







基于3.2版本分支。
BypassMergeSortShuffleWriter
简化流程图
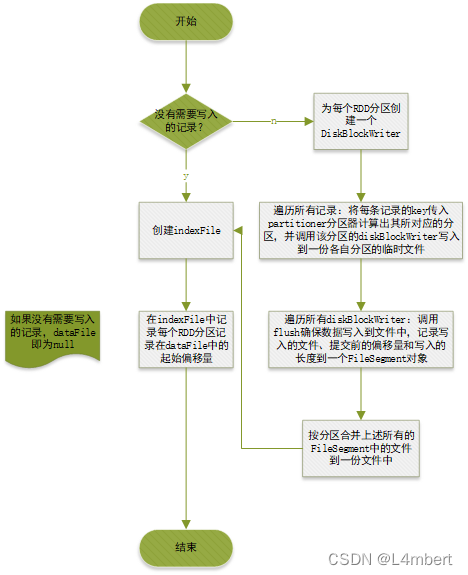
示例
也就是说每个ShuffleMapTask都会对应着一个FileSegment,每个FileSegment可视作一个临时文件,接着这些FileSegment中对应的文件又会合并到一份DataFile中,通过IndexFile记录每个分区在DataFile中的起始偏移量。
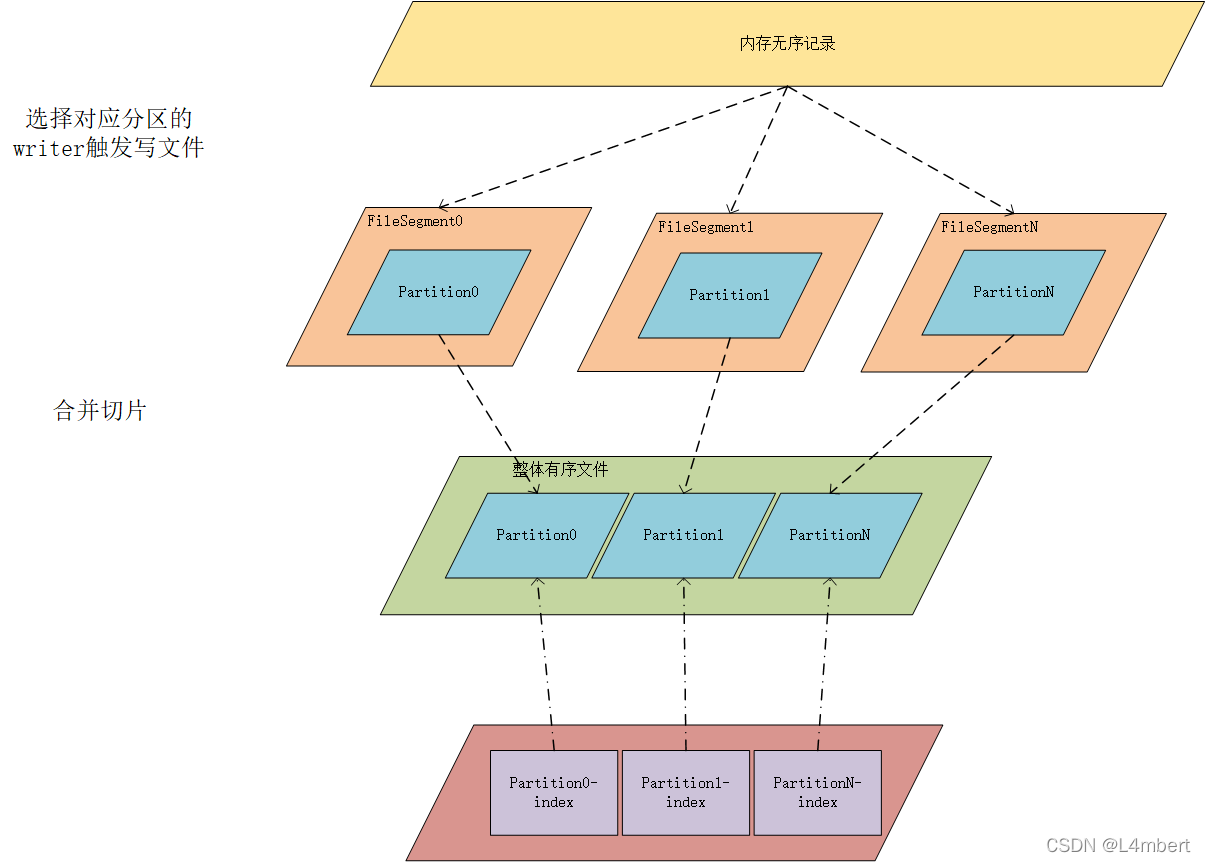
这种Shuffle写文件方式是有可能造成大量小文件给文件系统造成压力的情况,因此在选用该ShuffleWriter写入方式时做了限定默认只有<200分区方可使用BypassMergeSortShuffleWriter。为每个分区生成一个FileSegment后,会这些文件合并到一份数据文件中,并索引文件记录了每个分区在数据文件中的偏移量,能够做到随机访问指定RDD分区的数据。
有兴趣可详读BypassMergeSortShuffleWriter#write的实现,这里我给出关键注释:
// BypassMergeSortShuffleWriter.java
public void write(Iterator<Product2<K, V>> records) throws IOException {
assert (partitionWriters == null);
ShuffleMapOutputWriter mapOutputWriter = shuffleExecutorComponents
.createMapOutputWriter(shuffleId, mapId, numPartitions);
try {
// 没有需要写的记录,直接提交,结束
if (!records.hasNext( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









