提升阅读体验
一、机器学习的三大任务
在介绍具体模型之前,我们先了解机器学习的三大核心任务:
-
预测:比如预测明天的温度、房价的涨跌。
-
分类:比如判断一张图片是猫还是狗、一封邮件是否是垃圾邮件。
-
聚类:比如根据用户的购物习惯,把用户分成不同的群体。
PS:这里的分类和聚类稍有迷惑性,我们简单来区分其不同点:- 分类任务是有监督学习任务,目标是根据已有的标注数据,将新的数据实例划分到已知的类别中。
聚类任务是无监督学习任务,没有给定的标注信息和预设的类别,目标是根据数据自身的特征和相似性,将数据点划分为不同的群组 - 分类任务一般需要带标签的训练集和无标签的测试集。
聚类任务只有一个无标签的数据集 - 分类任务偏应用价值,在已知类别的情况下,判断新的类别所属。比如判断是否患病,是否存在安全风险,是否是恶意软件等。
聚类任务偏创新价值,常用于探索性数据分析、市场细分等场景。比如对用户聚类可以发现不同消费行为特征的用户群体,为制定个性化的营销策略提供依据,挖掘信息。 - 分类任务常见的模型:决策树、支持向量机、神经网络等。
聚类任务常见的算法: K-Means、层次聚类等。
- 分类任务是有监督学习任务,目标是根据已有的标注数据,将新的数据实例划分到已知的类别中。
二、模型分类体系
根据任务类型和学习方式,机器学习模型可以分为以下大类:
1. 有监督学习模型(需要“老师”指导)
有监督学习就像老师教学生做题:老师提供“题目(输入数据)”和“正确答案(标签)”,学生通过反复练习,学会如何根据题目找到答案。
(1)线性模型
-
线性回归
用途:预测一个连续的数值,比如根据房屋面积预测房价。
例子:假设你发现“学习时间”和“考试成绩”是正相关的,可以用线性回归预测某位同学学习5小时后能考多少分。 -
逻辑回归
用途:预测概率,比如判断用户是否会点击广告(是/否)。
例子:根据用户的年龄、性别、浏览历史,预测TA购买某件商品的概率。 -
Lasso 和 Ridge
区别:它们是线性回归的改进版,用于防止模型过于复杂(过拟合)。
例子:如果预测房价时用了100个特征(面积、楼层、装修等),Lasso/Ridge 可以自动筛选出最重要的几个特征。
(2)树模型
-
决策树
用途:通过一系列“是/否”问题做决策。
例子:判断一个人是否适合打篮球:身高是否超过1.8米?体重是否小于80公斤?……每个问题都是一个分支。 -
CART、ID3、C5.0
区别:它们是决策树的不同算法,核心思想类似,但计算方式不同。比如ID3用信息增益选择特征,CART用基尼系数。
(3)支持向量机(SVM)
-
用途:找一个“最优分界线”来分类数据。
例子:在一张纸上画红点和蓝点,SVM会找到一条最宽的线,把红点和蓝点分开。
(4)神经网络
-
用途:模仿人脑的神经元,解决复杂问题(如图像识别、自然语言处理)。
例子:训练一个神经网络识别手写数字,输入是图片像素,输出是0-9中的一个数字。
(5)k近邻(k-NN)
-
用途:根据“邻居”的标签预测当前数据的标签。
例子:如果班里大多数同学喜欢数学,那么新转来的同学可能也喜欢数学。
2. 无监督学习模型(没有“老师”指导)
无监督学习就像让机器自己发现数据的规律,没有正确答案的标签。
(1)聚类模型
-
k-means
用途:把数据分成k个类别。
例子:根据顾客的购物金额和频率,将顾客分为“高消费高频”“低消费低频”等群体。 -
层次聚类
用途:生成树状的聚类结构。
例子:生物学家用层次聚类分析不同物种的进化关系。
(2)降维模型
-
PCA(主成分分析)
用途:将高维数据压缩到低维,保留主要信息。
例子:把一张100x100像素的图片压缩成10个关键特征,方便后续分析。
3. 集成学习模型(团队合作的力量)
集成学习通过组合多个“弱模型”,得到一个更强大的模型。
(1)Bagging
-
随机森林
用途:生成多棵决策树,通过投票得出最终结果。
例子:10位医生各自诊断病情,最终以多数意见为准。
(2)Boosting
-
AdaBoost
用途:逐步调整错误样本的权重,让模型更关注难分类的数据。
例子:考试前先复习错题,再复习其他题目。 -
GBDT、XGBoost、LightGBM
区别:GBDT是基础算法,XGBoost和LightGBM是优化版本,速度更快、效果更好。
例子:用XGBoost预测用户是否会流失,综合多个特征(登录频率、消费金额等)。
4. 概率模型(用概率说话)
这些模型通过概率分布描述数据的关系。
-
朴素贝叶斯
用途:基于贝叶斯定理,假设特征之间相互独立。
例子:判断一封邮件是否是垃圾邮件,根据关键词(“免费”“中奖”)出现的概率。 -
隐马尔可夫模型(HMM)
用途:处理序列数据,比如语音识别。
例子:根据一段语音信号的序列,识别对应的文字。
三、模型对比与应用场景
1. 线性模型 vs 树模型
-
线性模型适合数据关系简单、连续的问题(如预测房价)。
-
树模型适合数据关系复杂、需要分步决策的问题(如判断贷款风险)。
2. 有监督 vs 无监督
-
有监督需要标签数据,适合分类、回归任务。
-
无监督不需要标签,适合探索数据内在结构(如用户分群)。
3. 单一模型 vs 集成模型
-
单一模型(如决策树)简单但容易过拟合。
-
集成模型(如随机森林)通过团队合作提高鲁棒性。
下面是各个模型穿插具体介绍
逻辑回归(Logistic Regression)
1. 什么是逻辑回归?
