



这段时间在解析 lnk 文件的时候,发现了 & 0xff 这个神奇的东西,百思不得其解,
看完佬的的分析后,这才明白过来,现将个人理解分享出来,以做参考。
我们先来看一段代码:
package temp;
public class Test {
public static void main(String[] args) {
byte by = -100;
System.out.println(by);
int in = by & 0xff;
System.out.println(in);
}
}
打印的结果会是什么呢?
乍一看,by 是8位的二进制数,而 0xff 转化成8位二进制就是1111_1111,那 by & 0xff 不还是 by 本身吗?
但是打印的结果却是:
-100
156
我们来简单分析下原因:
我们知道,整数在计算机中是以二进制补码表示的,8位二进制的补码能表示的区间是 -128 到 +127,
156 显然超过了这个区间,故这里化成 16 位进行比较,经计算可知:
-100 的补码是 1111_1111_1001_1100
156 的补码是 0000_0000_1001_1100
细心的同学的可能注意到了,这俩的补码,后8位都是一样的,而前8位不是全0就是全1
问题之一就出现在这个补码上!
附:
一、十进进制数的表示
在 Java 中,0x 开头的数字默认被解释为整数类型(int),而不是 byte 或 short 类型。
这是因为 Java 语言规定了整数字面量的默认类型为 int ,即使它们的值可以适应 byte 或 short 类型的范围。
—— CHAT-GPT AI 原话
正因此,我们可以看到在 IDEA 中,把 0xff 赋值给 byte 变量时会爆红,提示我们强转为 byte 类型或改为 int 类型
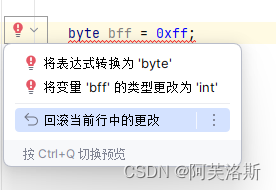
而下面的这段代码,则反映了 0xff 在 Java 中的本质更接近数值 255 而非 8 个 1
package temp;
public class Test2 {
public static void main(String[] args) {
byte bff = (byte) 0xff;
short sff = 0xff;
int iff = 0xff;
long lff = 0xff;
System.out.println(bff);
System.out.println(sff);
System.out.println(iff);
System.out.println(lff);
}
}
输出结果为:
-1
255
255
255
简单分析下:
二进制中的 1111_1111 对应十进制数字 255
但在计算机中,无论是原码还是补码,采用的都是有符号数,即包含负数
在有符号二进数中,原码、反码、补码为 1111_1111 时,
分别表示(十进制的) -127 、0、-1
因此,可以知道,在 Java 中,0xff 是按照无符号数(或者说是非负数)进行解析的,
而存储的时候是按照(有符号数的)补码形式进行存储的,
System.out.println(Integer.toBinaryString(-0x1));
二、& 0xff 的本质
通过上面 AI 的话可以知道,0xff 本质上是一个整数,类型为整型(int),当 by 与 0xff 进行运算时,
属于是 byte 类型与 int 类型进行运算,因此会发生隐式类型转换,
Java 会先将 by 转为整型,再将其与 0xff 进行运算,
而当 by 为负数时,by 前面会补 24 个 1(正数则是补 0)
8位补码:1001_1100
32位补码:1111_1111_1111_1111_1111_1111_1001_1100
而 0xff 是正数,前面刚好是 24 个 0
8位补码:1111_1111
32位补码:0000_0000_0000_0000_0000_0000_1111_1111
根据与 1 不变,与 0 归 0 的运算性质,by 与上 0xff 后,
前 24 位全部 归 0 ,而后 8 位 保持不变!
现在回过头去看 -100 和 156 的补码是不是很清晰了?
以上就是 & 0xff 运算的本质了,吗?
事实上,刚才的解答是存在一定问题的,解释得并不完全,仔细看还是能发现一些不合理的地方,
就比如:0xff 不是整型吗,为什么这行代码中没有类型强转?整数类型直接转 short 应该会报错才对啊
short sff = 0xff;
又比如:0xff 代表 8 个 1,但是在补码中 1111_1111 表示的明明是 -1 啊,为啥说是 255 呢
前面的 4 个 0xff 的代码其实有一定的误导性,
首先明确,数据总是由精度低到精度高方向转换,这一点是没有问题的,如:
byte n1 = 1;
int n2 = n1;
但是反过来则不行,像下面这样就会报错,提示:java : 不兼容的类型 : 从 int 转换到 byte 可能会有损失
int n1 = 1;
byte n2 = n1;
但其实 1 本身也是默认 int 类型的,为啥 byte n1 = 1 就没有报错呢?
这就涉及到一部分知识的盲区了,那就是字面量类型的自动转换
什么是字面量呢?像 12 、-100、3.14 这些就是字面量,
它是一眼就能看出来的量,是直接表示的量,是固定不变的量,
因此,可以理解为字面量就是常量
而诸如:十六进制数 0XD,八进制数 013,二进制数 0B1101,这些都属于字面量
在范围内是字面量是可以自动转换的,如:
package temp;
public class Test3 {
public static void main(String[] args) {
byte bin = -0b111_1111;
byte oct = -0177;
byte dec = -127;
byte hex = -0x7f;
System.out.println(bin);
System.out.println(oct);
System.out.println(dec);
System.out.println(hex);
}
}
byte 类型的范围是 -128 到 +127 ,所以 上面这些 都可以存入 byte 中
另外,值得一提的是,Java 中,小数默认是 double 类型,
而 float 类型转 double 类型(可能)会有精度损失(哪怕是字面量)(具体涉及到进制间的小数转换,这里就不多说了)
因此,小数字面量赋值给 float 类型的时候会报错,就像下面这样:
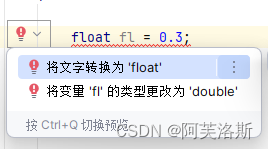
提示:0.3 在二进制中是表示不完的
跑题了……
所以,0xff 的本质就是 255 !在 Java 中,它是字面量,是整型(int)
而字面量可以自动转换类型,因此可以自动转换为 short 类型,
但是由于 255 已经超过了 byte 的表示范围,所以不能自动转换为 byte !
