






 本文详细介绍了一款针对智联招聘网站的Scrapy爬虫项目,包括项目结构、设置、爬虫逻辑及MongoDB数据存储流程。通过分析职位、公司、城市和薪资等字段,实现招聘信息的有效抓取。
本文详细介绍了一款针对智联招聘网站的Scrapy爬虫项目,包括项目结构、设置、爬虫逻辑及MongoDB数据存储流程。通过分析职位、公司、城市和薪资等字段,实现招聘信息的有效抓取。
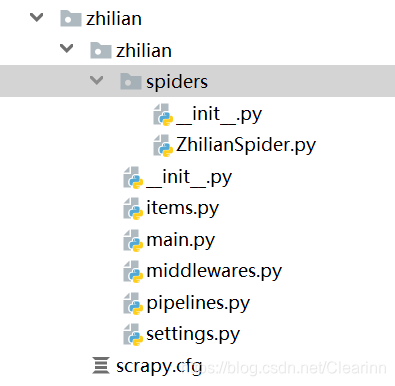
一.项目目录结构
二.模块划分
1.settings
# -*- coding: utf-8 -*-
# Scrapy settings for zhilian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'zhilian'
SPIDER_MODULES = ['zhilian.spiders']
NEWSPIDER_MODULE = 'zhilian.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zhilian (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'zhilian.middlewares.ZhilianSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'zhilian.middlewares.ZhilianDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'zhilian.pipelines.ZhilianPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2.main
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','zhilian'])
3.items
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ZhilianItem(scrapy.Item):
# define the fields for your item here like:
position = scrapy.Field()
company = scrapy.Field()
city = scrapy.Field()
salary = scrapy.Field()
4.ZhilianSpider
import scrapy
from ..items import ZhilianItem
import json
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
class Zhilian_Spider(scrapy.Spider):
name = 'zhilian'
def start_requests(self):
for i in range(0,1080,90):
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=90&cityId=601&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E9%94%80%E5%94%AE&kt=3&=0&_v=0.41352509&x-zp-page-request-id=fabc345dbbae4931a317f751a3952ec5-1572513651825-763363&x-zp-client-id=2a5a1b79-d92c-486f-e0e7-85a94b7837b2'.format(i)
yield scrapy.Request(url=url,headers=headers)
def parse(self, response):
res = response.text
datas = json.loads(res)['data']['results']
# print(datas)
# print(type(datas))
# print(len(datas))
for data in datas:
try:
info = ZhilianItem()
jobname = data.get('jobName')
salary = data.get('salary')
company = data.get('company').get('name')
city = data.get('city').get('items')[0].get('name')
print(jobname,salary,company,city)
# 对info字典进行赋值
info['position'] = jobname
info['company'] = company
info['city'] = city
info['salary'] = salary
yield info
except:
pass
5.pipelines
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
#建立一个连接
# conn = pymongo.MongoClient("mongodb://localhost:27017")
conn = pymongo.MongoClient(host='localhost',port=27017)
#选择使用哪个数据库
mydb = conn['test']
#使用哪个集合
myset = mydb['info']
class ZhilianPipeline(object):
def process_item(self, item, spider):
infomations = {
'position':item['position'],
'company':item['company'],
'city':item['city'],
'salary':item['salary'],
}
myset.insert(infomations)
return item
注意:智联招聘url变化的是cityid,每个城市下有12页(不一定),页数start利用循环每次加90

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









