




 本文介绍了一种基于图像处理和深度学习的文字检测与识别方法,包括灰度化、局部二值化、连通域检测、字符串区域确定、文字角度检测、ROI处理及Tesseract OCR应用。
本文介绍了一种基于图像处理和深度学习的文字检测与识别方法,包括灰度化、局部二值化、连通域检测、字符串区域确定、文字角度检测、ROI处理及Tesseract OCR应用。
第一次写长博,记录一个项目。这几天一直在接小活,有一个是客户的要求是将目标图片上的文字(目测是好多器材上边的编号)检测出来,并对比,要求长字符串和长字符串相同,短字符串和短字符串相同,不一样的需要标识出来。感觉还挺有意思的,就把过程贴出来以便日后复习。话不多说先贴图:待检测图片和最终识别结果如下图,相同的长字符串用蓝色框标出,短字符串用绿色框标出,而疑似不一致字符串用红色框标出,对客户传来的待测试图片集检测效果良好。


基本上随着现在OCR技术的不断拓展和文字处理技术的不断上升,这个问题应该已经不算是问题,在这里梳理一下大致思路,其中为了锻炼自己对图像处理的理解,除了二值化的的函数和拟合最小包络矩形之外,都没用什么API。
0.具体思路的确定
根据具体问题的特殊性和与车牌检测的相区别(车牌检测的重要一步是车牌有矩形外边框因而容易确定文字所在范围,这类问题没有很明显的文字定位标志),通过不断试错确定了以下思路:
- 灰度+自适应性局部二值化
- 图像膨胀+简单滤波
- 八连通域检测
- 连通域筛选滤波
- 搜索确定字符串区域(由若干连通域组成)
- 基于形心的字符串角度最小二乘检测(兼排除噪声)
- 确定字符穿ROI
- ROI图像处理
- 基于Tesseract4.0的深度学习OCR文字识别
- 处理识别出的字符串,判断非一致项,并将结果在原图中标出。
下面对仅重要步骤作详细说明:
1.关于二值化的说明
客户提供的图片文字和背景对比度很高,一开始以为二值化是个小事,但后来发现并非如此。在一开始二值化过程中分别采取了以下几种方案:定值的全局二值化、分块OTSU局部二值化以及最终采用的自适应局部二值化(adaptiveThreshold)。定值的全局二值化的问题在于图像的适应性很差,对于一张图像而言可能存在一个最佳阈值可能是确定的,但是多张图片受光线影响较重;为了解决光线的问题,采取了分块OTSU局部二值化的方法,这个函数是自己写的,可以选择块的大小,并对每个块进行OTSU二值化,但是这个方法的问题在于,OTSU是为区分图片的前景和背景而存在,但在本问题中,文字部分可不仅仅是”前景“那么简单,换句话说,通过OTSU后,不仅文字部分——好多灰度高于大约40的部分都被划分为前景,这对后边滤波和连通域的分析都带来极大的困难,一方面是引入很多噪声,另一方面各个字符之间的区域也被识别为白色,无法分开,但是这一步也不是白做的,引入的思考:一个比较好的想法就是,既然OTSU得出来的阈值不够”高“,那么如果我们在OTSU所得到的基础上,加上一个”合适的数“,使最终的结果作为二值化的阈值,那问题不就解决了?这个其实想法也可以在自己的函数上实践,但是最后直接用了adaptiveThreshold,这个函数最终的两个参数分别是分块的”块的大小“以及”最终加上的那个值“,用了这个函数以后可以很好的区分文字部分和非文字部分,避免引入尽量少的噪声;关于”块的选取“,本例中前景和背景区分明确,应该使块”尽量大“以忽略诸多细节(这些细节就体现在文字与文字之间相连的部分),而”加上的值“要尽量大,即二值化的”要求要尽量高“。最终二值化的结果展现如下 :可以发现除了少部分星星点点的噪声以外效果还是很好的。

2. 图像膨胀+中值滤波
这一步没什么可说的,只有关于图像膨胀的必要性说明:有一些独立字符在二值化之后分开了,如大写的K的一竖和右边的部分就分开了,分成了两个连通域,这是不好的,因为后边还会对字符串内连通域的个数进行统计,因此用dilate对白色区域进行膨胀。
3. 八连通域检测
网上关于连通域的检测教程有很多,也有很多源码,这里就不赘述了,详情请看https://blog.youkuaiyun.com/ShanX_s/article/details/52860896,讲的很生动,也有代码。
但是源码大多是四联通域的,我自己写了个八连通域的(两遍法),贴出来分享给大家。关于四联通域和八连通域的区别在于,四联通域两边比较的对象都是上像素和左像素,但八连通域比较对象扩充到了:上像素、左像素、上左像素、和上右像素,同时处理的时候仍然要像素越界的问题。另一个比较坑的地方就是,labelImg一定要是long int格式,因为我的图像实在是太大了(4000*13000),只有一个int根本储存不过来,不然会出现用完了又来一遍,这就比较坑了,因为他不会报错,但一个连通域又被分成了两个!!!让我检查了好久到底是哪里出了问题。
bool FindConnectedDomain(Mat& srcImg, Mat& labelImg)
{
if (srcImg.empty())
{
cerr << "Invalid input parameters! " << endl;
return false;
}
if (srcImg.channels() != 1)
{
