




一,基础概念
散列表,英文名是hash table,又叫哈希表。
散列表通常使用顺序表来存储集合元素,集合元素以一种很分散的分布方式存储在顺序表中。
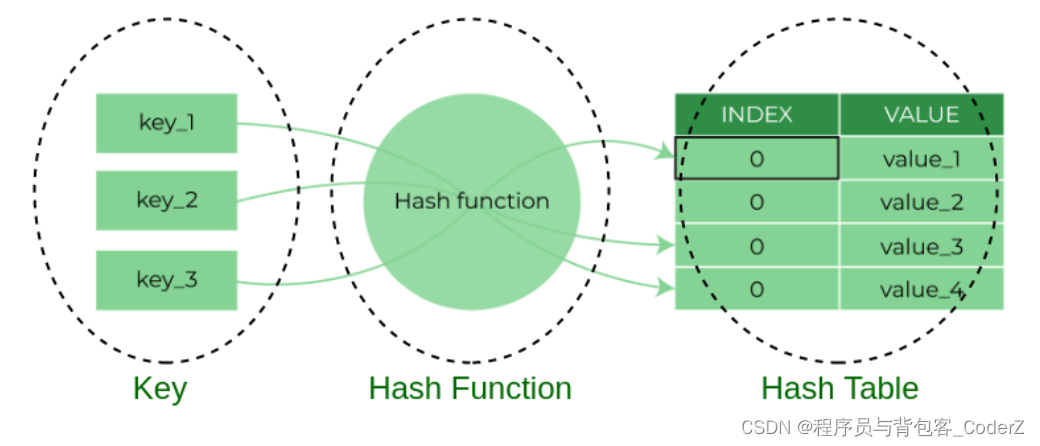
散列表是一个键值对(key-item)的组合,由键(key)和元素值(item)组成。键和它对应的元素值基于散列函数(hash function)进行一对一的映射,基于键查找到的元素值也可以称为散列值,查找公式:item = hash(key)。其中item可以是具体的值,也可以是具体的值对应的内存地址,也可以是链表或者链表的指针。
注意,有的教程里面喜欢把键值对称为(key, item),有的教程里面喜欢把键值对称为(index, value),其实是相同的意思。
散列表和数组相似的地方在于,都可以基于下标快速的访问数据,数组的下标是索引,散列表的下标是键。
散列表结构在生活中的抽象模型:一个班级所有学生的姓名和对应的学号。
二,散列表的图示结构
图一,key -> hash function -> hash table(key, item)
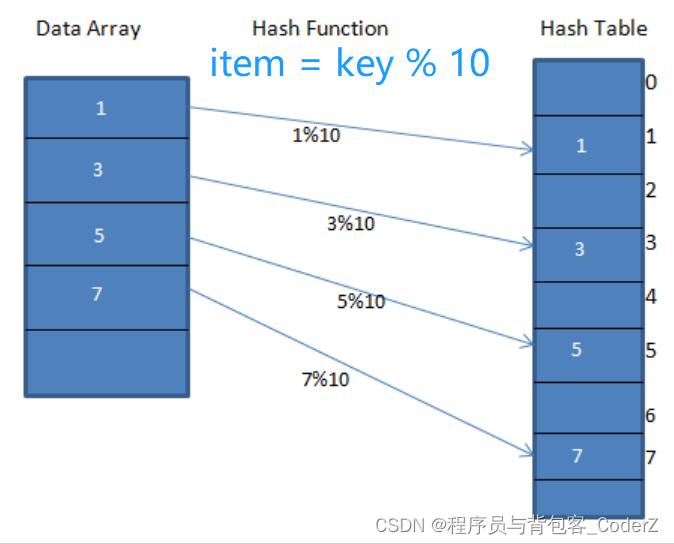
图二,哈希函数:item = key % 10
三,关于散列函数
最常见的散列函数:
除数留余法:item = (key + 5) % 10
例如:key=50, item = 5。key = 44, item = 9
好的散列函数具有以下特性:
函数的设计不过于复杂。
大部分情况下,使用相同的键只会查找到同一个值。
键和元素值要均匀随机分布。
基于键查找每个元素值的时间是近似的,而不是查找有的值耗时很长,查找有的值耗时很短。
发生散列冲突的概率极低。
四,散列冲突处理
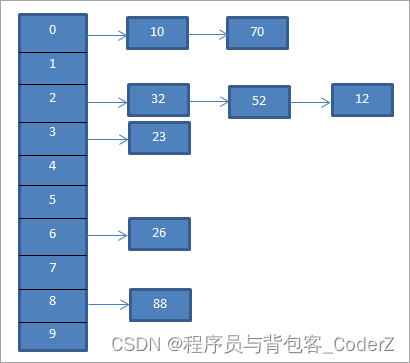
所谓散列冲突,是指不同的键映射到了相同的散列值。
例如,对于”item = key % 10“的哈希函数,key为12或者22得到的散列值都是2。

方式一,链表法
在链表法中,散列表中的每个key都映射到一个链表。因此,当两个key具有相同的item值时,这两个key都被添加到相同的链表中。
方式二,线性探测法
线性探测法是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1189
1189




 到【灌水乐园】发言
到【灌水乐园】发言









