



例如:要实现 Ollama 接口调用后,文字逐步输出(即流式数据),推荐使用 Fetch API 并设置 stream: true,而不是使用 EventSource。以下是详细解释和实现方法:
为什么选择 Fetch API 而不是 EventSource?
1. Fetch API 的优势
-
灵活性:Fetch API 支持自定义请求头和请求体,适合需要传递复杂参数(如 model 和 prompt)的场景。
-
流式读取:通过 response.body.getReader(),可以逐步读取响应数据,实现逐字输出。
-
广泛支持:Fetch API 是现代浏览器的标准 API,兼容性良好
2. EventSource 的局限性
-
仅支持 GET 请求:EventSource 是基于 HTTP GET 请求的,无法直接传递复杂的请求体(如 JSON 数据)。
-
单向通信:EventSource 只能接收服务器发送的数据,无法像 Fetch API 那样灵活地控制请求和响应。
-
适用场景有限:EventSource 更适合服务器主动推送数据的场景(如实时通知),而不是逐步返回生成内容。
使用 Fetch API 实现流式数据输出
以下是完整的实现步骤和代码示例:
1. 设置 stream: true
在请求体中设置 stream: true,告诉 Ollama 以流式方式返回数据。
2. 逐步读取响应
使用 response.body.getReader() 逐步读取响应数据,并通过 TextDecoder 解码。
3. 实时更新页面
将每次读取的数据实时更新到页面上,实现逐字输出效果。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Ollama Stream Response</title>
</head>
<body>
<h1>Ollama Stream Response</h1>
<button id="ask-btn">Ask Ollama</button>
<pre id="response"></pre>
<script>
document.getElementById('ask-btn').addEventListener('click', async () => {
// 发起 Fetch 请求
const response = await fetch('http://localhost:11434/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'llama2', // 模型名称
prompt: 'Tell me a story about a dragon.', // 输入提示
stream: true, // 启用流式响应
}),
});
// 获取可读流
const reader = response.body.getReader();
const decoder = new TextDecoder();
const responseElement = document.getElementById('response');
// 逐步读取数据
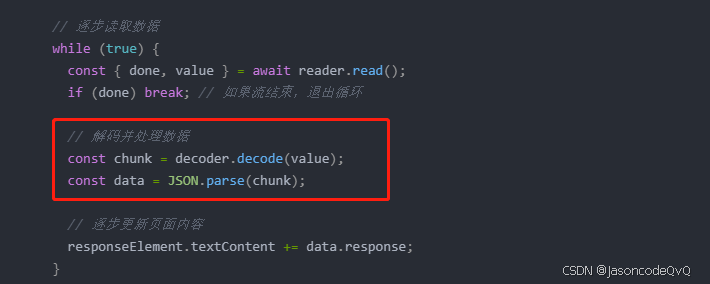
while (true) {
const { done, value } = await reader.read();
if (done) break; // 如果流结束,退出循环
// 解码并处理数据
const chunk = decoder.decode(value);
const data = JSON.parse(chunk);
// 逐步更新页面内容
responseElement.textContent += data.response;
}
});
</script>
</body>
</html>
代码说明
-
Fetch 请求:
- 设置 stream: true,启用流式响应。
- 传递 model 和 prompt 参数。
-
流式读取:
- 使用 response.body.getReader() 获取可读流。
- 通过 TextDecoder 解码二进制数据为字符串。
-
逐步更新:
- 每次读取的数据是一个 JSON 对象,包含 response 字段。
- 将 response 字段的内容逐步追加到页面中。
关键点
- 流式响应:
- 确保在请求体中设置 stream: true。
- 使用 response.body.getReader() 逐步读取数据。
- 数据格式:
- 每个数据块是一个 JSON 对象,包含 response 字段(生成的内容)。
- 性能优化:
- 对于长文本生成,流式响应可以显著提升用户体验,避免长时间等待。
- 错误处理:
- 在实际项目中,建议添加错误处理逻辑(如网络错误、JSON 解析错误等)。
总结
-
推荐使用 Fetch API:通过设置 stream: true 并逐步读取响应数据,可以实现流式输出。
-
EventSource 不适用:因为 EventSource 仅支持 GET 请求,无法传递复杂参数。
-
逐步更新页面:通过实时更新页面内容,可以实现逐字输出的效果。
BUG示例:
下面是使用 Deepseek API 获取流式数据后,直接使用 JSON.parse(decoder.decode(value)) 出现的报错

