



 本文深入探讨Python中的字符、元组、列表、字典和集合等数据结构,讲解每种结构的特点、内置方法及应用场景,对比列表与元组的性能差异,解析字典和集合的高效查找原理。
本文深入探讨Python中的字符、元组、列表、字典和集合等数据结构,讲解每种结构的特点、内置方法及应用场景,对比列表与元组的性能差异,解析字典和集合的高效查找原理。
Python 学习笔记补充1:字符(str)、元组(tuple)、列表(list)、字典(dict)、集合(set)
字符(str)
字符用于处理文本 (text) 数据,用「单引号 ’」和「双引号 “」来定义都可以。
字符中常见的内置方法 (可以用 dir(str) 来查) 有:
capitalize():大写句首的字母
split():把句子分成单词
find(x):找到给定词 x 在句中的索引,找不到返回 -1
replace(x, y):把句中 x 替代成 y
strip(x):删除句首或句末含 x 的部分
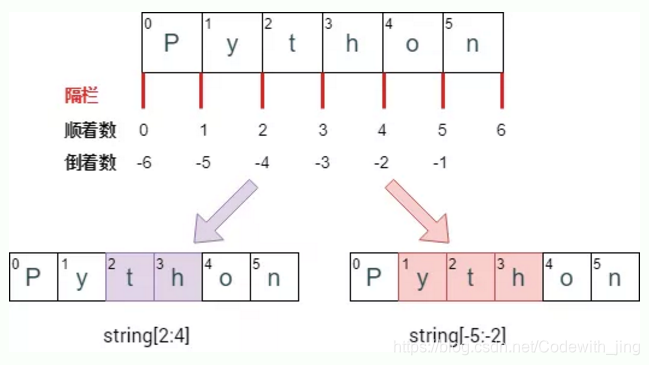
索引和切片:
- 从 0 开始 (和 C 一样),不像 Matlab 从 1 开始。
- 切片通常写成 start:end 这种形式,包括「start 索引」对应的元素,不包括「end索引」对应的元素。因此 s[2:4] 只获取字符串第 3 个到第 4 个元素。
- 索引值可正可负,正索引从 0 开始,从左往右;负索引从 -1开始,从右往左。使用负数索引时,会从最后一个元素开始计数。最后一个元素的位置编号是 -1。
元组(tuple)
创建元组可以用小括号 (),也可以什么都不用,为了可读性,建议还是用 ()。此外对于含单个元素的元组,务必记住要多加一个逗号,举例如下:
t1 = (1, 10.31, ‘python’)
t2 = 1, 10.31, ‘python’
print( t1, type(t1) )
print( t2, type(t2) )
#(1, 10.31, ‘python’) <class ‘tuple’>
#(1, 10.31, ‘python’) <class ‘tuple’>
print( type( (‘OK’) ) ) # 没有逗号 ,
print( type( (‘OK’,) ) ) # 有逗号 ,
元组中可以用整数来对它进行索引 (indexing) 和切片 (slicing),不严谨的讲,前者是获取单个元素,后者是获取一组元素。
元组有不可更改 (immutable) 的性质,因此不能直接给元组的元素赋值
内置方法
元组大小和内容都不可更改,因此只有 count 和 index 两种方法。
t = (1, 10.31, 'python')
print( t.count('python') )
print( t.index(10.31) )
#1
#1
- count(‘python’) 是记录在元组 t 中该元素出现几次,显然是 1 次
- index(10.31) 是找到该元素在元组 t 的索引,显然是 1
| 方法 | 解释 |
|---|---|
| cmp(tuple1, tuple2) | 比较两个元组元素。 |
| len(tuple) | 计算元组元素个数。 |
| max(tuple) | 返回元组中元素最大值。 |
| min(tuple) | 返回元组中元素最小值。 |
| tuple(seq) | 将列表转换为元组。 |
元组拼接
元组拼接 (concatenate) 有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
(1, 10.31, 'python') + ('data', 11) + ('OK',)
(1, 10.31, 'python') * 2
#(1, 10.31, 'python', 'data', 11, 'OK')
#(1, 10.31, 'python', 1, 10.31, 'python')
解压元组
解压 (unpack) 一维元组 (有几个元素左边括号定义几个变量)
t = (1, 10.31, 'python')
(a, b, c) = t
print( a, b, c )
#1 10.31 python
解压二维元组 (按照元组里的元组结构来定义变量)
t = (1, 10.31, ('OK','python'))
(a, b, (c,d)) = t
print( a, b, c, d )
#1 10.31 OK python
