






本文字数:20366;估计阅读时间:51 分钟
作者:Rory Crispin
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

引言
我们始终认为在可能的情况下要充分利用我们自己的技术,尤其是在解决我们认为 ClickHouse 擅长解决的挑战时。去年,我们详细介绍了我们如何利用 ClickHouse 构建内部的数据仓库以及我们所面临的挑战。在本文中,我们将探讨另一个内部使用案例:可观测性,以及我们如何利用 ClickHouse 满足内部需求,并存储 ClickHouse Cloud 生成的大量日志数据。正如后文所述,这一举措每年为我们节省了数百万美元,并使我们能够无需担心可观测性成本,也不必在保留的日志数据上做出妥协。
为了让其他人分享我们的经验,我们提供了我们自己使用 ClickHouse 的日志记录解决方案的详细信息,这个解决方案仅在我们的 AWS 区域就包含了超过 19 PiB 的未压缩数据,相当于 37 万亿行数据。在设计上,我们的通用理念是尽量减少移动部件的数量,并确保设计尽可能简单且易于复制。
如我们稍后在价格分析部分所展示的,相比于 Datadog,对于我们的工作负载来说,ClickHouse 的费用至少是 Datadog 的 200 倍之下,这是基于 Datadog 和 AWS 的 ClickHouse 托管服务以及在 S3 中存储数据的价格列表所得出的结论。
一个小团队面对巨大挑战
在一年多前我们首次推出 ClickHouse Cloud 初始版本时,我们面临了抉择。尽管我们当时意识到 ClickHouse 可以用于构建可观测性解决方案,但我们的首要任务是构建云服务本身。为了尽快提供一流的服务,我们最初选择了 Datadog 作为公认的云可观测性市场领导者,以加速上市进程。
虽然这一举措使我们迅速将 ClickHouse Cloud 推向 GA 阶段,但很快就意识到 Datadog 的账单成本是无法持续的负担。由于 ClickHouse 服务器和 Keeper 日志占我们收集的日志数据的 98%,我们的数据量实际上会随着我们部署的集群数量呈线性增长。
我们最初面对这一挑战时,采取了大多数 Datadog 用户可能会被迫采取的做法 - 考虑限制数据保留时间以减少成本。虽然将数据保留时间限制在 7 天可能是控制成本的有效手段,但这与我们用户(我们的核心和支持工程师调查问题)的需求以及提供一流服务的主要目标直接相冲突。如果在 ClickHouse 中发现问题(是的,我们有 bug),我们的核心工程师需要能够搜索所有集群中所有日志,最长可达 6 个月。
针对 30 天的保留期(远远低于我们的 6 个月需求),在任何折扣之前,Datadog 每百万事件的列出价格为 2.5 美元,每 GB 吞入的价格为 0.1 美元(假设年度合同),这意味着我们目前每月处理 5.4 PiB/10.17 万亿行的数据,预计成本为每月 2600 万美元。至于所需的 6 个月保留期,呃,我们干脆不去考虑了。
选择 ClickHouse
通过大规模操作 ClickHouse 的经验,我们知道对于相同的工作负载来说,它会显著降低成本。同时,我们也看到其他公司已经在 ClickHouse 上构建了他们的日志解决方案(例如,highlight.io 和 Signoz),因此我们将优先级放在将我们的日志数据存储迁移到 ClickHouse,并组建了一个内部的可观测性团队。在不到三个月的时间里,我们的 1.5 名全职工程师小团队着手构建了我们基于 ClickHouse 的日志平台 “LogHouse”!
