




 探讨了使用Java删除字符串中重复字符的复杂性,分析了原始算法的缺陷并提出了修正方案,确保所有重复字符都能被正确移除。
探讨了使用Java删除字符串中重复字符的复杂性,分析了原始算法的缺陷并提出了修正方案,确保所有重复字符都能被正确移除。
Java去掉字符串中重复的字符
原方法
package FifthWork;
import java.util.Scanner;
public class FifthWork {
public static void main(String[] args) {
Scanner scan=new Scanner(System.in);
String s=scan.nextLine();
StringBuilder sb=new StringBuilder(s);
for(int i=0;i<sb.length()-1;i++){
for(int j=i+1;j<sb.length();j++){
if(sb.charAt(i)==sb.charAt(j)){
sb.deleteCharAt(j);
}
}
}
System.out.println("new string: "+sb);
}
}
输入
abcabc
输出结果
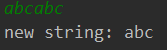
这次结果没有问题,下面是第二次输入:
输入
abcaa
输出结果
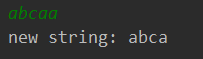
结果发现,与期望并不相符。为什么还有一个a没有被删除?
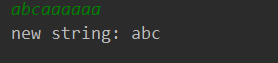
经多次实验,发现输入abcaa(2个a)依次增加a的个数直到abcaaaaa(5个a),结果均为abca。
当输入a的个数为6时,即输入abcaaaaaa,结果为abcaa。
产生这种现象的原因是什么呢?
猜测:deleteCharAt(j)方法会删除字符串中下标为 j 的字符,并将其后的字符下标都向前移了一位。
例如,当删除下标为3的 a 后,本应该下标为4的 a 此时向前移了一位而下标变成3,而此时负责字符串检索的 j 值经过一次循环变成4,就这样跳过了原本下标为4的 a。
解决方法:
每删除一次字符,就将 j 的值减1。
实现代码:
package FifthWork;
import java.util.Scanner;
public class FifthWork {
public static void main(String[] args) {
Scanner scan=new Scanner(System.in);
String s=scan.nextLine();
StringBuilder sb=new StringBuilder(s);
for(int i=0;i<sb.length()-1;i++){
for(int j=i+1;j<sb.length();j++){
if(sb.charAt(i)==sb.charAt(j)){
sb.deleteCharAt(j);
j--;
}
}
}
System.out.println("new string: "+sb);
}
}
再次实验结果





















 9909
9909



 到【灌水乐园】发言
到【灌水乐园】发言







