




前言
实验环境:Linux Ubuntu 16.04
1) Java 运行环境部署完成
2) Hadoop单机模式部署完成
一、Yarn模式安装
- 打开命令控制台
- 解压安装包到apps目录下
sudo tar -zxvf /data/hadoop/spark-2.1.3-bin-hadoop2.7.tgz -C /apps/(解压后,在/apps目录下产生spark-2.1.3-bin-hadoop2.7文件夹) - 更改文件名
sudo mv /apps/spark-2.1.3-bin-hadoop2.7/ /apps/spark - 更改所属用户和用户组
sudo chown -R dolphin:dolphin /apps/spark/ - 调出编辑器
sudo leafpad ~/.bashrc - 设置环境变量
export SPARK_HOME=/apps/spark export PATH=$SPARK_HOME/bin:$PATH - 使环境变量生效
source ~/.bashrc - 修改spark配置文件名,使之生效
mv /apps/spark/conf/spark-env.sh.template /apps/spark/conf/spark-env.sh - 打开spark-env.sh文件
sudo leafpad /apps/spark/conf/spark-env.sh - 在最后加入
export JAVA_HOME=/apps/java export SCALA_HOME=/apps/scala export SPARK_MASTER_IP=localhost export HADOOP_HOME=/apps/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop - 使slaves配置文件生效
mv /apps/spark/conf/slaves.template /apps/spark/conf/slaves - 启动Hadoop
/apps/hadoop/sbin/start-all.sh
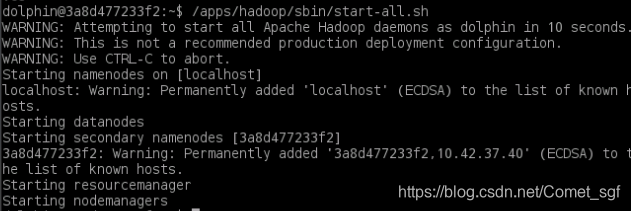
- 启动Spark
/apps/spark/sbin/start-all.sh

- 使用
jps指令查看spark进程情况
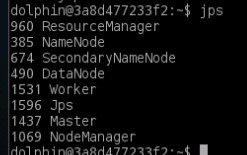
二、Local模式安装
- 打开命令控制台
- 解压安装包到apps目录下
sudo tar -zxvf /data/hadoop/spark-2.1.3-bin-hadoop2.7.tgz -C /apps/(解压后,在/apps目录下产生spark-2.1.3-bin-hadoop2.7文件夹) - 更改文件名
sudo mv /apps/spark-2.1.3-bin-hadoop2.7/ /apps/spark - 更改所属用户和用户组
sudo chown -R dolphin:dolphin /apps/spark/ - 调出编辑器
sudo leafpad ~/.bashrc - 设置环境变量
export SPARK_HOME=/apps/spark export PATH=$SPARK_HOME/bin:$PATH - 使环境变量生效
source ~/.bashrc - 启动Spark shell
spark-shell --master local
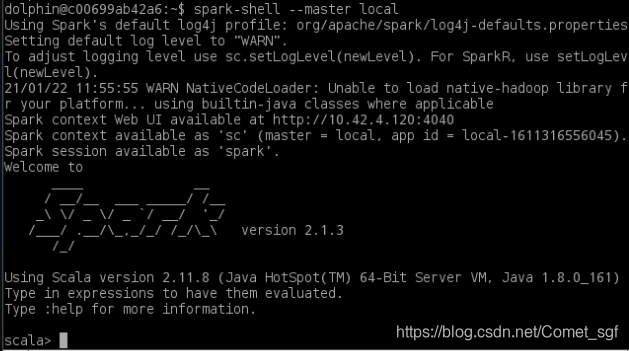
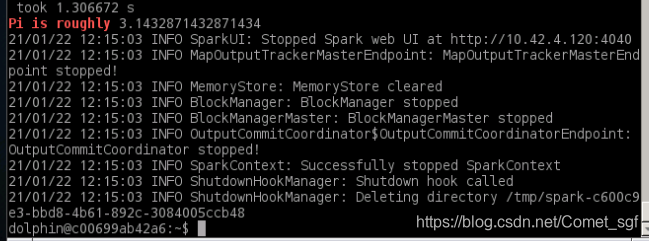
- 重新打开一个控制台,运行案例计算PI值
run-example SparkPi 10 | grep 'Pi is roughly',执行成功,Local版本安装成功。
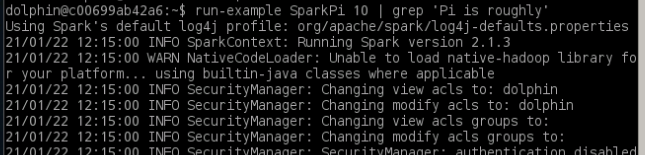
三、Standalone模式安装
- 打开命令控制台
- 解压安装包到apps目录下
sudo tar -zxvf /data/hadoop/spark-2.1.3-bin-hadoop2.7.tgz -C /apps/(解压后,在/apps目录下产生spark-2.1.3-bin-hadoop2.7文件夹) - 更改文件名
sudo mv /apps/spark-2.1.3-bin-hadoop2.7/ /apps/spark - 更改所属用户和用户组
sudo chown -R dolphin:dolphin /apps/spark/ - 调出编辑器
sudo leafpad ~/.bashrc - 设置环境变量
export SPARK_HOME=/apps/spark export PATH=$SPARK_HOME/bin:$PATH - 使环境变量生效
source ~/.bashrc - 进入到config目录下
cd /apps/spark/conf - 修改spark配置文件名,使之生效
mv spark-env.sh.template spark-env.sh - 将slaves.template重命名为slaves
mv slaves.template slaves - 打开spark-env.sh文件
sudo leafpad /apps/spark/conf/spark-env.sh - 在最后加入
export JAVA_HOME=/apps/java export SPARK_MASTER_IP=tools<br> export SPARK_MASTER_PORT=7077
保存退出 - 进入sbin目录
cd /apps/spark/sbin,启动脚本./start-all.sh - 使用
jps指令查看spark进程情况 - 查看本机ip
ifconfig - 输入指令
spark-shell --master spark://x.x.x.x:7077,x.x.x.x表示本机ip - 显示“scala>”表示Standalone模式安装成功。
小结
三种安装方式大同小异,根据具体需要进行选择。下面说一些知识点,供大家参考。
- 高性能,大规模并行系统可用于促进数据准备和建模、部署、业务理解;
- Oozie在Hadoop架构中的主要目的是支持执行一系列行动组成的工作流程;
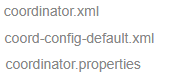
- 协调器作业使用了以下文件
- 时间、数据、对API应用程序的调用、Oozie CLI;
- SparkR定义的聚合函数:sumDistinct,sum,Min,count;
- Spark支持Standalone,On Mesos, On Yarn三种不同类型的部署方式;
- Spark采用RDD后能实现高效计算的原因主要是高效的容错性;中间结果持久化到内存,数据在内存中的多个;存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化;
- Spark运行架构的特点:
- 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留
- Task采用了数据本地性和推测执行等优化机制
- Executor进程以多线程的方式运行Task
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
- Spark特点:运行速度快,容易使用,通用性;


















 1363
1363




 到【灌水乐园】发言
到【灌水乐园】发言







