



 本文介绍了如何使用Python爬虫自动化获取学校教务处信息,包括使用requests进行网页请求,分析页面数据接口,利用selenium处理动态加载内容,以及在爬虫过程中遇到的登录、定位元素、切换iframe和获取cookie等问题的解决方法。
本文介绍了如何使用Python爬虫自动化获取学校教务处信息,包括使用requests进行网页请求,分析页面数据接口,利用selenium处理动态加载内容,以及在爬虫过程中遇到的登录、定位元素、切换iframe和获取cookie等问题的解决方法。
文章目录
requests部分
明确需求
每次打开教务处网页实在是太麻烦了,要输入账号密码,然后登陆,最后再查询,上了大学以后就变得很懒了,所以我想写一段爬虫,可以很快地获取到我想要得到的内容。于是我有了如下需求:
- 输入“成绩查询”就可以得到相关数据,其余类似
- 爬虫自动化
- 以字典的形式返回数据
分析页面
目标网址
# 接下来的分析以“我的考试安排”为例,其余的处理很相似
url = "http://ehall.xjtu.edu.cn/jwapp/sys/studentWdksapApp/*default/index.do?amp_sec_version_=1&gid_=d1FSamp2Y2tzcmhLREI1UnBSZ2FUS0FiRHBTUS9SMkJJaFdZU2E5SnFCcnM4UWpRKzNHWExFSVZHRzJwL2wrbkxKdzN2eFJGRjhJWGF5dFkyMytUaVE9PQ&EMAP_LANG=zh&THEME=cherry#/wdksap"
页面分析
- 实现步骤:
- 首先我们点击右键,查看网页源代码,发现源代码内根本没有相关内容,这说明这个页面是由ajax渲染加载的,所以我们直接对这个页面的网址发送请求没有任何意义。
- 接下来我们需要寻找数据接口,打开“F12",寻找数据接口,通过preview发现了有一个网址有我想要的元素
url = "http://ehall.xjtu.edu.cn/jwapp/sys/studentWdksapApp/modules/wdksap/wdksap.do"

- 用requests请求访问,获取数据,处理数据
以上就是整个分析过程,我们终于获得了实际接口,并确定了爬取方式,接下来只需要很简单地写一段代码获取数据就行了。
爬取数据
我们需要用到requests中的post方法,所以切记:要带上data,否则请求会失败的。
import requests
import json
req = requests.session()
data = {'XNXQDM': '2020-2021-2',
'*order': '-KSRQ,-KSSJMS'}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'}
rep=req.post('http://ehall.xjtu.edu.cn/jwapp/sys/studentWdksapApp/modules/wdksap/wdksap.do', data=data,
headers=headers)
content = rep.text
content = json.loads(content)
如果只是这么一段程序一定会报错的,报错如下:
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
这说明我们没有正确的获取到文本内容,返回去检查,如果我们打印出文本内容,会发现它和我们预期的完全不一样,内容有关于账号输入错误等等。根据这点提示我们可以想到:我们需要携带我们的登录信息,即加入cookie。
cookie如下:
Cookie: EMAP_LANG=zh; THEME=cherry; _WEU=0y8mOygQIDkyLBngGULcuv53LsbNzAi0XIqwXTOqJpfaCSB*JYPGxD5NINbhuNohVfospXNT76k5AcfBHIl2IxX3drQStkcyOgMrTP0VUr9JuPnMqSSp8j..; CASTGC=LQhyOrYKNl6UPpZ+qWQbBWVavdqe3K1VwXarvrBsEKvcRdFhFnqQaw==; MOD_AMP_AUTH=MOD_AMP_ec3f74e5-52af-4410-b6bf-89fd5971a00e; route=ab22dc972e174017d573ee90262bcc96; asessionid=c73fb5c1-4a72-40fe-a419-0fda107aa153; amp.locale=undefined; JSESSIONID=znWPu7n2I7JAjlgGNE779Tzbu03-HMqqURcM9Vb921mesC58rsHY!596962737
经过反复验证,我们发现网站实际上验证的是_WEU和MOD_AMP_AUTH两项,删除其余内容只保留这两个,并加入cookie中,即可获取数据。
import requests
import json
req = requests.session()
data = {'XNXQDM': '2020-2021-2',
'*order': '-KSRQ,-KSSJMS'}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'cookie':'_WEU=0y8mOygQIDkyLBngGULcuv53LsbNzAi0XIqwXTOqJpfaCSB*JYPGxD5NINbhuNohVfospXNT76k5AcfBHIl2IxX3drQStkcyOgMrTP0VUr9JuPnMqSSp8j..;MOD_AMP_AUTH=MOD_AMP_ec3f74e5-52af-4410-b6bf-89fd5971a00e'}
rep=req.post('http://ehall.xjtu.edu.cn/jwapp/sys/studentWdksapApp/modules/wdksap/wdksap.do', data=data,
headers=headers)
content = rep.text
# 下边的是简单的数据处理
content = json.loads(content)
dic = {}
for i in range(len(content['datas']['wdksap']['rows'])):
classroom = content['datas']['wdksap']['rows'][i]['JASMC']
class_name = content['datas']['wdksap']['rows'][i]['KCM']
teacher = content['datas']['wdksap']['rows'][i]['ZJJSXM']
time = content['datas']['wdksap']['rows'][i]['KSSJMS']
dic['teacher'] = teacher
dic['classroom'] = classroom
dic['time'] = time
print(dic)
输出结果如下:

