





本文字数:15692;估计阅读时间:40 分钟
作者:Tom Schreiber
本文在公众号【ClickHouseInc】首发

TL;DR
我们从零开始重新构思了 ClickHouse 列式存储中的类 SQL UPDATE 实现方式。本文将详细介绍我们如何完成这一过程,从最初的重量级 mutation,到借助可扩展 patch part 实现的轻量级更新。性能基准测试将在第 3 部分发布。
曾被认为无法实现的更新
列式存储并不以快速更新著称。
长期以来,面向分析场景设计的系统通常会牺牲更新性能,以换取更快的读取速度。行级别的变更被认为与高吞吐、优化扫描的架构天然不兼容。
ClickHouse 也曾是如此,直到我们通过 *重新定义“更新”的本质*,打破了这一限制。
在 第 1 部分 中,我们介绍了 ClickHouse 采用的一种全新模型:将更新转换为插入。通过像 ReplacingMergeTree 和 CollapsingMergeTree 这样的专用引擎,系统可以异步地在后台通过合并操作完成更新,同时保持极高的写入性能。
不过,并不是所有用户都希望以“合并语义”的方式思考更新操作。许多用户只想简单地写出这样的 SQL 语句:
UPDATE orders
SET discount = 0.2
WHERE quantity >= 40;因此,我们希望在不牺牲 ClickHouse 性能优势的前提下,支持这种使用方式。
本文将介绍我们是如何实现这一目标的。
我们将带你了解 ClickHouse 中类 SQL 更新机制的演进过程:
-
经典的 mutation,虽然简单但代价较高;
-
向前迈进的一步:即时更新,无需等待 mutation 完成;
-
最终通过 patch part 实现快速声明式 SQL 更新,这是一种专为高频率工作负载设计、具备良好可扩展性的原生列式更新机制。
想了解性能表现?敬请关注第 3 部分。本文将聚焦于快速更新背后的架构设计。
我们先来回顾一下 ClickHouse 多年来所支持的基于 mutation 的传统 UPDATE 实现方式。
阶段 1:经典变更 (mutations) 与列重写
自 2018 年起,ClickHouse 就已经支持使用 ALTER TABLE... UPDATE(https://clickhouse.com/docs/sql-reference/statements/alter/update) 语句进行类 SQL 的更新操作。
我们将继续沿用 第 1 部分 中的 orders 表示例,来说明 UPDATE 在底层是如何通过 mutation 实现的:
CREATE TABLE orders (
order_id Int32,
item_id String,
quantity UInt32,
price Decimal(10,2),
discount Decimal(5,2)
)
ENGINE = MergeTree
ORDER BY (order_id, item_id);下面我们将从一次初始插入操作开始,逐步剖析一个简单的 UPDATE 如何在底层触发 mutation 过程。
初始插入
我们从一个包含同一订单中两个商品的 part 开始:
INSERT INTO orders VALUES
(1001, 'kbd', 10, 45.00, 0.00),
(1001, 'mouse', 6, 25.00, 0.00);这将生成一个名为 all_1_1_0 的数据 part(命名规则详见此处(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#how-to-read-a-part-name)):