如果你只想要元组其中几个元素,用通配符*,英文叫 wildcard,在计算机语言中代表一个或多个元素。下例就是把多个元素丢给了 rest 变量。如果你根本不在乎 rest 变量,那么就用通配符*加上下划线_
t = 1, 2, 3, 4, 5
a, b, *rest, c = t
print( a, b, c )
print( rest )
#1 2 5
#[3, 4]
a, b, *_ = t
print( a, b )
#1 2
优点缺点
- 优点:占内存小,安全,创建遍历速度比列表快,可一赋多值。
- 缺点:不能添加和更改元素。
列表(list) vs 元组(tuple)
1、创建
%timeit [1, 2, 3, 4, 5]
%timeit (1, 2, 3, 4, 5)
62 ns ± 13.2 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
12.9 ns ± 1.94 ns per loop (mean ± std. dev. of 7 runs, 100000000 loops each)
创建速度,元组 (12.9ns) 碾压列表 (62ns)。
2、遍历
lst = [i for i in range(65535)]
tup = tuple(i for i in range(65535))
%timeit for each in lst: pass
%timeit for each in tup: pass
507 µs ± 61.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
498 µs ± 18.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
遍历速度两者相当,元组 (498 µs) 险胜列表 (507 µs)。
3、占空间
from sys import getsizeof
print( getsizeof(lst) )
print( getsizeof(tup) )s
578936
524328
列表比元组稍微废点内存空间。
列表(list)
内置方法
不像元组,列表内容可更改 (mutable),因此附加 (append, extend)、插入 (insert)、删除 (remove, pop) 这些操作都可以用在它身上。
1、附加(append、extend)
- list.append(obj) 在列表末尾添加新的对象,只接受一个参数,参数可以是任何数据类型,被追加的元素在 list
中保持着原结构类型。 - list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
l.append([4, 3])
print( l )
l.extend([1.5, 2.0, 'OK'])
print( l )
[1, 10.31, 'python', [4, 3]]
[1, 10.31, 'python', [4, 3], 1.5, 2.0, 'OK']
严格来说 append 是追加,把一个东西整体添加在列表后,而 extend 是扩展,把一个东西里的所有元素添加在列表后。对着上面结果感受一下区别。
2、插入(insert)
insert(i, x) 在编号 i 位置前插入 x。
l.insert(1, 'abc') # insert object before the index position
l
[1, 'abc', 10.31, 'python', [4, 3], 1.5, 2.0, 'OK']
3、删除(remove, pop,del)
remove 和 pop 都可以删除元素
- 前者是指定具体要删除的元素,比如 ‘python’
- 后者是指定一个编号位置,比如 3,删除 l[3] 并返回出来
- list.remove(obj) 移除列表中某个值的第一个匹配项
- list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
l.remove('python') # remove first occurrence of object
l
[1, 'abc', 10.31, [4, 3], 1.5, 2.0, 'OK']
p = l.pop(3) # removes and returns object at index.only pop 1 index position at any time.
