




 该博客介绍了一种用于细粒度视觉分类(FGVC)的新型Transformer框架——TransFG。TransFG利用Transformer的自注意力机制,通过部分选择模块(PSM)和对比特征学习来增强对关键图像区域的识别。它通过选择高权重token并应用对比损失来改进特征学习,从而提升网络区分微妙类间差异的能力。实验部分展示了TransFG在数据集上的表现。
该博客介绍了一种用于细粒度视觉分类(FGVC)的新型Transformer框架——TransFG。TransFG利用Transformer的自注意力机制,通过部分选择模块(PSM)和对比特征学习来增强对关键图像区域的识别。它通过选择高权重token并应用对比损失来改进特征学习,从而提升网络区分微妙类间差异的能力。实验部分展示了TransFG在数据集上的表现。
目录
用细粒度识别Transformer架构
一、动机
由于固有的微妙的类间差异,从子类别中识别对象的细粒度视觉分类(FGVC)是一项非常具有挑战性的任务。通过关注如何定位最具辨别力的图像区域,并依靠它们来提高网络捕获细微差异的能力来解决这个问题。Transformer的自注意力机制将每个token标记链接到分类标记,可以直观的将注意力链接的强度视为token重要性的指标。提出一种新的基于Transformer的框架TransFG。
二、方法
2.1 大致流程
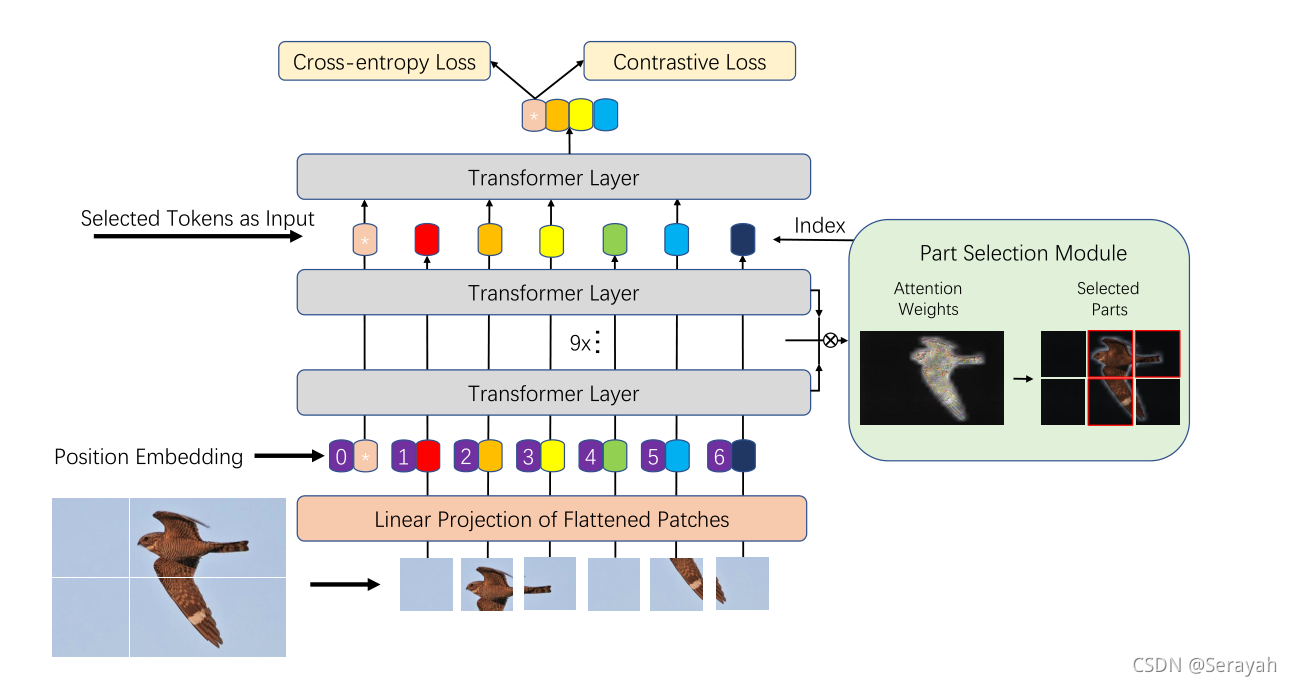
图像序列化——碎片嵌入——TransFG
2.2 步骤分解
1、图像序列化
为了保留局部相邻结构,采取滑动窗口生成重叠碎片。滑动窗口大size为P,step为S;因此两个相邻的碎片共享一个大小为(P-S)*P的重叠区域
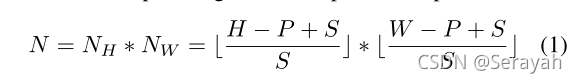
2、碎片嵌入
将可训练的碎片映射到潜在的D维嵌入空间,将可学习的位置嵌入添加到碎片嵌入中以保留位置信息。
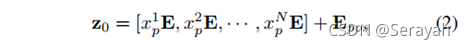
3、TransFG层
ViT回顾:
单个Transformer层可以表示成如下:
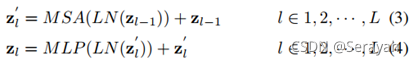
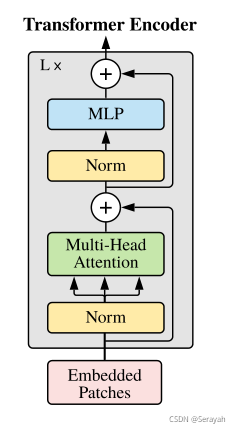
TransFG主要有两部分不同:部分选择模块(PSM)和对比特征学习
部分选择模块:
为了充分利用注意力信息,将改变最后一层的输入,对最后一层前面的所有层的权重累乘,选出
然后选择权重最大的A_k个token作为最后一层的输入。

对比特征学习:
因为简单的交叉熵损失函数不足以完全监督特征学习,因为子类别之间的差异可能非常小。
采用对比损失最小化不同标签对应的分类token的相似度,最大化具有相同标签y的样的分类token的相似度
z:token y:标签 sim():相似性函数
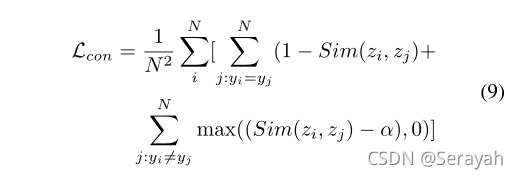
总之,最后的模型是用交叉熵损失和对比损失的综合训练的:(trick:可以用两个损失函数结果的运算来构成一个“新的”损失函数)
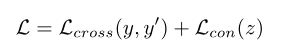
三、实验
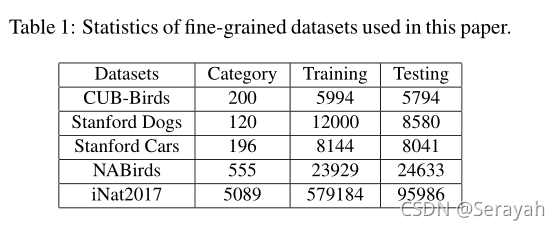
3.1 数据集

















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