逻辑回归是一种用来解决 分类问题 的机器学习模型。它的任务是预测某件事情发生的 概率,并根据概率做出分类决策。
举个例子:
假设你想预测一个学生是否能通过考试(通过/不通过),逻辑回归可以根据学生的“学习时间”和“平时成绩”,计算出通过考试的概率。
2. 逻辑回归的核心思想
逻辑回归的核心是一个 S形函数(Sigmoid函数),它可以把任意数值映射到0到1之间。这个值就是概率。
Sigmoid函数的作用:
-
输入:一个数值(比如学习时间 + 平时成绩的综合得分)。
-
输出:一个0到1之间的概率值(比如0.8表示通过考试的概率是80%)。
决策规则:
-
如果概率 > 0.5,预测为“通过”。
-
如果概率 < 0.5,预测为“不通过”。
3. 逻辑回归的数学原理
虽然逻辑回归涉及一些数学知识,但我们可以用简单的语言来解释。
(1)线性组合
逻辑回归首先计算输入特征的 线性组合。比如:

-
w0,w1,w2 是模型的参数(权重),需要通过训练数据学习。
-
z 是一个综合得分,表示学生的学习情况。
(2)Sigmoid函数
接下来,逻辑回归通过Sigmoid函数将 z 转换为概率:
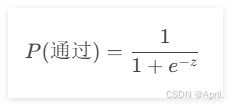
-
如果 z 很大,
接近0,概率接近1。
-
如果 z 很小,
-
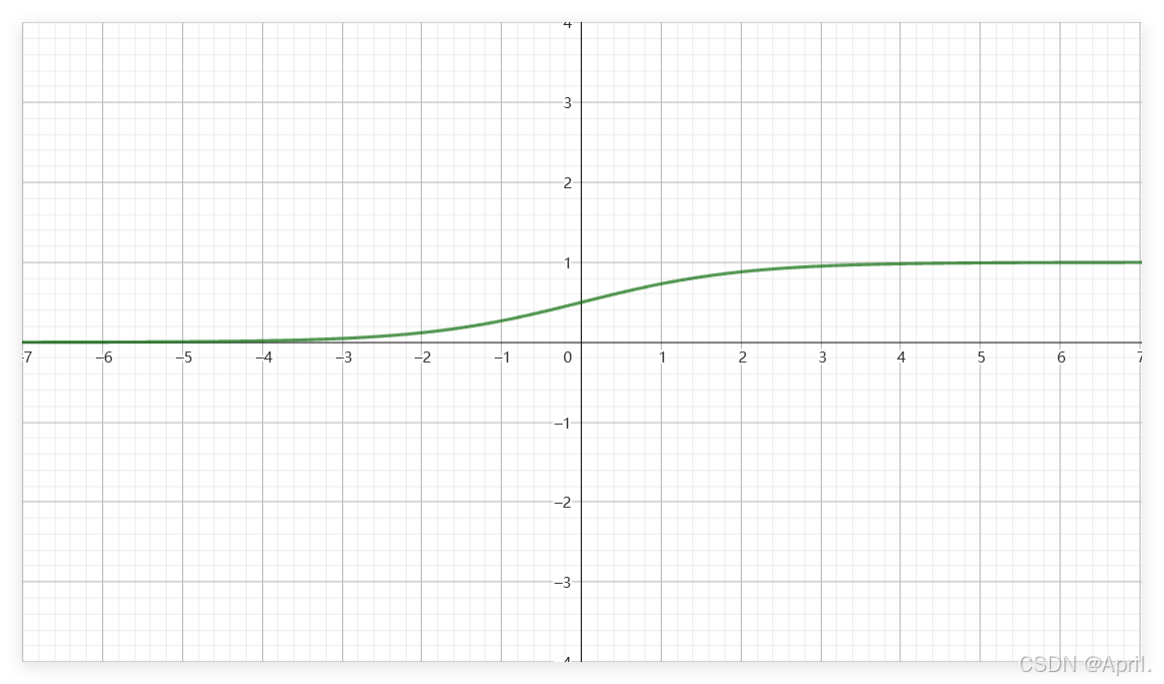
(下图可以直观理解该函数取值的影响)
(3)损失函数
逻辑回归通过 损失函数 来衡量预测概率与真实标签的差异。目标是让预测概率尽可能接近真实结果。
4. 逻辑回归的训练过程
逻辑回归的训练过程就是找到一组参数 w,使得模型的预测结果最准确。
梯度下降法
逻辑回归使用 梯度下降法 来优化参数:
-
初始化参数 w。
-
计算损失函数的值。
-
根据损失函数的梯度,调整参数 w。
-
重复上述步骤,直到损失函数的值不再明显下降。
5. 逻辑回归的应用场景
逻辑回归适合解决 二分类问题,也就是只有两种可能结果的问题。比如:
-
判断一封邮件是否是垃圾邮件(是/否)。
-
预测用户是否会点击广告(点击/不点击)。
-
判断患者是否患有某种疾病(患病/不患病)。
6. 举个例子:逻辑回归就像考试评分
想象一下,逻辑回归就像一位老师给学生打分:
-
输入:学生的学习时间、平时成绩。
-
计算:老师根据这些数据,计算学生通过考试的概率。
-
输出:如果概率 > 50%,老师认为学生会通过考试;否则,认为学生不会通过。
7. 总结
-
逻辑回归 是一种用于分类问题的机器学习模型。
-
它通过 Sigmoid函数 将线性结果转换为概率。
-
它适合解决 二分类问题,比如判断邮件是否是垃圾邮件。
-
逻辑回归的训练过程是通过 梯度下降法 优化参数。
-
属于有监督学习、单模型、线性模型。
支持向量机(SVM:Support Vector Machine)
1. 什么是支持向量机?