print( p )
print( l )
[4, 3]
[1, 'abc', 10.31, 1.5, 2.0, 'OK']
- del var1[, var2 ……] 删除单个或多个对象。如果知道要删除的元素在列表中的位置,可使用del语句。
x = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
del x[0:2]
print(x) # ['Wednesday', 'Thursday', 'Friday']
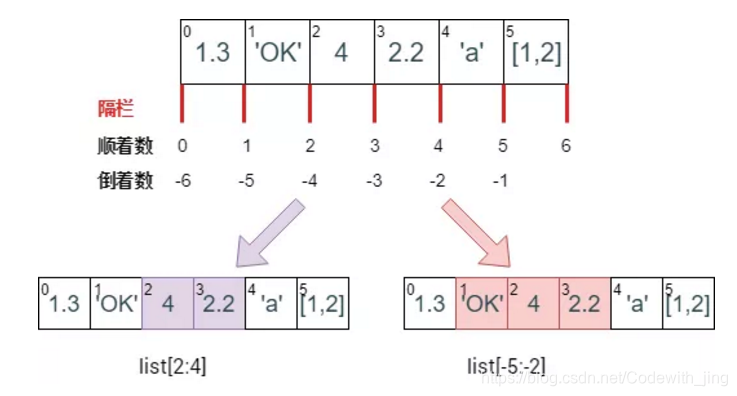
切片索引
切片的通用写法为: start : stop : step
x = [a] * 4操作中,只是创建4个指向list的引用,所以一旦a改变,x中4个a也会随之改变。
x = [[0] * 3] * 4
print(x, type(x))
# [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]] <class 'list'>
x[0][0] = 1
print(x, type(x))
# [[1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0]] <class 'list'>
a = [0] * 3
x = [a] * 4
print(x, type(x))
# [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]] <class 'list'>
x[0][0] = 1
print(x, type(x))
# [[1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0]] <class 'list'>
" : " : 复制列表中的所有元素(浅拷贝)。
列表拼接
和元组拼接一样, 列表拼接也有两种方式,用「加号 +」和「乘号 *」,前者首尾拼接,后者复制拼接。
[1, 10.31, 'python'] + ['data', 11] + ['OK']
[1, 10.31, 'python'] * 2
[1, 10.31, 'python', 'data', 11, 'OK']
[1, 10.31, 'python', 1, 10.31, 'python']
列表(list)的常用操作符
- 等号操作符:==
- 连接操作符 +
- 重复操作符 *
- 成员关系操作符 in、not in
「等号 ==」,只有成员、成员位置都相同时才返回True。
列表的其他方法
1、list.count(obj) 统计某个元素在列表中出现的次数
list1 = [123, 456] * 3
print(list1) # [123, 456, 123, 456, 123, 456]
num = list1.count(123)
print(num) # 3
2、list.index(x[, start[, end]]) 从列表中找出某个值第一个匹配项的索引位置
list1 = [123, 456] * 5
print(list1.index(123)) # 0
print(list1.index(123, 1)) # 2
print(list1.index(123, 3, 7)) # 4
3、list.reverse() 反向列表中元素
x = [123, 456, 789]
x.reverse()
print(x) # [789, 456, 123]
| 方法 | 解释 |
|---|---|
| list.append(): | 追加成员 |
| list.count(x): | 计算列表中参数x出现的次数 |
| list.extend(L): | 向列表中追加另一个列表L |
| list.index(x): | 获得参数x在列表中的位置 |
| list.insert(): | 向列表中插入数据 |
| list.pop(): | 删除列表中的成员(通过下标删除) |
| list.remove(): | 删除列表中的成员(直接删除) |
| list.reverse(): | 将列表中成员的顺序颠倒 |
| list.sort(): | 将列表中成员排序 |
优点缺点
- 优点:灵活好用,可索引、可切片、可更改、可附加、可插入、可删除。
- 缺点:相比 tuple 创建和遍历速度慢,占内存。此外查找和插入时间较慢。
字典(dict)
内置方法
字典里最常用的三个内置方法就是 keys(), values() 和 items(),分别是获取字典的键、值、对。
example 2:
temp = input("不妨猜一下小哥哥现在心里想的是那个数字:")
guess = int(temp)
if guess > 8:
print("大了,大了")
else:
if guess == 8:
print("你这么懂小哥哥的心思吗?")
print("哼,猜对也没有奖励!")
else:
print("小了,小了")
print("游戏结束,不玩儿啦!")