但是可以强转,代价就是丢失精度(抹除高位)!
而 255 的补码后 8 位就是 8 个 1,因为正数的三码是一样的,这就造成 0XFF 等价于 1111_1111 的错觉!
但,是不是只有 8 个 1,那就不一定了,这得取决于它是有符号还是无符号,
无符号的号的话 8 位就够了,所以就是 8 个 1,
而如果是有符号,第一位是符号位,后面真正用于表示的只有 7 位,所以至少要9位,
而 Java 中都是有符号类型,byte 不足以表示 +255,这也就是为什么 0xff 不可以是 byte 类型
关于 0xff 的本质到底是不是 255,以及字面量会不会自动转换,我们可以测试一下:
package temp;
public class Test4 {
public static void main(String[] args) {
byte by = -100;
//byte bt = 255; //报错
short sh = 255;
int in = 255;
long lo = 255;
System.out.println(by & sh);
System.out.println(by & in);
System.out.println(by & lo);
int bin = 0B1111_1111;
int oct = 0377;
int hex = 0XFF;
System.out.println(by & bin);
System.out.println(by & oct);
System.out.println(by & hex);
}
}
上面六个输出结果都是 156
到这里,终于可以正式下结论:
0xFF 的本质就是 255
0xFF 是字面量,在 Java 中是 int 类型,二进制码为 0000_0000_0000_0000_0000_0000_1111_1111
0xFF & byte 变量,在 Java 中,会先将 byte 变量转 int 类型再运算,结果就是原 byte 变量的前 24 位归 0 ,后 8 位不变
三、保证补码的一致性
到这其实没必要写了,也累了,但既然标题已经开了,就简单说下这个的用途吧。
之前已经说了,整数在计算机中都是以补码的形式存储的,
当一个整数在进行向上转型时(短转长),正数补 0 ,负数补 1,
从无符号数的角度看,补 0 是不影响的,如 123 和 00123 是一样的
而补 1 则不一样,这个数已经发生变化了,如 123 和 11123 、22123、33123 都是不一样的
因此,可以通过 &0xff 可以将高的 24 位置为 0,低的 8 位保持原样,&0xffff 则是高 16 位置 0 ,低 16 位不变
这其实并不是补码的锅,而是符号数的影响,而补码甚至还把这一过程简化了,
如果是原码的话,负数的向上转型后,符号位会移动到最高位,相当于从第二位开始补 0,
而补码和反码,都是从头(第一位)开始补 1,
但其实无论那种,从无符号的角度,数据都发生了变化,
原码相当于 123 变成了 100123,补码和反码相当于 123 变成了 999123,
在 Java 等诸多语言中,都没有无符号类型,只能以有符号的代替,
而有符号数的拓展,会导致其对应的无符号数改变,因为这就是有符号数的特性!(除非符号位放在最后)
因此,如果使用有符号数代替无符号数,那么在进行位数扩展时,需要添加 &0xff 这样的运算来保持原样
下面以我们以一个 byte 类型(有符号)转 dword 类型(无符号)的方法为例稍作讲解:
private static int bytesToWord(byte byte1, byte byte2) {
return ((byte2 & 0xff) << 8) | (byte1 & 0xff);
}
在这个方法中,左移操作(<<)和 位或操作(|)都会将 byte 类型向上转位 int 类型(Java 特性),
现在我们知道:在进行有符号转无符号数的拓展时,需要将高位置 0
所以这里都加了 & 0xff(位与也会转型,故右边也需要加)
然后将第二个 byte 左移 8 位,相当于是把第二数作为高位
移位操作会补 0 ,所以不能使用位与运算(&)而应该使用位或运算(|)(使用位与的话就全部归 0 了)
至于小标题说保持补码的一致,倒不如说是保持原始字节(或比特)的一致
同样一段比特,如 1111_1111 作为无符号数,就可以认为是 255,因为他们的映射关系的是简单而直接的,
而若作为有符号数,在原码里是 -127,在反码里是0(负0),在补码里是 -1
但是它本身就是 8 个 1 呀,是们是希望它表示的东西不要变,还是希望它自身不要变呢?
就是 0xff 的所做的(保持自身不变)
但往广了说,终究是保持它的意义不变,如果它不被赋予(其所代表的)意义,那也就没有了变换的必要
只不过,1111_1111 与 255 与的这种对应更加自然而纯粹,我们会自然地觉得它们是绑定在一起的
到这里,& 0xff 的原理终于算是讲完了。没想到这么一点东西,却花了我一个整天时间。
不过,现在终于可以好好睡一觉了。
参考文章:

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