支持向量机(SVM)是一种用来解决 分类问题 的机器学习模型。它的目标是找到一个 最优分界线,将不同类别的数据分开。
举个例子:
假设你有一堆红色和蓝色的球,SVM的任务是找到一条线,把红球和蓝球分开。这条线不仅要分开两类球,还要尽量远离所有的球,这样分类的结果才更可靠。
2. 支持向量机的核心思想
SVM的核心思想是找到一个 最大间隔超平面,也就是一条分界线,使得两类数据点到这条线的距离最大。
关键概念:
-
超平面:在二维空间中是一条直线,在三维空间中是一个平面,在高维空间中是一个超平面。
-
支持向量:离分界线最近的那些数据点,它们决定了分界线的位置。
-
间隔:分界线到最近数据点的距离,SVM的目标是最大化这个间隔。
3. 支持向量机的工作原理
SVM的工作原理可以分为以下几个步骤:
(1)找到支持向量
SVM首先找到离分界线最近的那些数据点(支持向量)。这些点就像“关键证人”,决定了分界线的位置。
(2)计算最大间隔
SVM的目标是找到一条分界线,使得支持向量到这条线的距离最大。这个距离就是 间隔。
(3)分类决策
一旦找到最优分界线,SVM就可以根据数据点位于分界线的哪一侧,来判断它属于哪个类别。
4. 支持向量机的数学原理
虽然SVM涉及一些数学知识,但我们可以用简单的语言来解释。
(1)线性可分情况
如果数据是线性可分的,SVM的目标是找到一个超平面:
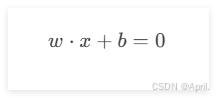
-
w 是超平面的法向量。
-
b 是偏移量。
-
x 是输入特征。
(2)非线性可分情况
如果数据是非线性可分的,SVM可以通过 核函数(Kernel Function) 将数据映射到高维空间,使其在高维空间中线性可分。
5. 支持向量机的应用场景
SVM广泛应用于各种分类问题,尤其是数据维度较高、样本量较小的情况。比如:
-
图像分类:判断一张图片是猫还是狗。
-
文本分类:判断一封邮件是否是垃圾邮件。
-
生物信息学:根据基因数据预测疾病。
6. 举个例子:SVM就像画一条最佳分界线
想象一下,SVM就像一位画家,任务是在一幅画上画一条线,把红点和蓝点分开:
-
找到关键点:画家先找到离分界线最近的那些红点和蓝点(支持向量)。
-
画最佳分界线:画家画一条线,使得这条线离所有关键点的距离最大。
-
分类:根据新点的位置,判断它是红点还是蓝点。
7. 支持向量机的类别划分
SVM属于以下几种类别:
(1)有监督学习
-
特点:需要“老师”提供标签(正确答案)。
-
例子:训练SVM时,我们需要提供一些数据点(红点和蓝点)以及它们的类别标签。
(2)单模型
-
特点:SVM是一个独立的模型,不需要组合其他模型。
-
例子:SVM可以直接用来分类数据,不需要像随机森林那样组合多棵决策树。
8. 总结
-
支持向量机(SVM) 是一种用于分类问题的机器学习模型。
-
它的核心思想是找到一个 最大间隔超平面,将不同类别的数据分开。
-
它适合处理 高维数据 和 小样本数据。
-
它属于 有监督学习 和 单模型。
随机森林(Random Forest)
集成学习中的Bagging和Boosting的区别:
Bagging和Boosting是两种常用的集成学习技术,它们的原理和区别如下![]() https://zhuanlan.zhihu.com/p/106640173
https://zhuanlan.zhihu.com/p/106640173
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
- Bagging用于解决过拟合问题,是一种将基分类器并行训练然后通过投票或者取均值的方式求得最终结果。
- Boosting用于解决欠拟合问题,是一种串行训练方式,每次训练都是基于上一次基分类器的输出与标签的残差而进行的。
- Bagging通过引入多样性和减少方差来提高模型的泛化能力。
- Boosting则通过聚焦于错误样本和提高弱分类器的权重来提高模型的预测精度。
- 实际上,集成学习一共一下四大类:
下面先从随机森林的主要组成成分--决策树 开始
决策树就像是你在做选择时一步步思考的过程,把这个思考过程画成图,就是决策树。
决策树就像玩猜东西游戏时的思考流程。比如猜水果,先问 “是圆形吗”,若 “是”,再问 “是红色吗”,不断根据答案选择下一个问题。这一系列问题构成了像树一样的结构,每个问题是一个分叉点,答案是树枝,最后确定水果是什么就是树的叶子。
机器学习中的决策树类似,它根据数据的特征(如水果的颜色、形状等)不断进行判断,从一个特征条件到下一个,逐步缩小范围,最终把数据分类或预测结果,让计算机能像我们玩游戏猜东西一样,根据特征判断所属类别。
1. 什么是随机森林?