此外在字典上也有添加、获取、更新、删除等操作。
1、添加
d['Headquarter'] = 'Shen Zhen'
2、获取
print( d['Price'] )
print( d.get('Price') )
3、更新
4、删除
del d['Code']
或像列表里的 pop() 函数,删除行业 (industry) 并返回出来。
d = {'Name': 'Tencent',
'Country': 'China',
'Industry': 'Technology',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}
print( d.pop('Industry') )
Technology
{'Name': 'Tencent',
'Country': 'China',
'Price': '359 HKD',
'Headquarter': 'Shen Zhen'}
不可更改键
字典里的键是不可更改的,因此只有那些不可更改的数据类型才能当键,比如整数 (虽然怪怪的)、浮点数 (虽然怪怪的)、布尔 (虽然怪怪的)、字符、元组 (虽然怪怪的),而列表却不行,因为它可更改。
有个地方要注意下,True 其实和整数 1 是一样的,由于键不能重复,当字典中有两个键Ture 和1时,你会发现字典只会取其中一个键。
d = {
2 : 'integer key',
10.31 : 'float key',
True : 'boolean key',
('OK',3) : 'tuple key'
}
d = {
1 : 'integer key',
10.31 : 'float key',
True : 'boolean key',
('OK',3) : 'tuple key'
}
d
{1: 'boolean key',
10.31: 'float key',
('OK', 3): 'tuple key'}
判断一个数据类型 X 是不是可更改的:
- 麻烦方法:用 id(X) 函数,对 X 进行某种操作,比较操作前后的 id,如果不一样,则 X 不可更改,如果一样,则 X 可更改。
- 便捷方法:用 hash(X),只要不报错,证明 X 可被哈希,即不可更改,反过来不可被哈希,即可更改。
| 方法 | 解释 |
|---|---|
| adict.keys() | 返回一个包含字典所有KEY的列表; |
| adict.values() | 返回一个包含字典所有value的列表; |
| adict.items() | 返回一个包含所有(键,值)元祖的列表; |
| adict.clear() | 删除字典中的所有项或元素; |
| adict.copy() | 返回一个字典浅拷贝的副本; |
| adict.fromkeys(seq, val=None) | 创建并返回一个新字典,以seq中的元素做该字典的键,val做该字典中所有键对应的初始值(默认为None); |
| adict.get(key, default = None) | 返回字典中key对应的值,若key不存在字典中,则返回default的值(default默认为None); |
| adict.has_key(key) | 如果key在字典中,返回True,否则返回False。 现在用 in 、 not in; |
| adict.iteritems() adict.iterkeys() adict.itervalues() | 与它们对应的非迭代方法一样,不同的是它们返回一个迭代子,而不是一个列表; |
| adict.pop(key[,default]) | 和get方法相似。如果字典中存在key,删除并返回key对应的vuale;如果key不存在,且没有给出default的值,则引发keyerror异常; |
| adict.setdefault(key, default=None) | 和set()方法相似,但如果字典中不存在Key键,由 adict[key] = default 为它赋值; |
| adict.update(bdict) | 将字典bdict的键值对添加到字典adict中。 |
优点缺点
- 优点:查找和插入速度快
- 缺点:占内存大
集合(set)
「集合」有两种定义语法,第一种是:{元素1, 元素2, …, 元素n};第二种是:第二种是用 set() 函数,把列表或元组转换成集合。set( 列表 或 元组 )
集合的两个特点:无序 (unordered) 和 唯一 (unique)。由于 set 存储的是无序集合,所以我们没法通过索引来访问,但是可以判断一个元素是否在集合中。
内置方法
用 set 的内置方法就把它当成是数学上的集,那么并集(or)、交集(and)、差集(-)都可以玩通了。
#并集
print( A.union(B) ) # All unique elements in A or B
print( A | B ) # A OR B
#交集
print( A.intersection(B) ) # All elements in both A and B
print( A & B ) # A AND B
#差集(A-B)
print( A.difference(B) ) # Elements in A but not in B
print( A - B ) # A MINUS B
#差集(B-A)
print( B.difference(A) ) # Elements in B but not in A
print( B - A ) # B MINUS A
#对称差集
print( A.symmetric_difference(B) ) # All elements in either A or B, but not both
print( A ^ B ) # A XOR B
| 方法 | 解释 |
|---|---|
| s.issubset(t),s <= t | 测试是否 s 中的每一个元素都在 t 中 |
| s.issuperset(t),s >= t | 测试是否 t 中的每一个元素都在 s 中 |
| s.union(t),s | t |
| s.intersection(t),s & t | 返回一个新的 set 包含 s 和 t 中的公共元素 |
| s.difference(t),s - t | 返回一个新的 set 包含 s 中有但是 t 中没有的元素 |
| s.symmetric_difference(t),s ^ t | 返回一个新的 set 包含 s 和 t 中不重复的元素 |
| s.copy() | 返回 set “s”的一个浅复制 |
优点缺点
- 优点:不用判断重复的元素
- 缺点:不能存储可变对象
参考文献
【1】: https://mp.weixin.qq.com/s/DZ589xEbOQ2QLtiq8mP1qQ

















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