UPDATE 会触发变更
接下来,我们对其中鼠标商品的数量和折扣进行了更新:
ALTER TABLE orders
UPDATE quantity = 60, discount = 0.20
WHERE order_id = 1001 AND item_id = 'mouse';ALTER TABLE ... UPDATE 的语法特意与 标准 SQL UPDATE(https://www.w3schools.com/sql/sql_update.asp) 不同,以反映底层的实际机制:ClickHouse 并不会就地修改行数据,而是通过重写数据 part(即执行 mutation)来完成更新。
由于执行了 UPDATE,ClickHouse 在后台触发了一次 mutation(https://clickhouse.com/docs/sql-reference/statements/alter#mutations) 操作。这个过程包括三个内部步骤:
-
系统会为此次更新 分配一个新的块号(如 2),用于标记哪些 part 需要被重写(可参考part 的块结构(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#how-blocks-make-up-a-part))。
2. 然后在磁盘上创建一个新的 更新后 part,命名为 all_1_1_0_2,其中的数字 `2` 表示此次 mutation 的版本号。
3. mutation 仅适用于块号小于 2 的 part,例如最初的 all_1_1_0。
下图展示了更新发生的情况:被修改的列(quantity 和 discount)会被完全重写;未修改的列(如 order_id、item_id、price)则通过硬链接(https://en.wikipedia.org/wiki/Hard_link) 的方式进行复用。这些列的数据文件不会被复制,新的 part 直接复用磁盘上的原始文件:
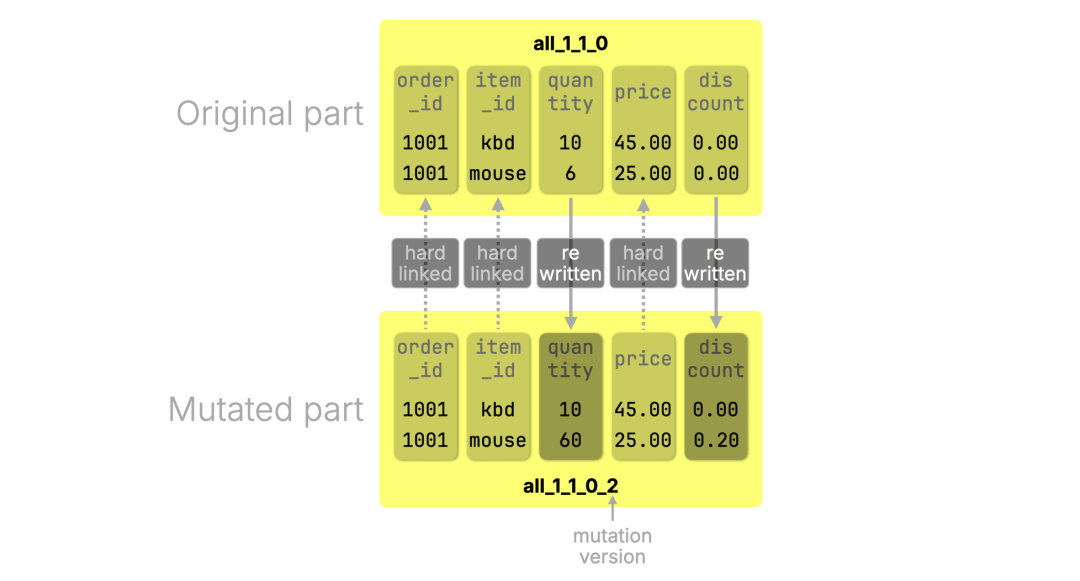
当 mutation 完成后,新的 part all_1_1_0_2 会替换原始的 all_1_1_0,后者随即被移除。尽管原始的 目录(https://clickhouse.com/blog/updates-in-clickhouse-1-purpose-built-engines#whats-inside-a-part) 及其文件项会被删除,但只要新的 part all_1_1_0_2 仍然通过硬链接引用原有的列文件,这些数据仍会安全地保留在磁盘中。硬链接机制可以确保文件只有在没有任何引用存在时才会真正被删除。
总结与权衡
这种经典的 mutation 模型具有较强的可靠性,但也伴随着一些代价:
-
更新成本较高:每次 UPDATE 都需要重写被修改的列,面对大规模数据时代价不菲;
-
可见性延迟:更新结果在后台 mutation 完成之前不会反映到查询中;
-
依赖合并操作:mutation 必须等前面的合并或 mutation 操作完成之后才能执行。(这部分内容在本文中未详细展开,但它确实存在,并且在某些情况下可能带来意想不到的限制。)
默认(https://clickhouse.com/docs/operations/settings/settings#mutations_sync)情况下,ALTER TABLE … UPDATE 语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