随机森林是一种用来解决 分类和回归问题 的机器学习模型。它的核心思想是通过 多个决策树 的投票或平均,得到更准确的结果。
举个例子:
假设你想预测一个学生是否能通过考试(通过/不通过),随机森林会让多个“小老师”(决策树)分别做出判断,然后根据大多数“小老师”的意见,得出最终结论。
2. 随机森林的核心思想
随机森林的核心思想是 团队合作。通过组合多个决策树的结果,可以减少单个决策树的错误,提高整体的准确性。
关键概念:
-
决策树:一种简单的分类模型,通过一系列“是/否”问题做决策。
-
集成学习:通过组合多个模型,得到更好的结果。
-
Bagging:一种集成学习方法,通过随机采样训练多个模型。
3. 随机森林的工作原理
随机森林的工作原理可以分为以下几个步骤:
(1)随机采样
随机森林从训练数据中随机抽取多个子集(有放回抽样),每个子集用来训练一个决策树。
(2)训练多个决策树
对于每个子集,随机森林训练一个决策树。在训练过程中,每个决策树还会随机选择一部分特征进行分裂。
(3)投票或平均
对于分类问题,随机森林让所有决策树投票,选择得票最多的类别作为最终结果。对于回归问题,随机森林计算所有决策树的平均值作为最终结果。
4. 随机森林的数学原理
虽然随机森林涉及一些数学知识,但我们可以用简单的语言来解释。
(1)随机采样
随机森林通过 Bootstrap采样(Bootstrap 采样就是从一堆数据里,有放回地重复抽取数据,组成新的样本) 从训练数据中随机抽取多个子集。每个子集的大小与原始数据集相同,但可能包含重复的样本。
(2)随机特征选择
在训练每个决策树时,随机森林会随机选择一部分特征进行分裂。这样可以增加模型的多样性,减少过拟合。
(3)投票或平均
对于分类问题,随机森林采用 多数投票 的方式决定最终结果。对于回归问题,随机森林采用 平均值 的方式决定最终结果。
5. 随机森林的应用场景
随机森林广泛应用于各种分类和回归问题,尤其是数据维度较高、样本量较大的情况。比如:
-
医学:预测患者是否患有某种疾病。
-
金融:预测用户是否会违约。
-
生态学:根据环境数据预测物种分布。
6. 举个例子:随机森林就像一群小老师
想象一下,随机森林就像一群小老师,任务是通过考试预测学生是否能通过考试:
-
随机分组:每个小老师随机选择一部分学生进行辅导。
-
独立判断:每个小老师根据自己的学生,独立判断学生是否能通过考试。
-
投票决定:根据大多数小老师的意见,得出最终结论。
7. 随机森林的类别划分
随机森林属于以下几种类别:
(1)有监督学习
-
特点:需要“老师”提供标签(正确答案)。
-
例子:训练随机森林时,我们需要提供一些学生的数据(学习时间、平时成绩)以及他们是否通过考试的结果(通过/不通过)。
(2)集成学习
-
特点:通过组合多个模型,得到更好的结果。
-
例子:随机森林通过组合多个决策树的结果,提高分类和回归的准确性。
(3)Bagging
-
特点:一种集成学习方法,通过随机采样训练多个模型。
-
例子:随机森林通过Bootstrap采样训练多个决策树。
8. 总结
-
随机森林 是一种用于分类和回归问题的机器学习模型。
-
它的核心思想是通过 多个决策树 的投票或平均,得到更准确的结果。
-
它适合处理 高维数据 和 大样本数据。
-
它属于 有监督学习、集成学习 和 Bagging。
梯度提升机(GBM:Gradient Boosting Machine)
属于有监督学习、集成学习、Boosting。
- GBDT:梯度提升决策树(Gradient Boosting Decision Trees, GBDT)是一种算法,更具体地指向使用梯度提升技术训练的决策树模型。这个术语在学术文献和一些特定工具中较为常见。
- GBM:梯度提升机(Gradient Boosting Machine,GBM)可以是一个更通用的术语,有时用于指代任何基于梯度提升原理的机器学习模型,而不仅仅是决策树。然而,在很多情况下,它也被用作GBDT的同义词。
梯度提升机(GBM)VS 随机森林(RF)
1. 什么是梯度提升机(GBM)?
