




🔥博客主页: 我要成为C++领域大神
🎥系列专栏:【C++核心编程】 【计算机网络】 【Linux编程】 【操作系统】
❤️感谢大家点赞👍收藏⭐评论✍️本博客致力于知识分享,与更多的人进行学习交流

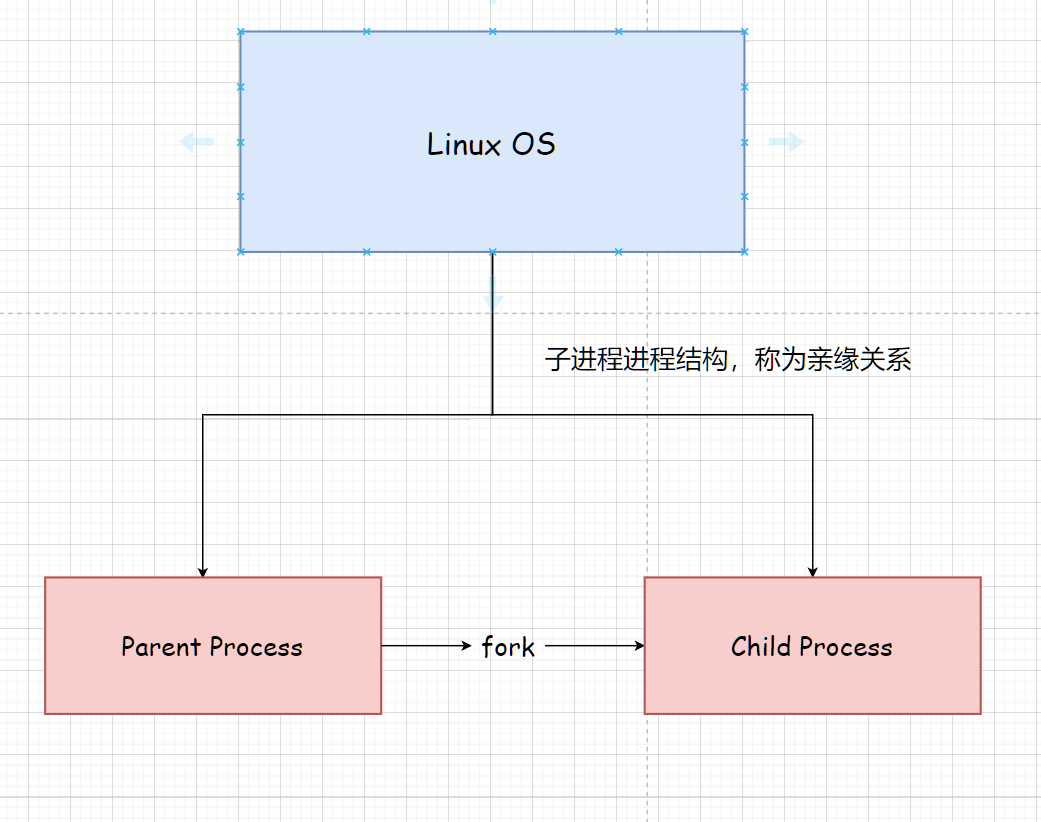
fork() 函数用于创建一个新的进程,该进程称为子进程。原有的进程称为父进程。子进程是父进程的副本,但是它们有不同的进程ID(PID)。
- 返回值:
- 在父进程中,
fork()返回子进程的PID。- 在子进程中,
fork()返回0。- 如果出现错误,
fork()返回一个负值。
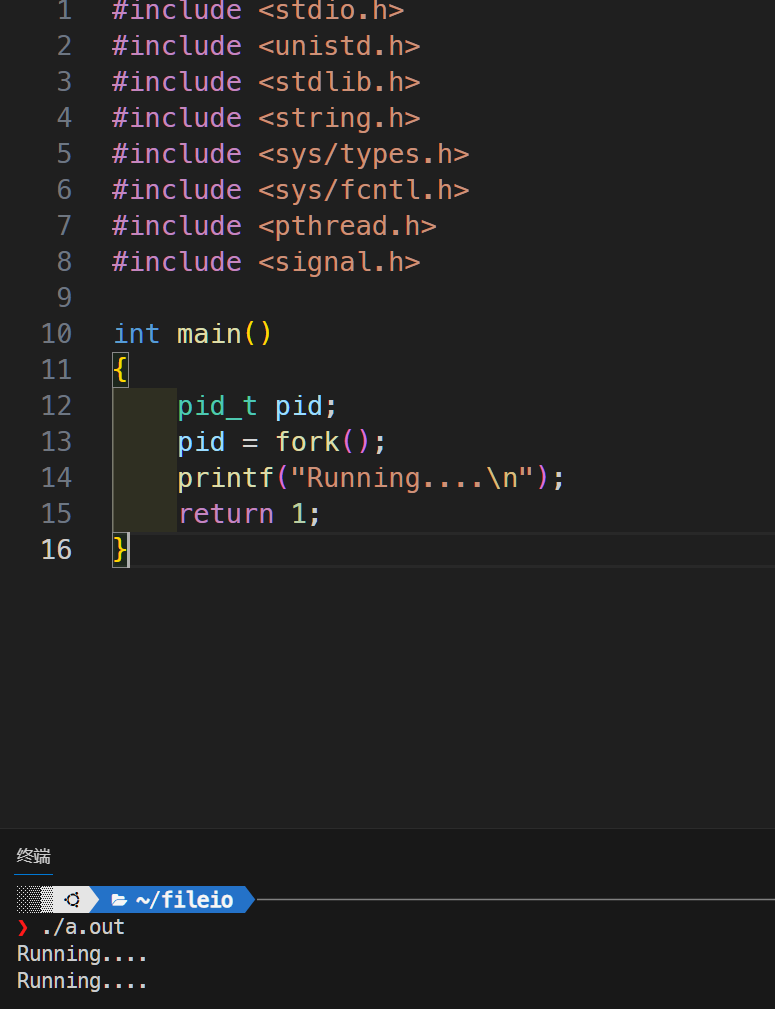
我们写一段demo程序,发现会输出两次Running。fork() 函数被调用一次,导致当前进程(父进程)被复制出一个新的进程(子进程)。子进程会复制父进程的地址空间、寄存器状态,包括父进程的输出缓冲区。因此,父进程和子进程都会继续执行接下来的代码。