cerr << "Please input a binary image!" << endl;
return false;
}
labelImg = Mat(srcImg.size(), CV_32SC1, Scalar(0));
vector<long int> labelSet;
labelSet.push_back(0);
int flag = 0;
//第一遍扫描
for (int row = 0; row < srcImg.rows; row++)
{
uchar* currentPtr = srcImg.ptr<uchar>(row);
uchar* lastPtr = srcImg.ptr<uchar>(max(0, row - 1));
long int* currentDstPtr = labelImg.ptr<long int>(row);
long int* lastDstPtr = labelImg.ptr<long int>(max(0, row - 1));
for (int col = 0; col < srcImg.cols; col++)
{
if (currentPtr[col] == 255)
{
//四联通域
//if (currentDstPtr[max(0,col-1)] == 0 && lastDstPtr[col] == 0)
//{
//flag++;
//currentDstPtr[col] = flag;
//labelSet.push_back(flag);
//}
//else if (currentDstPtr[max(0, col-1)] == 0 && lastDstPtr[col] != 0)
//{
// currentDstPtr[col] = lastDstPtr[col];
//}
//else if (currentDstPtr[max(0, col-1)] != 0 && lastDstPtr[col] == 0)
//{
// currentDstPtr[col] = currentDstPtr[max(0, col-1)];
//}
//else if (currentDstPtr[max(0, col-1)] != 0 && lastDstPtr[col] != 0)
//{
// int upperLabel = labelSet[lastDstPtr[col]];
// int leftLabel = labelSet[currentDstPtr[max(0, col-1)]];
// int biggerLabel = max(upperLabel, leftLabel);
// int smallerLabel = min(upperLabel, leftLabel);
// currentDstPtr[col] = smallerLabel;
// labelSet[biggerLabel] = smallerLabel;
//}
//八连通域
if (currentDstPtr[max(0, col - 1)] == 0 && lastDstPtr[col] == 0 && lastDstPtr[max(0, col - 1)] == 0 && lastDstPtr[min(col + 1, srcImg.cols - 1)] == 0)
{
flag++;
currentDstPtr[col] = flag;
labelSet.push_back(flag);
}
else
{
int leftLabel = labelSet[currentDstPtr[max(0, col - 1)]];
int upLabel = labelSet[lastDstPtr[col]];
int upLeftLabel = labelSet[lastDstPtr[max(0, col - 1)]];
int upRightLabel = labelSet[lastDstPtr[min(col + 1, srcImg.cols - 1)]];
int tempLabel = max(max(max(leftLabel, upLabel), upLeftLabel), upRightLabel);
int smallestLabel = min(tempLabel, leftLabel);
if (smallestLabel == 0) smallestLabel = tempLabel;
if (smallestLabel != 0) tempLabel = smallestLabel;
smallestLabel = min(tempLabel, upLabel);
if (smallestLabel == 0) smallestLabel = tempLabel;
if (smallestLabel != 0) tempLabel = smallestLabel;
smallestLabel = min(tempLabel, upLeftLabel);
if (smallestLabel == 0) smallestLabel = tempLabel;