梯度提升机(GBM)是一种用来解决 分类和回归问题 的机器学习模型。它的核心思想是通过 逐步改进 的方式,组合多个“弱模型”(通常是决策树),最终得到一个强大的模型。
这里首先需要明确的是,GBM和RF的底层核心都是决策树(通常是决策树)。但是在使用决策树上,二者有明显区别。
- 构建方式:GBM 构建模型时,决策树是 “串联” 工作的。先有一棵决策树进行预测,得出的结果如果有偏差,下一棵决策树就针对这些偏差进行修正。比如预测学生考试成绩是否优秀,第一棵决策树预测出部分学生成绩情况后,发现有些预测错了,第二棵决策树就重点关注这些预测错的学生,根据其他特征重新判断,不断迭代让预测越来越准。而随机森林里的决策树是 “并联” 的,每棵决策树都是独立进行预测。还是以预测学生成绩为例,每棵决策树都根据自己选择的特征来预测哪些学生成绩优秀,最后把所有决策树的预测结果进行投票,票数多的那个预测结果就是随机森林的最终判断。
- 训练数据:GBM 每次训练新的决策树时,会更关注之前决策树预测错误的数据,给错误数据更高的权重,相当于重点 “攻克” 那些难预测的数据。随机森林在训练时,是从原始数据集中有放回地随机抽取数据,形成不同的训练子集,每棵决策树基于不同的子集训练,这样能让每棵树学到的数据特征更有差异。
- 模型效果:GBM 因为不断迭代修正错误,所以对数据细节的捕捉能力较强,在处理复杂数据关系时可能表现更好,但也容易过拟合。比如数据里一些细微的噪声也可能被当作重要特征学习,导致模型在新数据上表现变差。随机森林因为是综合多棵树的投票结果,相对更稳健,不容易过拟合。即使某棵树因为训练数据的问题出现错误预测,也不太会影响整体结果,在数据比较复杂且存在噪声的情况下,能保持较好的泛化能力 。
2. 梯度提升机的核心思想
GBM的核心思想是 Boosting,也就是通过 逐步改进 的方式,让模型越来越准确。
关键概念:
-
弱模型:一个简单的模型(比如决策树),它的表现可能不太好,但可以作为基础。
-
残差:模型的预测值与真实值之间的差异。
-
逐步改进:每次训练一个新模型,专注于纠正前一个模型的错误。
3. 梯度提升机的工作原理
GBM的工作原理可以分为以下几个步骤:
(1)初始化模型
GBM首先用一个简单的模型(比如平均值)对数据进行初步预测。
(2)计算残差
GBM计算当前模型的预测值与真实值之间的差异(残差)。
(3)训练新模型
GBM训练一个新模型(通常是决策树),专注于预测残差。
(4)更新模型
GBM将新模型的预测结果加到当前模型上,逐步改进预测效果。
(5)重复迭代
GBM重复上述步骤,直到模型的性能不再明显提升。
4. 梯度提升机的数学原理
虽然GBM涉及一些数学知识,但我们可以用简单的语言来解释。
(1)损失函数
GBM通过 损失函数 来衡量模型的预测误差。目标是让损失函数的值最小。
(2)梯度下降
GBM使用 梯度下降法 来优化模型。每次迭代,GBM都会计算损失函数的梯度,并根据梯度调整模型。
(3)Boosting
GBM通过 Boosting 的方式,逐步改进模型。每次迭代,GBM都会训练一个新模型,专注于纠正前一个模型的错误。
5. 梯度提升机的应用场景
GBM广泛应用于各种分类和回归问题,尤其是数据维度较高、样本量较大的情况。比如:
-
金融:预测用户是否会违约。
-
医学:预测患者是否患有某种疾病。
-
推荐系统:根据用户行为预测用户喜好。
6. 举个例子:GBM就像逐步改进考试成绩
想象一下,GBM就像一位老师,任务是通过逐步改进,提高你的考试成绩:
-
初步预测:老师先用一个简单的模型(比如平均值)预测你的成绩。
-
发现错误:老师计算你的预测成绩与实际成绩之间的差异(残差)。
-
针对性改进:老师针对你的错误,教你改正。
-
逐步提高:通过多次改进,你的成绩会越来越好。
7. 梯度提升机的类别划分
GBM属于以下几种类别:
(1)有监督学习
-
特点:需要“老师”提供标签(正确答案)。
-
例子:训练GBM时,我们需要提供一些学生的数据(学习时间、平时成绩)以及他们的考试成绩。
(2)集成学习
-
特点:通过组合多个模型,得到更好的结果。
-
例子:GBM通过组合多个决策树的结果,提高分类和回归的准确性。
(3)Boosting
-
特点:通过逐步改进的方式,让模型越来越准确。
-
例子:GBM通过多次迭代,逐步改进模型的预测效果。
8. 总结
-
梯度提升机(GBM) 是一种用于分类和回归问题的机器学习模型。
-
它的核心思想是通过 逐步改进 的方式,组合多个“弱模型”,最终得到一个强大的模型。
-
它适合处理 高维数据 和 大样本数据。
-
它属于 有监督学习、集成学习 和 Boosting。
-
LightGBM、XGBoost 和 CatBoost 是GBM的变种,分别在速度、性能和类别特征处理上进行了优化。
LightGBM:Light Gradient Boosting Machine
特点:LightGBM是GBM的高效实现,专注于 速度和内存优化。
优点:训练速度快,适合大规模数据。