我们的内部可观测性团队的职责不仅限于 LogHouse。我们的任务更广泛,旨在帮助 ClickHouse 的工程师了解我们运行的 ClickHouse Cloud 中所有集群的情况。因此,我们提供了一系列服务,包括用于主动检测需要解决的集群行为模式的警报服务。
问题的严重性
截至目前,ClickHouse Cloud 已经在 9 个 AWS 区域和 4 个 GCP 区域提供服务,Azure 的支持也即将到来。我们最大的区域每秒产生超过 110 万条日志行。考虑到所有 AWS 区域,这就产生了一些惊人的数字:
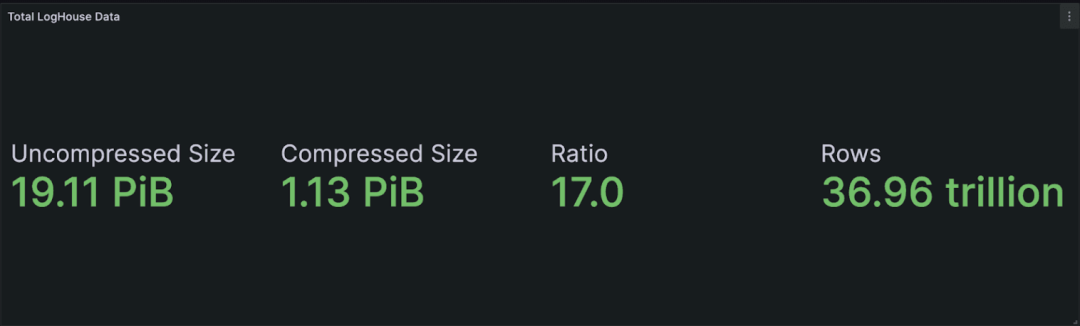
这里可能一眼就能看出我们所达到的压缩水平 - 19 PiB 的数据压缩后仅约为 1.13 PiB,相当于约 17 倍的压缩比。ClickHouse 实现的这种高压缩水平对项目的成功至关重要,它使我们能够以高效的成本扩展,并且仍然保持良好的查询性能。
我们 LogHouse 环境的总数据量目前超过了 19 PiB。这个数字仅考虑了我们的 AWS 环境。
ClickHouse Cloud 基础架构
我们之前的文章已经介绍了 ClickHouse Cloud 的架构。与我们的日志解决方案相关的关键架构特征是,ClickHouse 实例作为 Kubernetes 中的 pods 部署,并由自定义的 operator 进行管理。
Pods 将日志记录到 stdout 和 stderr,并由 Kubernetes 按照标准配置捕获为文件。然后,OpenTelemetry 代理可以读取这些日志文件并将它们转发到 ClickHouse。
尽管大部分数据来自 ClickHouse 服务器(在高负载下,某些实例每秒可记录 4,000 行),以及 Keeper 日志,但我们也从云数据平面收集数据。这包括运行在节点上的我们的 operator 和支持服务的日志。对于 ClickHouse 集群编排,我们依赖于 ClickHouse Keeper(由我们的核心团队开发的 C++ ZooKeeper 替代品),它产生了涉及集群操作的详细日志。尽管 Keeper 日志在任何时刻占据了大约 50% 的流量(相比之下,ClickHouse 服务器日志为 49%,数据平面为 1%),但该数据集的保留时间较短,仅为 1 周(与服务器日志的 6 个月相比),因此它只占整体数据的很小比例。
在 ClickHouse Cloud 上构建
由于我们正在监控 ClickHouse Cloud,所以驱动 LogHouse 的集群不能与 ClickHouse Cloud 基础架构共存 - 否则,我们就会在被监视的系统和监控工具之间创建依赖关系。
然而,我们仍然希望从 ClickHouse Cloud 背后的技术中受益 - 具体来说,我们希望利用 SharedMergeTree 表引擎的技术,实现存储和计算的分离。这样做主要是为了使我们能够受益于将数据存储在具有大型 NVMe 缓存的 S3 中,同时允许我们几乎无限地扩展我们的集群宽度。考虑到我们的数据量会随着吸引更多客户而不断增加,我们不希望因为磁盘空间限制而不得不部署更多的集群和/或节点。通过将所有数据存储在 S3 中,并让节点仅使用本地 NVMe 作为缓存,我们可以轻松扩展并专注于数据本身。