-
Deepseek API 请求
// 发起 Fetch 请求 const response = await fetch('https://api.deepseek.com/chat/completions', { method: 'POST', headers: { 'Content-Type': 'application/json', 'Authorization': 'Bearer sk-ba32***************' }, body: JSON.stringify({ model: "deepseek-chat", messages: [{ role: "system", content: messageText }], stream: true, }) }); -
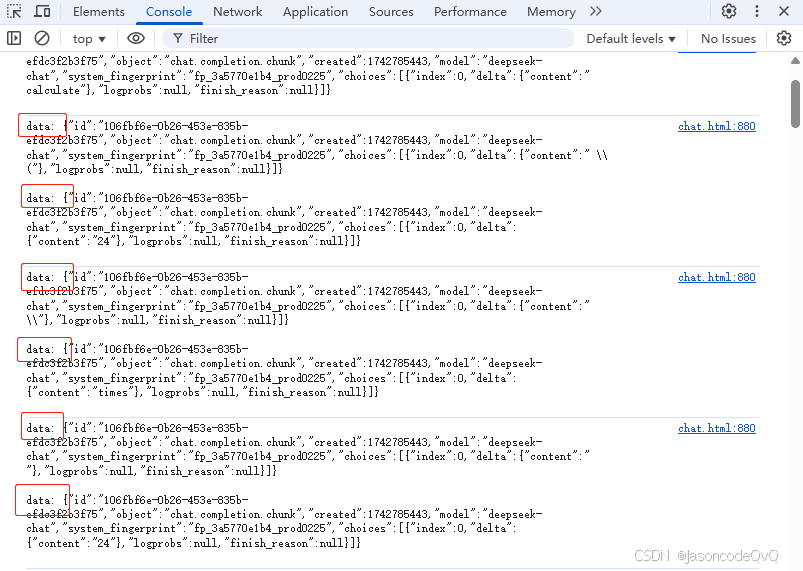
问题出在返回的
chunk无法直接使用JSON.parse解析
-
chunk返回数据,无法直接解析,出现报错
-
解决示例
// 获取可读流 const reader = response.body.getReader(); const decoder = new TextDecoder('utf-8'); let buffer = ''; let ohtmlStr = ''; while (true) { const { done, value } = await reader.read(); if (done) break; // 解码当前块(流式模式) buffer += decoder.decode(value, { stream: true }); // 按行拆分缓冲区 const lines = buffer.split('\n'); buffer = lines.pop(); // 最后一行可能不完整,保留在缓冲区中 // 处理每一行 for (const line of lines) { if (line.startsWith('data: ')) { const jsonString = line.slice(6); // 去掉 'data: ' 前缀 if (jsonString.trim() === '[DONE]') { console.log('Stream finished'); break; } try { const data = JSON.parse(jsonString); // 提取内容并更新 UI if (data.choices && data.choices[0].delta.content) { ohtmlStr += data.choices[0].delta.content; } } catch (error) { console.error('JSON parsing error:', error); } } } } // 解码缓冲区中剩余的数据(如果有) if (buffer) { const finalData = decoder.decode(); // 注意:这里不需要 { stream: true } console.log('Final data:', finalData); } -
测试示例
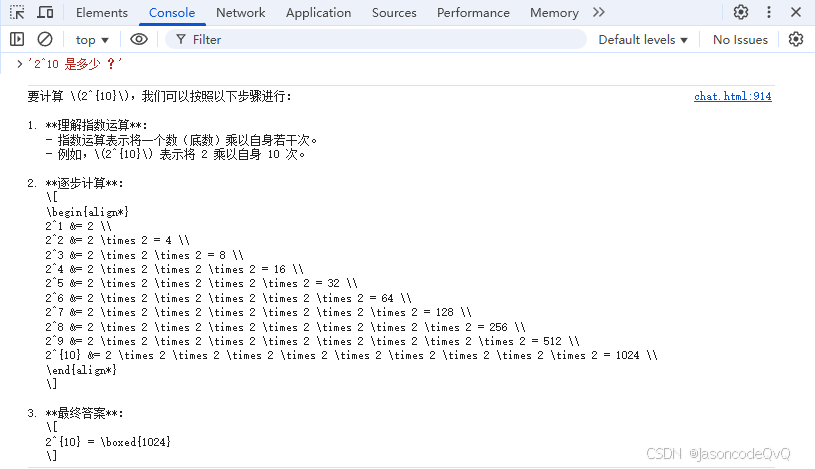
剩下的即是使用Markdown等工具,处理后在页面显示



















 6272
6272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