假如你要整理一个有几百万本书的超级大图书馆,普通方法费时间又占地方。LightGBM 就像高效图书整理机器人,它用特殊方法(直方图算法、单边梯度采样(GOSS)、互斥特征捆绑(EFB))先快速分大类,再细致整理,像直方图算法(将连续的特征值离散化到有限个区间、例如0 - 100,我们可以将其离散化到 10 个区间:0-10、10-20......)可高效分组处理数据,训练快且占内存少。
XGBoost:eXtreme Gradient Boosting
特点:XGBoost是GBM的扩展版本,加入了 正则化 和 并行计算。
优点:性能强大,适合各种机器学习任务。
把 XGBoost 看成更厉害的图书整理专家团队。他们整理时会有 “规则限制”,如规定每类书数量上限,保证分类合理,这就是正则化。团队还能分组同时整理不同区域书籍,即并行计算。在预测用户是否购买商品、房价具体数值等任务中,它都表现出色,所以在 Kaggle 竞赛很受欢迎。
Catboost:Categorical Boosting
特点:CatBoost专注于处理 类别特征,无需手动编码。
优点:对类别特征的支持非常好,适合处理包含大量类别特征的数据。
图书馆里书有各种分类标签,普通整理需手动编号转换,很麻烦。CatBoost 像神奇图书分类精灵,不用你手动处理分类标签,它能自己识别并根据标签特点合理分类书籍。当数据含大量类别特征时,它能轻松应对。
多层感知机(MLP:Multilayer Perceptron)
属于有监督学习、单模型、神经网络。
也叫人工神经网络,(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构
1. 什么是多层感知机(MLP)?
多层感知机(MLP)是一种 神经网络模型,用来解决 分类和回归问题。它的核心思想是通过 多层神经元 的组合,学习数据中的复杂模式。
举个例子:
假设你想预测一个学生是否能通过考试(通过/不通过),MLP可以通过分析学生的“学习时间”“平时成绩”“睡眠时间”等多个特征,做出预测。
2. 多层感知机的核心思想
MLP的核心思想是模仿人脑的神经元,通过 多层神经元 的组合,逐步提取数据的特征,最终做出预测。
关键概念:
-
神经元:MLP的基本单元,接收输入并产生输出。
-
层(Layer):MLP由多个层组成,包括输入层、隐藏层和输出层。
-
激活函数:用来引入非线性,让模型能够学习复杂的模式。
3. 多层感知机的工作原理
MLP的工作原理可以分为以下几个步骤:
(1)输入层
输入层接收原始数据(比如学习时间、平时成绩、睡眠时间)。
(2)隐藏层
隐藏层通过 加权求和 和 激活函数,逐步提取数据的特征。隐藏层可以有多层,每层包含多个神经元。
(3)输出层
输出层根据隐藏层的输出,生成最终的预测结果(比如通过/不通过)。
(4)训练过程
MLP通过 反向传播算法 和 梯度下降法,逐步调整神经元的权重,使模型的预测结果越来越准确。
4. 多层感知机的数学原理
虽然MLP涉及一些数学知识,但我们可以用简单的语言来解释。
(1)加权求和
每个神经元接收输入,并计算加权和:
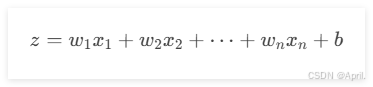
-
w1,w2,…,wn 是权重。
-
x1,x2,…,xn 是输入。
-
b 是偏置。
(2)激活函数
激活函数引入非线性,常用的激活函数有 ReLU 和 Sigmoid:
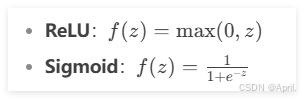
(3)损失函数
MLP通过 损失函数 来衡量预测值与真实值之间的差异。目标是让损失函数的值最小。
(4)反向传播
MLP通过 反向传播算法 计算损失函数的梯度,并根据梯度调整神经元的权重。
5. 多层感知机的应用场景
MLP广泛应用于各种分类和回归问题,尤其是数据维度较高、模式复杂的情况。比如:
-
图像分类:判断一张图片是猫还是狗。
-
语音识别:将语音信号转换为文字。
-
金融预测:预测股票价格。
6. 举个例子:MLP就像多层筛子
想象一下,MLP就像一组多层筛子,任务是通过逐步筛选,找出最有用的信息:
-
输入层:把原始数据(比如学习时间、平时成绩、睡眠时间)倒入第一层筛子。
-
隐藏层:每层筛子都会过滤掉一些无关信息,提取出有用的特征。
-
输出层:最后一层筛子根据提取的特征,做出最终预测(通过/不通过)。
7. 多层感知机的类别划分
MLP属于以下几种类别:
(1)有监督学习
-
特点:需要“老师”提供标签(正确答案)。
-
例子:训练MLP时,我们需要提供一些学生的数据(学习时间、平时成绩、睡眠时间)以及他们是否通过考试的结果(通过/不通过)。
(2)单模型
-
特点:MLP是一个独立的模型,不需要组合其他模型。
-
例子:MLP可以直接用来分类数据,不需要像随机森林那样组合多棵决策树。
(3)神经网络
-
特点:MLP是一种神经网络模型,模仿人脑的神经元。
-
例子:MLP通过多层神经元的组合,学习数据中的复杂模式。
8. 总结
-
多层感知机(MLP) 是一种用于分类和回归问题的神经网络模型。
-
它的核心思想是通过 多层神经元 的组合,逐步提取数据的特征,最终做出预测。
-
它适合处理 高维数据 和 复杂模式。
-
它属于 有监督学习、单模型 和 神经网络。
机器学习常用模型的介绍结束!!
