







 本文介绍如何使用Hive SQL对服务器返回数据中的URL参数进行过滤,以解决乱码问题。通过将URL切割、排序并利用ASCII码判断,有效过滤了99%的脏字符串。
本文介绍如何使用Hive SQL对服务器返回数据中的URL参数进行过滤,以解决乱码问题。通过将URL切割、排序并利用ASCII码判断,有效过滤了99%的脏字符串。
接收到服务器端传回来的数据以后,入到了hive表当中,发现一些url 的传参是乱码的。这时候,需要进行过滤。
例如:
select uri from table limit 10;
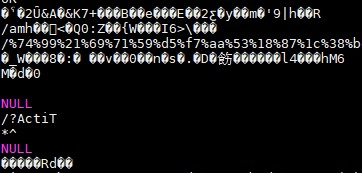
在ascii 码表中,可见字符的范围是:32~126
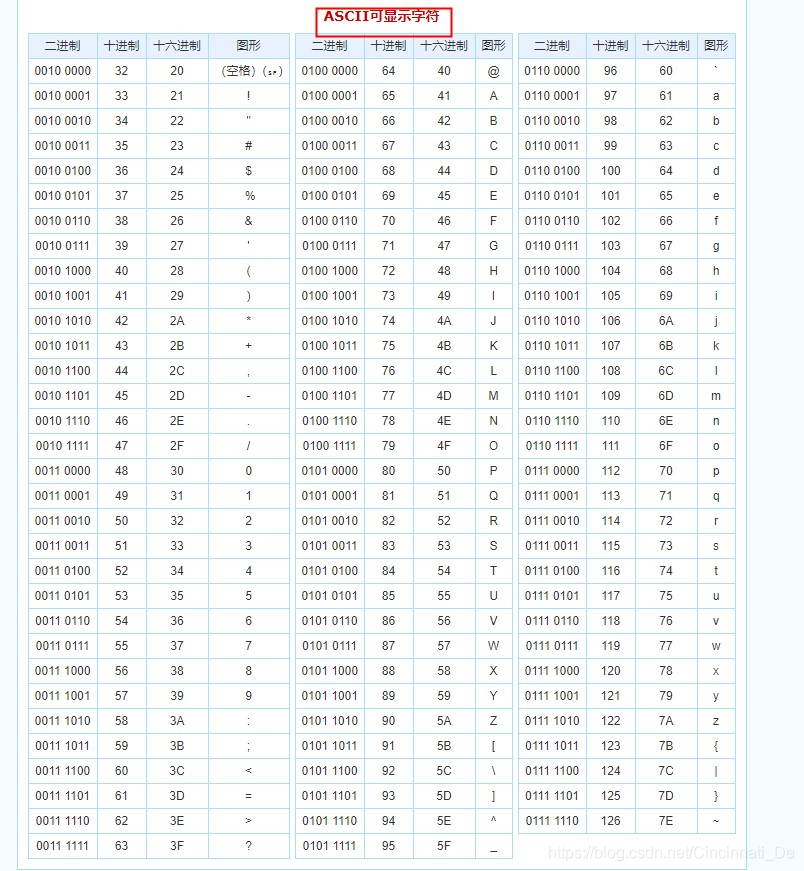
利用这个思路,在写sql的时候步骤如下:
1、将url进行切割 例如:
new-project?email-verification=true---> 切割成 tocharArray形式

2、对数组进行排序:

这里有三个小地方要注意
a. split的"" 默认是切割每个字符返回一个数组。
b. 切割后,有"" 这个总是有的。
c. 排序是按照ascii 码来排序的
3、分别获取最大和最小的 那个元素 "" 除外
sort_array(xxx)[length(uri)-1]
sort_array(xxx)[1]
4、 利用ascii 函数进行 解析字符,判断在 between 32 and 126 之间
最后
一句sql
select uri from table where yyyymmdd between '20181201' and '20181203'
and ascii(sort_array((split(uri,'')))[1]) between 32 and 126
and ascii(sort_array((split(uri,'')))[length(uri)-1]) between 32 and 126
反正我不太好使,结果仍然有一些乱码,我又加了一句
select uri from table where yyyymmdd between '20181201' and '20181203'
and ascii(sort_array((split(uri,'')))[1]) between 32 and 126
and ascii(sort_array((split(uri,'')))[length(uri)-1]) between 32 and 126
and ascii(sort_array((split(uri,'')))[length(uri)-1]) > 0
基本过滤了 99%的 脏 字符串了。 剩下的 1% ,没办法了。。
如果本文帮助了您,请点个赞。谢谢
有一些优化的瑕疵,可与留言,

















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