程序优化(自动化过程)
通过上边的代码我们初步实现了获取考试安排中的相关数据,但与我们刚开始的要求不相符合,整个过程并非自动化的,尽管cookie携带的登录信息可以保持一段时间,但终究太短了,几天后想要获取数据,又得重新登陆获取cookie,手动修改程序,可等做完这些,回头一看,那我要这一段代码有啥用?
所以,我们需要做出一个简单的改变——动态地替换cookie,问题来了哈,这玩意儿咋生成的?我们有两种思路:
- 通过JS逆向破解出cookie的生成方式,然后用python实现,最后就没任何难度了,生成cookie,访问网站,获取信息,一气呵成!
可问题是:咋破解?我的技术目前还很差,JS逆向基本零基础,尽管有自学一段时间,可到头来啥也不会,这个方法应该是指望不上了。 - 通过selenium获取cookie,然后动态的替换,这似乎很简单,也很方便,感觉可行,于是我选择了这个方法,于是我走向了一条不归路。
selenium的整个实现过程
这四个步骤第一和第三步让我吃尽了苦头,下边我们来一步一步看会遇到什么问题(反正我真的很头秃)
对页面发送请求
这一步真的很简单,死代码,但是就是这一步让我吃尽苦头,大家且看:
url = 'http://ehall.xjtu.edu.cn'
driver = webdriver.Chrome()
driver.get(url=url)
这一步不应该有问题,可是等到后边的操作时,我们就会发现一个很让人难受的情况,至少我在网上没找到类似的情况,着实令人头秃。
输入账号密码
driver.implicitly_wait(1000)
driver.find_element_by_id('ampHasNoLogin').click()
driver.implicitly_wait(1000)
driver.find_element_by_class_name('username').send_keys('你的用户名')
driver.find_element_by_class_name('pwd').send_keys('你的密码')
driver.find_element_by_id('account_login').click()
我们成功登进去了!
点击进入相应页面

我们需要定位到这个元素,这个时候有一个class,我们如果直接定位的话你会发现根本无法正常定位,因为后边的那一部分是一个动态替换的Id,如果能破解出来的话,那为什么要用selenium呢?我直接破解获取cookie不香吗?
这里我们可以用XPath来定位:
driver.find_element_by_xpath(
'//*[@id="widget-recommendAndNew-01"]/div[1]/widget-app-item[3]/div/div/div[2]/div[1]').click()
问题一:定位元素失败
现在你点run试试,反正总会报错的,它会弹出一个错误:
NoSuchElementException: Message: no such element: Unable to locate element
反正就是用不了,无论如何不管用什么方式它都会弹出这个错误,而且,我可以肯定这个xpath是对的。
我去网上查了不少帖子,有很多方法,这里也为大家盘点一下:
- 元素未加载出来
- 可能用了iframe框架,切换框架试试(后边有用到哦)
- 可能是定位方式有误(比如元素少复制了一点内容啊,诸如此类的)
- 动态id,用xpath试试
- 啊我想不起来了,想起来了再加吧,反正就这些原因了
可恨之处就在于,我知道有这几种错误,可它都不对啊,没有一种是符合的。我一度怀疑是selenium的问题,可重装也好,排错也好,永远无法定位。
于是想到会不会是页面内容与看到的不相同呢?
我试着通过标签名<div 获取了一些内容,然后打印出来,惊奇地发现:这根本就不是我看到的页面的源代码!那到底是什么原因呢?
突然,我想到:会不会是我访问的那个网址有问题呢?
# 这是我刚才访问的
url = 'http://ehall.xjtu.edu.cn'
# 我试着把它的完整网址放在里边
url = 'http://ehall.xjtu.edu.cn/new/index.html?browser=no'
还是不行,但是我就是不小心看到了那个browser,如果你把它改成yes,然后去访问,你会发现:成了!问题竟然出在网址上。我反正是没想到。
问题二:切换iframe框架
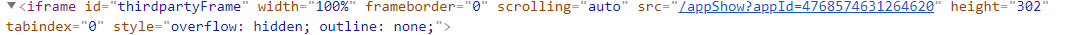
就是这个玩意儿,如果不切换的话,尽管元素近在眼前,你就是定位不到,嘿,气不气?
driver.switch_to.frame('thirdpartyFrame')
切换完毕,定位元素
driver.find_element_by_id('20150808183545465').click()
自此理论上来说,我们应该完成了,接下来进入最后一步,获取cookie。
获取cookie
cookies = driver.get_cookies()
str = ''
for cookie in cookies:
# 简单的拼串,一般来说,cookie中有很多元素,
# 我们只取name和value即可
str = str + (cookie['name'] + '=' + cookie['value'] + ';' + ' ')
然后run,然后出问题了,哈哈哈哈哈哈哈哈哈哈哈,这一刻,我承认,我崩溃了。而且它还不报错,就一直卡在那儿。

我的确切换了iframe框架,也的确定位到了元素(就这一个我还能错了不成?)