“如果你曾为模型选择纠结、为算法原理头疼,今天就是终结这些痛苦的时刻!本文的框架图和解析,已帮你把机器学习的核心逻辑浓缩成一把万能钥匙。
-
点赞 👉 标记你的“机器学习段位升级日”;
-
转发 👉 拯救那个还在模型迷宫里挣扎的队友;
-
关注 👉 解锁更多代码级干货(下期预告:《模型调参黑科技:让速度和准确率飙升的5个魔鬼细节》)。
📌 彩蛋福利: 评论区回复“我要框架图”或者私信作者,免费领取高清知识脉络导图+模型对比速查表(独家整理,禁止外传)!
知识拓展
下面是对其他模型的简要概述,可根据具体需求对相应模型对话AI进行更加深入的了解。
1. 线性回归
核心思想:通过一条直线来拟合数据,预测一个连续的数值。
例子:根据房屋面积预测房价。
工作原理:找到一条直线,使得所有数据点到这条直线的距离最小。其实质就是在一定程度上是在寻找一组权重用于预测。
2. 逻辑回归
核心思想:通过S形函数(Sigmoid函数)预测概率,用于分类问题。
例子:预测学生是否能通过考试。
工作原理:计算输入特征的线性组合,通过Sigmoid函数转换为概率。
3. 线性模型
核心思想:通过线性方程来建模数据。
例子:预测销售额与广告投入的关系。
工作原理:找到一组权重,使得模型的预测值与真实值最接近。
4. Lasso
核心思想:在线性回归中加入L1正则化,防止过拟合。
例子:预测房价时,自动选择最重要的特征。例如将房间数量对应权重置0。
工作原理:在损失函数中加入权重的绝对值,鼓励稀疏性。
5. Ridge
核心思想:在线性回归中加入L2正则化,防止过拟合。
例子:预测房价时,限制权重的大小。例如房龄影响太大,其权重应该设定在一个范围内。
工作原理:在损失函数中加入权重的平方和,限制权重的大小。
6. LDA(线性判别分析)
核心思想:找到一个投影方向,使得不同类别的数据尽可能分开。
例子:根据学生的成绩和出勤率,判断他们是否能通过考试。
工作原理:最大化类间距离,最小化类内距离。其实质就是在一定程度上是在寻找一组权重用于分类。
7. k近邻(k-NN)
核心思想:根据“邻居”的标签预测当前数据的标签。
例子:根据邻居的喜好,预测新搬来的同学喜欢什么。
工作原理:找到k个最近的数据点,根据它们的标签进行投票。
8. 决策树
核心思想:通过一系列“是/否”问题做决策。
例子:判断一个人是否适合打篮球。
工作原理:根据特征的值,逐步分裂数据,直到达到叶节点。
9. C5.0 和 CART
核心思想:决策树的不同算法,用于分类和回归。
例子:C5.0用于分类,CART用于分类和回归。
工作原理:C5.0用信息增益选择特征,CART用基尼系数。(DecisionTreeClassifier默认是CART)
10. 感知机
核心思想:一种简单的二分类模型。
例子:判断一张图片是猫还是狗。
工作原理:通过加权求和和激活函数,输出分类结果。
11. 神经网络
核心思想:模仿人脑的神经元,通过多层神经元的组合学习复杂模式。
例子:图像分类、语音识别。
工作原理:通过输入层、隐藏层和输出层,逐步提取特征。
12. 支持向量机(SVM)
核心思想:找到一个最优分界线,将不同类别的数据分开。
例子:判断一封邮件是否是垃圾邮件。
工作原理:最大化间隔,找到支持向量。
13. GBDT(梯度提升决策树)
核心思想:通过逐步改进的方式,组合多个决策树。
例子:预测用户是否会点击广告。
工作原理:每次训练一个新模型,专注于纠正前一个模型的错误。
14. AdaBoost
核心思想:通过逐步调整错误样本的权重,让模型更关注难分类的数据。
例子:考试前先复习错题,再复习其他题目。
工作原理:每次迭代,增加错误样本的权重。
15. XGBoost
核心思想:GBDT的扩展版本,加入正则化和并行计算。
例子:在Kaggle竞赛中用于分类和回归问题。
工作原理:通过Boosting和正则化,提高模型的性能。
16. LightGBM
核心思想:GBM的高效实现,专注于速度和内存优化。
例子:处理大规模数据,预测用户行为。
工作原理:通过直方图算法和Leaf-wise生长策略,提高训练速度。
17. CatBoost
核心思想:专注于处理类别特征,无需手动编码。
例子:预测用户是否会购买某件商品。
工作原理:自动处理类别特征,减少预处理步骤。
18. 随机森林
核心思想:通过多个决策树的投票或平均,得到更准确的结果。
例子:预测患者是否患有某种疾病。
工作原理:随机采样和随机特征选择,训练多个决策树。