这就是为什么会有两次 "Running...." 的输出。一次来自父进程,另一次来自子进程。
如何避免这种现象?
由于fork函数在父进程和子进程都有返回值,如果进程创建成功,那么fork在父进程返回的是子进程的PID,在子进程返回的是0,所以我们可以通过fork返回值来确定是父进程工作区还是子进程工作
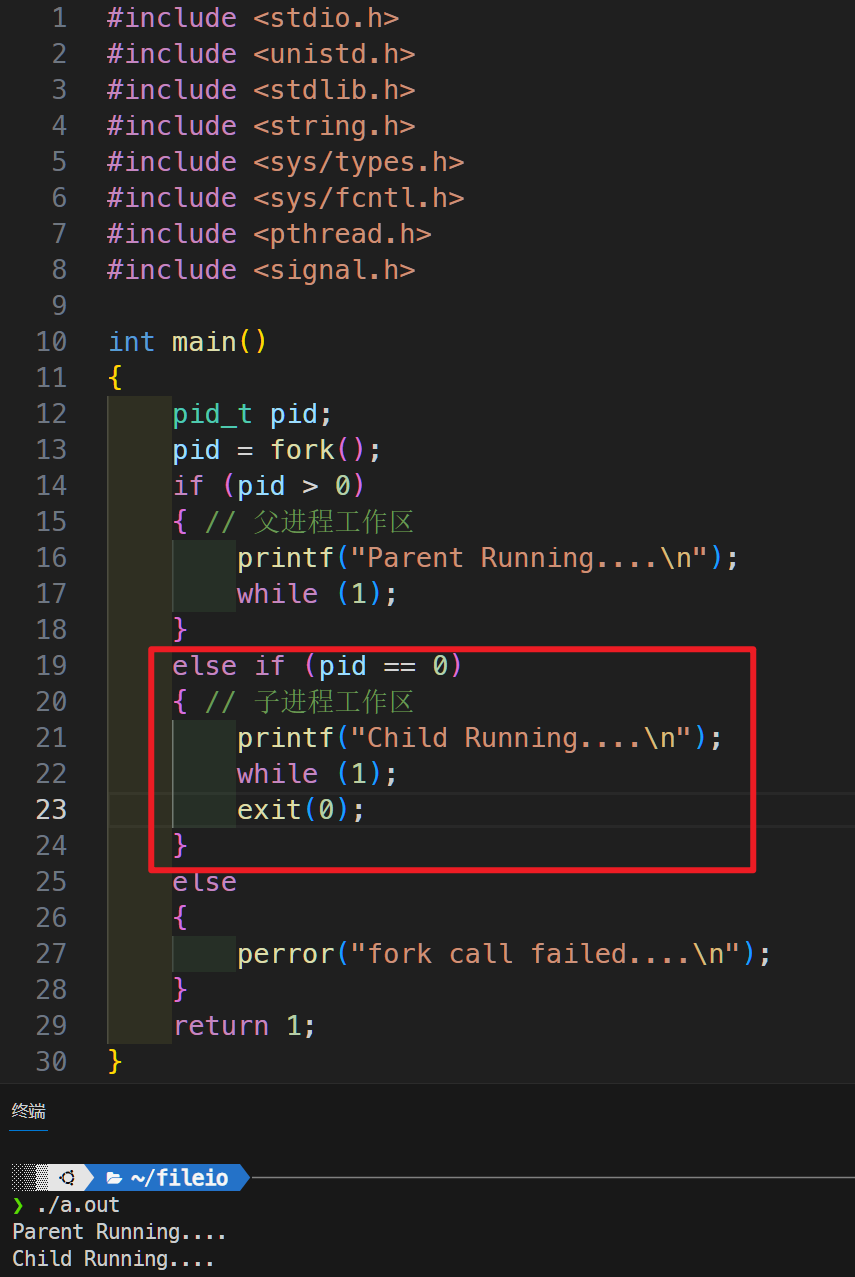
在实际开发中,有一个严格的规定,子进程只能在子进程工作区执行代码,不允许踏出自己的工作区。执行完自己的代码块通过exit()结束进程
init进程
默认情况下所有进程都有父进程,除了init进程,init是系统启动初始化首个服务进程,所有系统下的进程都是它的子集
关于父子进程一起执行fork函数
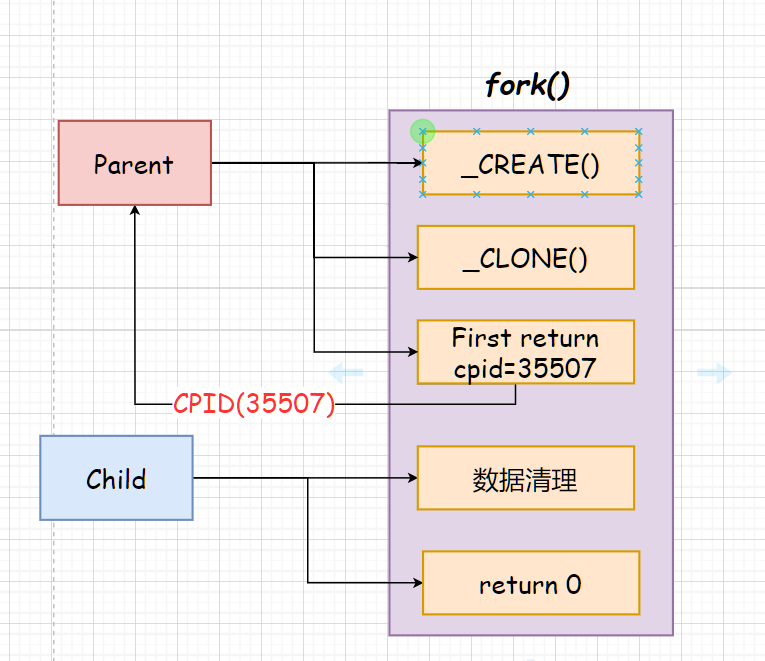