就长这样。敢问,我是错哪了呢?
问题三:切换页面
我试着用相同的排错方式,打印出了标签名,然后看里边的内容,发现:它竟然是上个页面的源代码。换句话说:我在上个页面找这个页面的元素,能找到才有鬼了。

但是我为什么没有注意到呢?因为在程序运行的过程中,这个界面是实打实的切换过来了,所以我没有想到,这个页面和程序运行时定位到的页面不一样,更可气的是它不报错。
所以,一定注意:如果打开了一个窗口,一定要加一段代码,让程序知道你要定位的是另一个窗口。
handles = driver.window_handles
for handle in handles:
if handle != driver.current_window_handle:
driver.switch_to.window(handle)
这里注意一下,selenium切换界面的方式有些变化,他们将所有方法都封装在了一个类中,即
# 这是新版的使用方式
driver.switch_to.window()
# 这是旧版的使用方式
driver.switch_to_window()
# 当你使用的时候会有一道删除线,意味着该方法有问题,所以最好还是
#用新版的吧
问题四:排错方式
前边有一直在提,我通过定位标签的方法得到了一些信息,具体如何怎么操作呢?
div_tags = driver.find_elements_by_tag_name('div')
for div_tag in div_tags:
# 获取元素内的全部HTML
div_tag.get_attribute('innerHTML')
# 获取包含元素的全部HTML
div_tag.get_attribute('innerHTML')
# 获取文字内容
div_tag.get_attribute('textContent')
获取cookie已经说过无需赘述。
最后就很简单了,把cookie保存下来,在requests代码中引用,条件允许的话,设置一个循环时间,让selenium隔一段时间循环一次,保证有最新的cookie。
代码展示
import requests
import json
req = requests.session()
data = {'XNXQDM': '2020-2021-2',
'*order': '-KSRQ,-KSSJMS'}
with open('cookie.txt', 'r') as file_obj:
cookie = file_obj.read()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'cookie': cookie}
rep = req.post('http://ehall.xjtu.edu.cn/jwapp/sys/studentWdksapApp/modules/wdksap/wdksap.do', data=data,
headers=headers)
content = rep.text
content = json.loads(content)
dic = {}
for i in range(len(content['datas']['wdksap']['rows'])):
classroom = content['datas']['wdksap']['rows'][i]['JASMC']
class_name = content['datas']['wdksap']['rows'][i]['KCM']
teacher = content['datas']['wdksap']['rows'][i]['ZJJSXM']
time = content['datas']['wdksap']['rows'][i]['KSSJMS']
dic['teacher'] = teacher
dic['classroom'] = classroom
dic['time'] = time
print(dic)
from selenium import webdriver
class get_cookies():
def __init__(self):
self.url = 'http://ehall.xjtu.edu.cn/new/index.html?browser=yes'
def get_a_cookie(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless')#无头模式
options.add_experimental_option('excludeSwitches', ['enable-automation'])#管理员模式,就是取消那个自动化
options.add_argument('blink-settings=imagesEnabled=false')#不加载图片,就是快
driver = webdriver.Chrome(chrome_options=options)
#可惜我没法用无头模式,一旦用了无头模式就会很慢,我也不知道为啥
driver.get(self.url)
driver.implicitly_wait(1000)
driver.find_element_by_id('ampHasNoLogin').click()
driver.implicitly_wait(1000)
driver.find_element_by_class_name('username').send_keys('xxx')
driver.find_element_by_class_name('pwd').send_keys('xxx')
driver.find_element_by_id('account_login').click()
driver.implicitly_wait(1000)
driver.find_element_by_xpath(
'//*[@id="widget-recommendAndNew-01"]/div[1]/widget-app-item[3]/div/div/div[2]/div[1]').click()
driver.find_element_by_id('ampDetailEnter').click()
handles = driver.window_handles
for handle in handles:
if handle != driver.current_window_handle:
driver.switch_to.window(handle)
driver.switch_to.frame('thirdpartyFrame')
driver.find_element_by_id('20150808183545465').click()
cookies = driver.get_cookies()
div_tags = driver.find_elements_by_tag_name('div')
for div_tag in div_tags:
div_tag.get_attribute('innerHTML')
str = ''
for cookie in cookies:
str = str + (cookie['name'] + '=' + cookie['value'] + ';' + ' ')
# driver.quit()
return str
if __name__ == '__main__':
cookie = get_cookies().get_a_cookie()
with open('cookie.txt', 'w') as file:
file.write(cookie)
可能有不足的地方,但我认为在爬取教务处的整个过程,我见过了几乎所有selenium中可能遇到的问题,并一一解决。
至于一些简单的需求,比如输入什么内容就获取相应的信息,可以选择用字典储存,也可以选择用if语句实现,相对来说很简单,在此就不实现了。
如果你看到了这篇文章,并且它为你提供了哪怕一丢丢的帮助,那也是很好的,也算没有浪费时间了。

















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