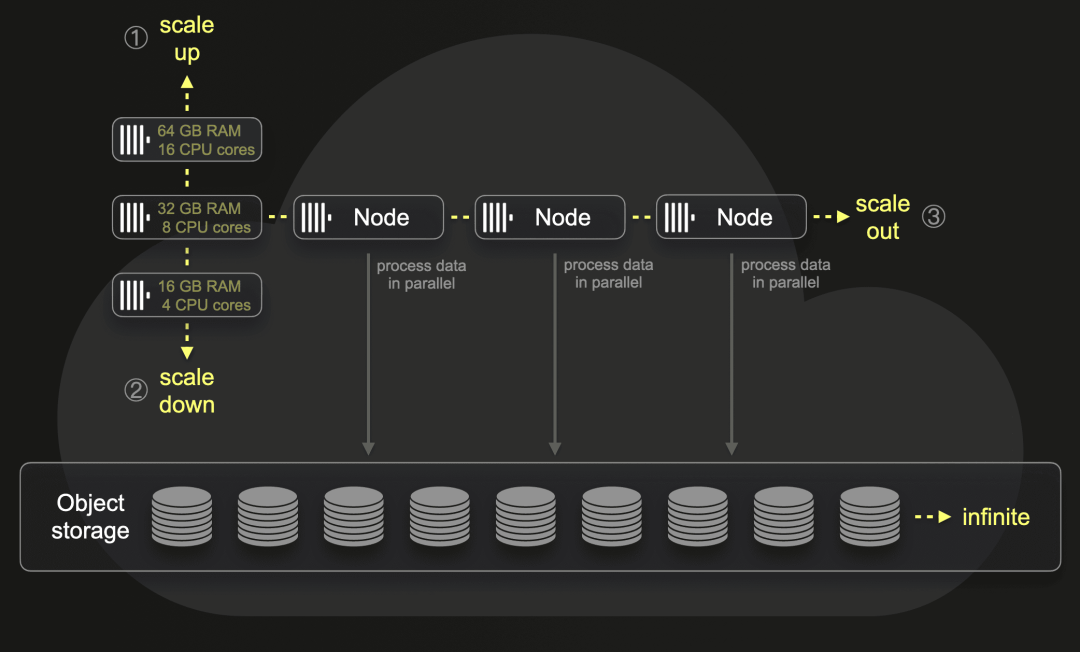
因此,在每个区域,我们都运行着我们自己的 “微型 ClickHouse Cloud”(见下文),甚至使用了 ClickHouse Cloud 的 Kubernetes operator。能够使用 “云” 对于我们在如此短的时间内构建解决方案并以小团队管理基础架构至关重要。我们确实受益于巨人(也就是 ClickHouse 核心团队)的成果。
尽管这个解决方案是针对我们需求量身定制的,但它实际上相当于 ClickHouse Cloud 的专用层级(Dedicated Tier)提供,客户的集群部署在专用基础设施上,使他们能够控制部署的各个方面,如更新和维护窗口。最重要的是,其他想要复制我们解决方案的用户不会受到相同的循环依赖约束,他们只需使用 ClickHouse Cloud 集群即可。
我们目前正在将内部集群(如 LogHouse)迁移到我们的 ClickHouse Cloud 基础设施中。在这里,它将被隔离在一个单独的 Kubernetes 集群中,但除此之外,它将是一个与我们的客户使用的 “标准” ClickHouse Cloud 集群完全相同的集群。
了解您的用户
使用 ClickHouse 进行日志存储意味着用户必须接受基于 SQL 的观测性。换句话说,用户可以舒适地使用 SQL 和 ClickHouse 的丰富字符串匹配和分析函数来搜索日志。这种采用通过可视化工具(如 Grafana)变得更加简单,Grafana 提供了常见观测操作的查询构建器。
在我们的情况下,我们的用户对 SQL 非常熟悉,因为他们是 ClickHouse 的支持和核心工程师。尽管这有利于查询通常经过了严格的优化,但也带来了一系列挑战。尤其是,这些用户是高级用户,他们只会在最初的分析阶段使用基于可视化的工具,然后希望直接通过 ClickHouse 客户端连接到 LogHouse 实例。这意味着我们需要一种简便的方法让用户能够轻松地在任何仪表板和客户端之间进行切换。
在大多数情况下,对云问题的调查是由 Prometheus 收集的集群指标触发的警报启动的。这些警报会检测到可能存在问题的行为(例如大量零件),需要进行调查。或者,客户可能会通过支持渠道提出问题,指出异常行为或无法解释的错误。
一旦需要进行更深入的分析,日志就变得关键。到了这个阶段,我们的支持或核心工程师已经确定了客户集群、其区域和相关的 Kubernetes 命名空间。这意味着大多数搜索都是根据时间和一组 pod 名称进行过滤的 - 后者可以从 Kubernetes 命名空间中轻松识别出来。
我们稍后展示的模式经过了优化,以适应这些特定的工作流程,并有助于在多 PB 规模下实现出色的查询性能。
一些早期设计决策
以下早期设计决策对我们最终的架构产生了重要影响。
不跨区域传输数据
首先,我们不会跨区域传输日志数据。考虑到即使是较小的区域也会产生大量数据,从数据出口成本的角度来看,集中式日志记录并不可行。相反,我们在每个区域都部署了一个 LogHouse 集群。正如我们将在后文讨论的那样,用户仍然可以跨区域
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