fork函数调用之后,分为多个过程。
先调用_CREATE函数,创建子进程,但是这个子进程的内存空间是空的,所以接下来调用_CLONE函数。
_CLONE函数将父进程的所有内存空间(包括代码段、数据段、堆、栈等)、寄存器状态、文件描述符等克隆给子进程。
执行完克隆操作后,会有第一个返回值,返回给父进程创建的子进程的PID。
之后的操作由子进程进行,数据清理、回收等工作。等所有操作完成后,函数返回0,这也就是为什么fork函数针对父子进程有不同的返回值
父子进程可以共享fork函数栈帧,一人执行函数的一部分,得到两个不同的返回值,便于区分父子进程任务。
多进程创建的模版
通过循环调用fork() 创建多进程(一父多子)。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/fcntl.h>
#include <pthread.h>
#include <signal.h>
int main()
{
pid_t pid;
int i;
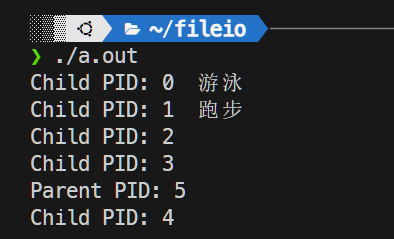
for (i = 0; i < 5; ++i)
{
pid = fork();
if (pid == 0)
break; // 每次创建完一个子进程后,我们让它退出循环
}
if (pid > 0)
{ // 父进程工作区
printf("Parent PID: %d\n",i);
}
else if (pid == 0) // 子进程工作区
{
if (i == 0)
{
printf("Child PID: %d 游泳\n", i);
while(1);
}else if(i==1){
printf("Child PID: %d 跑步\n", i);
while(1);
}
printf("Child PID: %d\n", i);
exit(0); // 子进程执行完工作区代码后必须结束进程
}
else
{