if (smallestLabel != 0) tempLabel = smallestLabel;
smallestLabel = min(tempLabel, upRightLabel);
if (smallestLabel == 0) smallestLabel = tempLabel;
if (smallestLabel != 0) tempLabel = smallestLabel;
currentDstPtr[col] = smallestLabel;
if (leftLabel != 0)
{
labelSet[leftLabel] = smallestLabel;
}
if (upLabel != 0)
{
labelSet[upLabel] = smallestLabel;
}
if (upLeftLabel != 0)
{
labelSet[upLeftLabel] = smallestLabel;
}
if (upRightLabel != 0)
{
labelSet[upRightLabel] = smallestLabel;
}
}
}
}
}
//第二遍扫描
for (int row = 0; row < labelImg.rows; row++)
{
int* currentRow = labelImg.ptr<int>(row);
for (int col = 0; col < labelImg.cols; col++)
{
if (currentRow[col] == 0) continue;
int oldLabel = currentRow[col];
while (currentRow[col] != labelSet[oldLabel])
{
currentRow[col] = labelSet[oldLabel];
oldLabel = currentRow[col];
}
}
}
return true;
}
4. 连通域筛选滤波
自己创建的连通域结构体如下ConnectedDomain,包含了所有像素位置,像素的边界坐标(用来以后确定最小正矩形),连通域大小以及连通域的形心(用来以后最小二乘文字角度用)。
struct ConnectedDomain
{
int label;
vector<PixelPoint> pixelGroup;
int xMax;
int xMin;
int yMax;
int yMin;
long int xSum;
long int ySum;
Point2d center;
int area;
};
而对于从labelImg转换到vector<ConnectedDomain>的过程需要经历面积大小的筛选,最小包络正矩形长宽大小以及长宽比的筛选,以及最小包络矩形的面积筛选。这里说明一下:最小包络正矩形指的是横平竖直的矩形,也就是结果图上画出来的那种,直接由连通域的xMax,xMin,yMax,yMin组合即可确定矩形顶点;最小包络矩形是用的API:cv::minAreaRect,值得一提的是,在大多数教材中minAreaRect是连在findContours后边用的,用于对轮廓检测最小矩形,但是实际上他的输入参数是InputArray,vector是他的基类之一,我们用vector<Point>类型的对象都可以作为形参传进去(InputArray真是强大,各种数据通吃)。代码段和八连通域最终滤波后的图像如下(花花绿绿的还挺好看):
for (vector<ConnectedDomain>::iterator it = connectedDomainGroup.begin(); it != connectedDomainGroup.end(); )
{
if (it->area < 200 || it->area > 2000 || (it->xMax - it->xMin) > 50 || (it->yMax - it->yMin) > 50)
{
it = connectedDomainGroup.erase(it);
continue;
}
vector<Point> pointGroup;
for (unsigned int i = 0; i < it->pixelGroup.size(); i++)
{
pointGroup.push_back(Point(it->pixelGroup[i].col, it->pixelGroup[i].row));
}
RotatedRect rect = minAreaRect(pointGroup);
Size mySize(rect.size);
if (mySize.width < 5 || mySize.height < 5)
{
it = connectedDomainGroup.erase(it);
continue;
}
it->center.x = (double)(it->xSum) / (double)(it->pixelGroup.size());
it->center.y = (double)(it->ySum) / (double)(it->pixelGroup.size());
it++;
}

5.确定字符区域