19. k-means
核心思想:把数据分成k个类别。
例子:根据顾客的购物金额和频率,将顾客分为不同群体。
工作原理:通过迭代优化,找到k个中心点。
20. 层次聚类
核心思想:生成树状的聚类结构。
例子:生物学家用层次聚类分析不同物种的进化关系。
工作原理:通过合并或分裂,生成聚类树。
21. 谱聚类
核心思想:通过图论的方法进行聚类。
例子:社交网络中的社区发现。
工作原理:构建相似度矩阵,通过特征向量进行聚类。
22. PCA(主成分分析)
核心思想:将高维数据压缩到低维,保留主要信息。
例子:把一张100x100像素的图片压缩成10个关键特征。
工作原理:通过特征值分解,找到主要成分。
23. SVD(奇异值分解)
核心思想:将矩阵分解为三个矩阵的乘积,用于降维和推荐系统。
例子:电影推荐系统。
工作原理:通过矩阵分解,提取潜在特征。
24. EM算法
核心思想:通过迭代优化,估计模型参数。
例子:估计混合高斯模型的参数。
工作原理:交替进行期望步骤和最大化步骤。
举个例子:EM算法就像调整收音机
初始化参数:你随便调到一个频道(初始参数)。
E-step:你听一下这个频道的声音质量(计算期望值)。
M-step:你根据听到的声音质量,调整收音机的频率(更新参数)。
重复迭代:你反复调整,直到找到最清晰的频道(参数收敛)。
25. MCMC(马尔可夫链蒙特卡罗)
核心思想:通过随机采样,估计复杂分布。
例子:贝叶斯推断中的参数估计。
工作原理:构建马尔可夫链,进行随机采样。
举个例子:假设你想知道一个湖的平均深度,但湖的形状非常复杂,无法直接测量。MCMC 就像一艘小船,随机在湖面上游走,通过测量每个点的深度,最终估计出整个湖的平均深度。
26. 朴素贝叶斯
核心思想:基于贝叶斯定理,假设特征之间相互独立。
例子:判断一封邮件是否是垃圾邮件。
工作原理:计算条件概率,选择最大概率的类别。
27. 贝叶斯网络
核心思想:用图模型表示变量之间的条件依赖关系。
例子:医疗诊断系统。
工作原理:通过有向无环图,表示变量之间的关系。
28. CRF(条件随机场)
核心思想:用于序列标注问题的概率图模型。
例子:自然语言处理中的词性标注。*假设你有一句话:“我喜欢吃苹果。” CRF 的任务是给每个词标注词性,比如“我”(代词)、“喜欢”(动词)、“吃”(动词)、“苹果”(名词)。
工作原理:通过条件概率,建模序列数据。
特点:标签预测是全局的,考虑整个序列的标签依赖关系。(与最大熵模型的区别)
29. HMM(隐马尔可夫模型)
核心思想:用于处理序列数据的概率模型。
例子:语音识别。(识别一段语音最有可能对应的文字)
工作原理:通过状态转移和观测概率,建模序列数据。
30. 最大熵模型
核心思想:在满足约束条件的情况下,选择熵最大的模型(最均匀的分布)。
例子:自然语言处理中的词性标注。
工作原理:通过最大化熵,选择最均匀的分布。
特点:每个词的标签预测是独立的,不考虑标签之间的依赖关系。(与CRF的区别)
举个例子:最大熵模型 vs CRF
假设我们有一句话:“我喜欢吃苹果。”
(1)最大熵模型
-
预测方式:
-
对于“我”,模型只考虑“我”的上下文信息(比如“我”在句首),预测“我”是代词。
-
对于“喜欢”,模型只考虑“喜欢”的上下文信息(比如“喜欢”前面是“我”),预测“喜欢”是动词。
-
对于“吃”,模型只考虑“吃”的上下文信息(比如“吃”前面是“喜欢”),预测“吃”是动词。
-
对于“苹果”,模型只考虑“苹果”的上下文信息(比如“苹果”前面是“吃”),预测“苹果”是名词。
-
-
结果:模型可以正确预测每个词的词性,但没有考虑标签之间的依赖关系。
(2)CRF
-
预测方式:
-
对于“我”,模型不仅考虑“我”的上下文信息,还考虑“我”后面是“喜欢”(动词),预测“我”是代词。
-
对于“喜欢”,模型不仅考虑“喜欢”的上下文信息,还考虑“喜欢”前面是“我”(代词),后面是“吃”(动词),预测“喜欢”是动词。
-
对于“吃”,模型不仅考虑“吃”的上下文信息,还考虑“吃”前面是“喜欢”(动词),后面是“苹果”(名词),预测“吃”是动词。
-
对于“苹果”,模型不仅考虑“苹果”的上下文信息,还考虑“苹果”前面是“吃”(动词),预测“苹果”是名词。
-
-
结果:模型不仅正确预测每个词的词性,还考虑了标签之间的依赖关系。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