perror("fork call failed");
exit(0);
}
return 0;
}通过循环创建多个子进程。每次调用 fork() 后,会得到不同的PID
- 在父进程中,
fork()返回新创建子进程的PID。- 在子进程中,
fork()返回0。
根据PID来区分是自己还是子进程,并输出相应的信息。
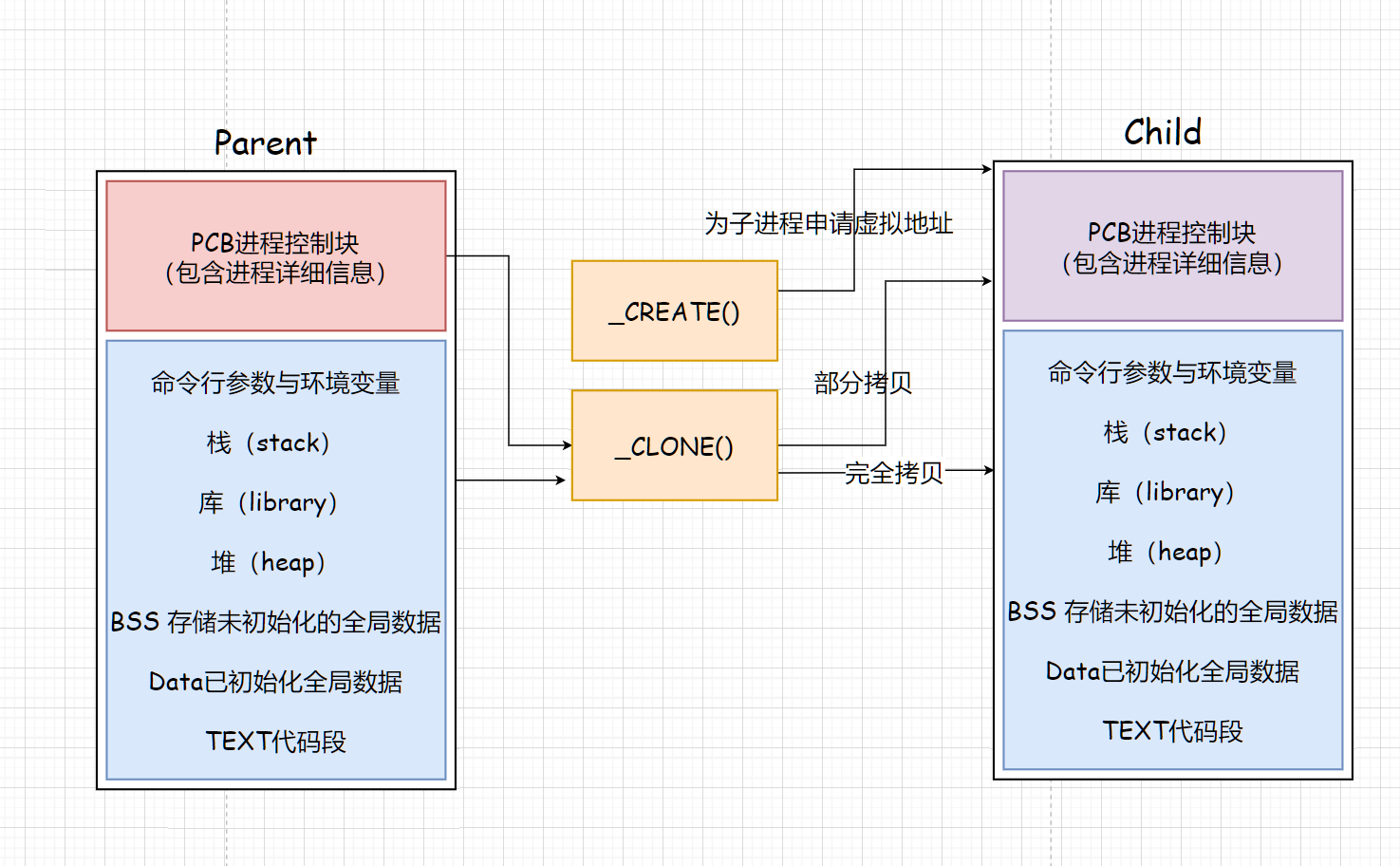
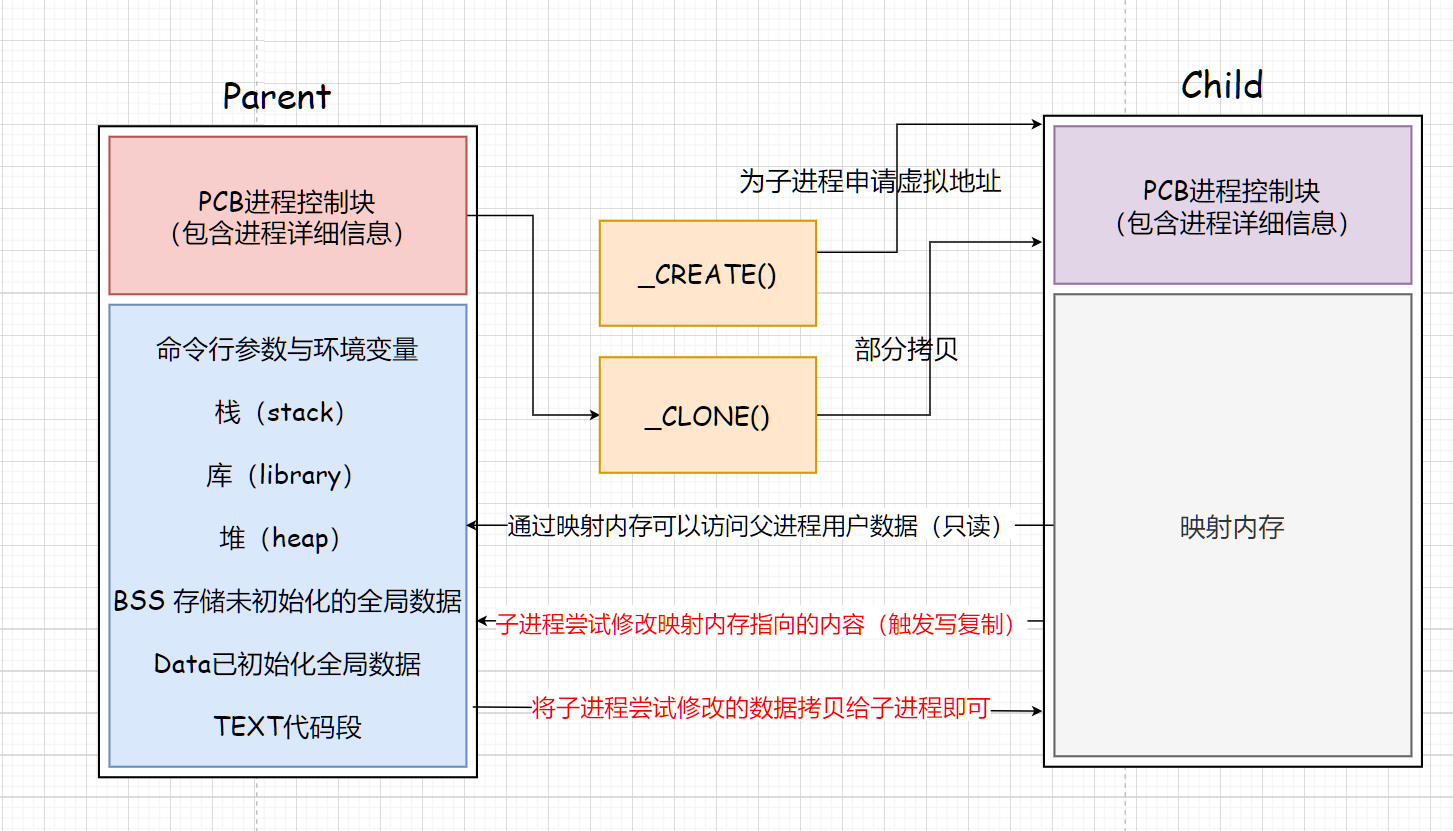
父子进程的继承与拷贝
_CREATE为子进程申请虚拟地址。
_CLONE对父进程的PCB进程控制块进行部分拷贝到子进程的PCB。但是用户空间并不是简单的拷贝。
随着fork函数的迭代,对用户空间的拷贝操作也发生了变化。
第一版FORK
父进程创建子进程后,将所有的用户层资源拷贝给子进程
缺点:如果子进程不需要拷贝继承用户层数据,父进程进行了拷贝,这些拷贝开销对子进程没有任何意义,无意义系统开销