连通域都弄好了,接下来就要确定字符区域,我创建的字符结构体如下,成员包括连通域向量,包络正矩形和文字的倾斜角度(以后仿射变换用的):
struct CharacterGroup
{
int xMax;
int xMin;
int yMax;
int yMin;
double angle;
PixelPoint xMax_yMax;
PixelPoint xMax_yMin;
PixelPoint xMin_yMax;
PixelPoint xMin_yMin;
vector<ConnectedDomain> relatedConnectedDomain;
};
确定字符串的条件是:连通域之间相距小于设定阈值的彼此属于同一字符,这就带来一个坏处就是,假设在一堆文字联通域中出现了一个滤波没滤掉的坏连通域,那么他一并会被列入相关字符串并参与后续运算,针对此我们在第六步进行了最小二乘噪声剔除。
6.确定文字角度
确定文字角度的方法是对所有属于一个字符串的连通域进行最小二乘拟合直线,通过对拟合直线的斜率进行atan就能得到文字角度,这些都是为了后续仿射变换做准备(放射变换是为了将文字调正,为了OCR做准备)至于最小二乘是如何去除噪声的呢,这个就仁者见仁了,我也卖个关子,不在这里说。最后也可以引入一点回环检测的思想,因为基本上所有文字都是平行的,可以对所有字符串的角度进行统计,一般都是74°小数点后一两位不确定,对于相差太多的字符串肯定是有噪声影响,那么我们就可以处理一下巴拉巴拉。贴上最小二乘的代码,浅显易懂不必说明。
void LineFitLeastSquares(vector<float>& data_x, vector<float>& data_y, int data_n, vector<float> &gradient, vector<float> &intercept, vector<float> &r2)
{
float A = 0.0;
float B = 0.0;
float C = 0.0;
float D = 0.0;
float E = 0.0;
float F = 0.0;
for (int i = 0; i<data_n; i++)
{
A += data_x[i] * data_x[i];
B += data_x[i];
C += data_x[i] * data_y[i];
D += data_y[i];
}
// 计算斜率a和截距b
float a, b, temp = 0;
if (temp = (data_n*A - B*B))// 判断分母不为0
{
a = (data_n*C - B*D) / temp;
b = (A*D - B*C) / temp;
}
else
{
a = 1;
b = 0;
}
// 计算相关系数r
float Xmean, Ymean;
Xmean = B / data_n;
Ymean = D / data_n;
float tempSumXX = 0.0, tempSumYY = 0.0;
for (int i = 0; i<data_n; i++)
{
tempSumXX += (data_x[i] - Xmean) * (data_x[i] - Xmean);
tempSumYY += (data_y[i] - Ymean) * (data_y[i] - Ymean);
E += (data_x[i] - Xmean) * (data_y[i] - Ymean);
}
F = sqrt(tempSumXX) * sqrt(tempSumYY);
float r;
r = E / F;
gradient.push_back(a);
intercept.push_back(b);
r2.push_back(r*r);
}
7&8.确定字符串ROI并做相关图像处理
上边都确定了字符串最小包络正矩形了,当然可以对原图选取ROI,在ROI选取后对ROI做的处理有adaptiveThreshold啦、滤波啦、放射变换啦等等,最后处理出来的是这个样子的,交给Tesseract就会省心的多啦!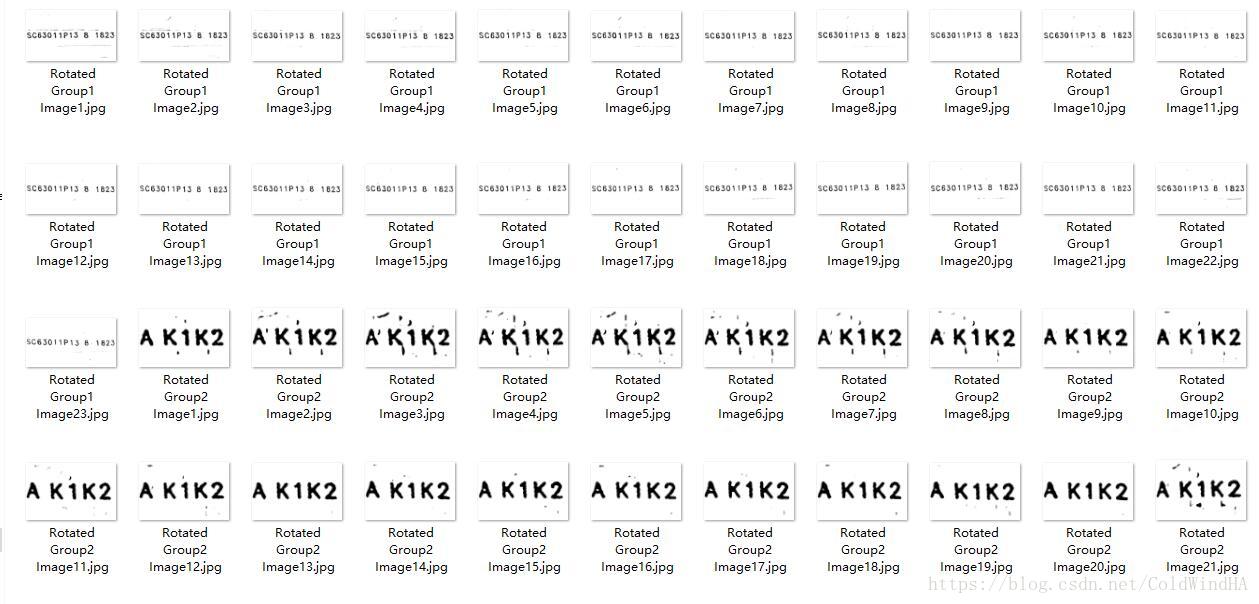

9.基于Tesseract的OCR
我的IDE是VS2015,编译环境release+32,配置Tesseract详见这位网友大大的救命博文https://blog.youkuaiyun.com/andylanzhiyong/article/details/81807425,真是服了,这个配置花了我两天时间,需要用cmake对tesseract和cppan生成项目再编译,以前只用过cmake逆向OpenCV源码和配置Eigen以及SSBA,结果这次中间遇到各种bug各种找不到文件。另注:使用的数据集是Google官方提供的eng.traineddata。
10.对检测出的字符串进行处理
这一步主要是针对人为可见的误识别,如”S“识别成了”$”等,几个if就解决了。最终识别效果还是挺好的,小项目也没有必要去自己训练一份数据。识别结果如下:


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