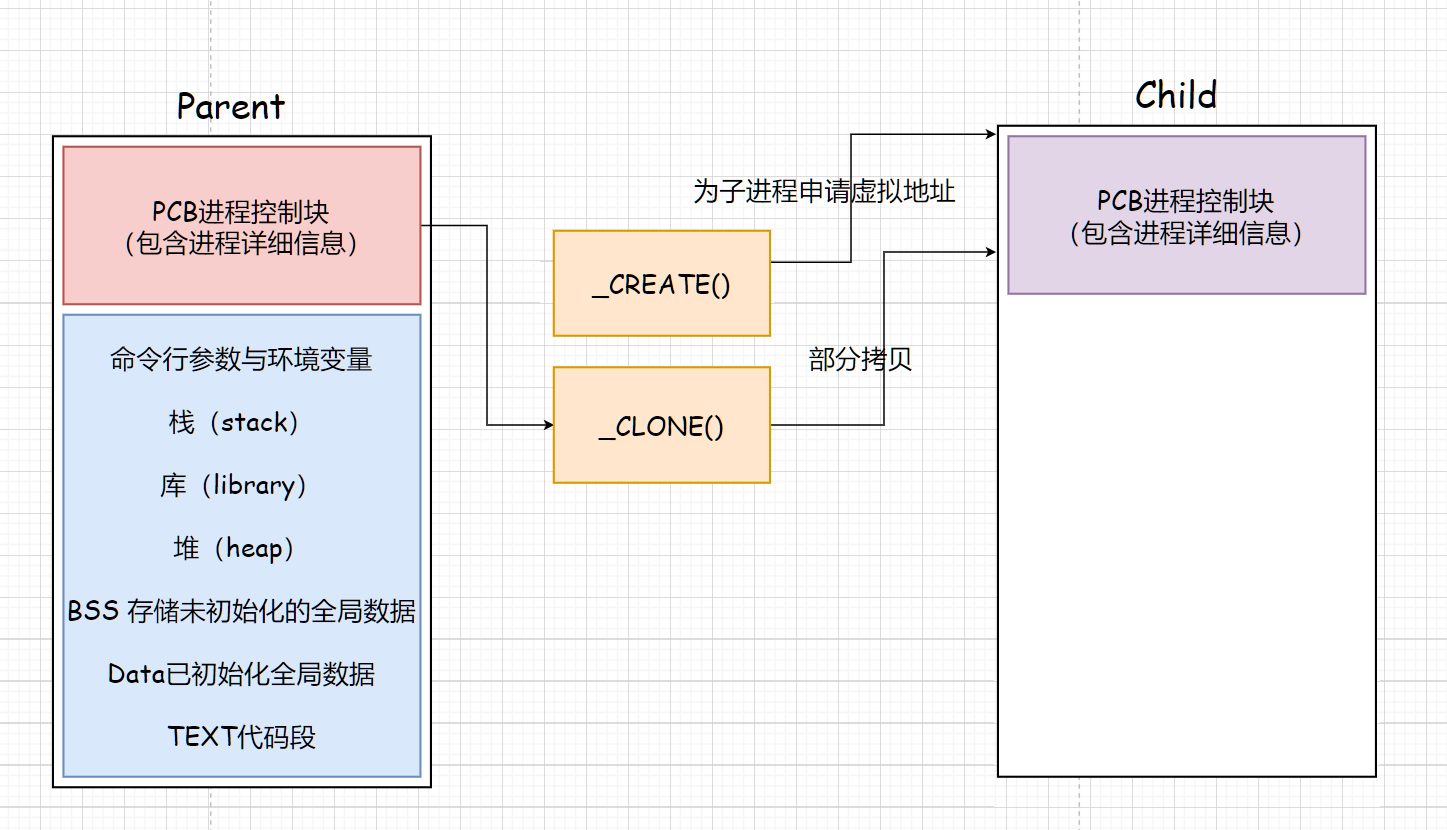
第二版vfork
vfork 是 fork 的一个变体。vfork 的设计目标是提高性能,vfork需要与exec结合使用。通过共享地址空间来避免 第一代fork 的开销。
通过vfork创建的子进程是没有0-3G用户层数据的,需要使用者自行准备加载进程0-3G之和才可以使用。
第三版fork
第三版fork(现在所使用的fork)会为子进程的0-3G内存会申请一块映射内存,映射父进程的用户层数据,来进行读取访问父进程的用户空间(读时共享)。在需要修改数据时,会将父进程的数据复制到子进程,对复制的数据进行修改(写时复制)。
读时共享,写时复制
写复制机制对父子进程都有效,父进程修改映射数据也要进行复制操作。
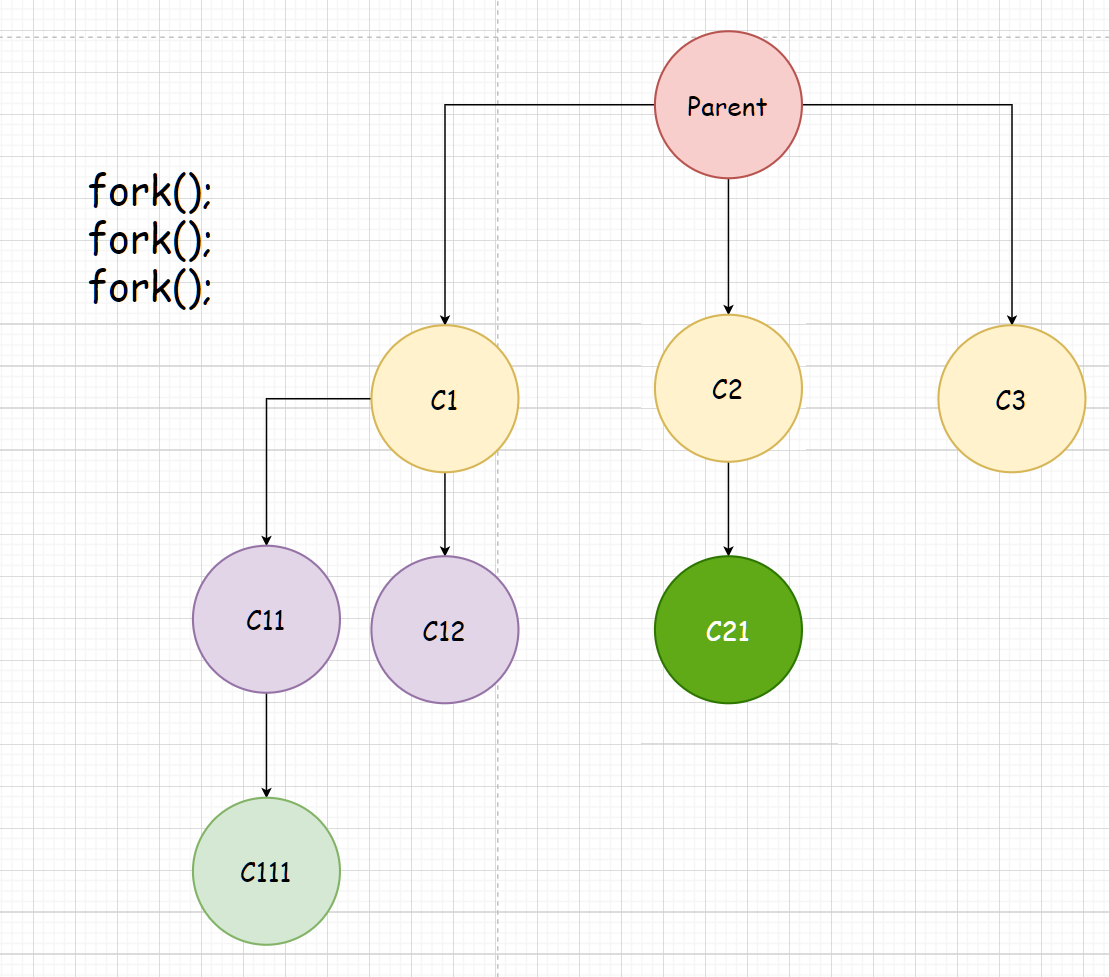
关于多次执行fork,进程创建数量
有一个父进程,连续调用n次fork函数,那么这个过程一共创建了多少子进程?
答:2n-1个。创建出来的子进程执行当前fork后的函数体代码。
如果是下面这种情况呢?
fork();
fork()&&fork()||fork();
fork();fork的返回值是有0的,所以这种情况下需要考虑返回值。
初始状态:
P0 表示初始的父进程。
第一步:fork();
P0 调用 fork() 创建一个新的子进程 P1。
现在有两个进程:P0 和 P1。
第二步:fork() && fork() || fork();
P0 和 P1 分别执行这行代码。
1、第一个 fork():
P0和P1各自调用fork(),每个进程创建一个新子进程。新进程分别是
P2和P3。现在有 4 个进程:
P0,P1,P2,P3。
2、第二个 fork()(在 && 之后):
只有在前一个
fork()返回非零值时才会执行(即在父进程中执行)。这意味着
P0和P1将各自再执行一次fork()。新进程分别是
P4和P5。现在有 6 个进程:
P0,P1,P2,P3,P4,P5。
3、第三个 fork()(在 || 之后):
只有当
fork() && fork()结果为假时才会执行(即在没有新进程的情况下执行)。现有的 4 个进程
P2,P3,P4,P5将执行fork()。新进程分别是
P6,P7,P8,P9。现在有 10 个进程:
P0,P1,P2,P3,P4,P5,P6,P7,P8,P9。
第三步:fork();
每个现有的进程(
P0,P1,P2,P3,P4,P5,P6,P7,P8,P9)再调用一次fork()。每个进程再创建一个新的子进程。
新进程分别是
P10到P19。现在总共有 20 个进程。
经过这三行代码,总共创建了 19 个新的子进程(加上原来的 1 个父进程,总共是 20 个进程)。

















 3931
3931




 到【灌水乐园】发言
到【灌水乐园】发言







