




 本文详细分析了DolphinScheduler DAO模块下的实体类,包括ProcessData、TaskDefinition和TaskInstance。讨论了实体类中涉及的List接口、Map接口、Objects类的常用方法,以及Jackson库在序列化与反序列化中的使用策略和JsonNode在JSON操作中的作用。此外,还提到了Java对象序列化的重要性。
本文详细分析了DolphinScheduler DAO模块下的实体类,包括ProcessData、TaskDefinition和TaskInstance。讨论了实体类中涉及的List接口、Map接口、Objects类的常用方法,以及Jackson库在序列化与反序列化中的使用策略和JsonNode在JSON操作中的作用。此外,还提到了Java对象序列化的重要性。
2021SC@SDUSC
DophinScheduler dao模块下实体代码详情分析
ProcessData实体下:
![]()
引入![]()
java.util.List接口:
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组,List允许有相同的元素。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
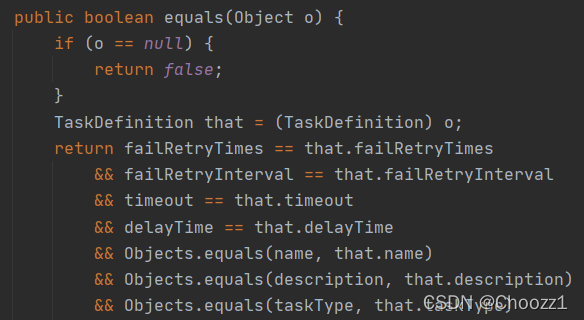
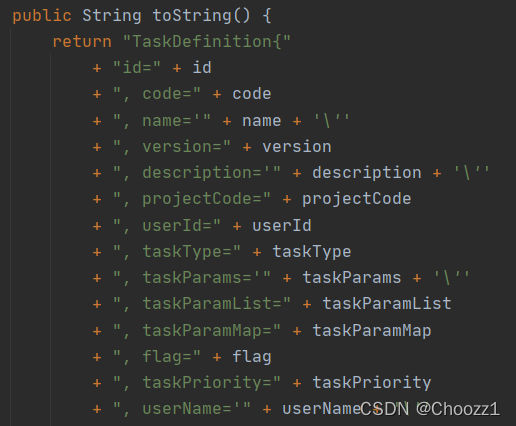
TaskDefinition实体下:
![]()
![]()
map接口:
Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
![]()
java.util.Objects 类:
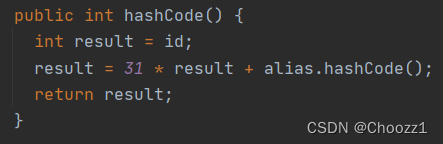
包含了几个静态方法,可以实现对对象的比较、生成hash code之类的功能,很多方法里考虑了对象是null的情况,在输入的参数是null时有特定的处理方式。经常出现的equals()、hashcode()、tostring()方法都是包含在该类里的
1.public static boolean equals(Object a, Object b)
比较对象a和对象b,使用的是第一个参数的equals()方法,
如果两个参数中有一个是null,则返回false,
如果两个参数都是null,则返回true。
2.public static int hashCode(Object o)
得到一个对象的hash code,如果参数为null,返回0
3.public static String toString(Object o)
调用对象的toString()方法,如果参数是null,返回字符串"null"
![]()
流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。

jackson使用@JsonDeserialize与@JsonSerialize控制序列化与反序列化使用的实际类型:
默认情况下,序列化时会获取对象的实际类型,然后根据可见性规则,获取对象以及其父类的所有属性进行序列化
默认情况下,反序列化时,如果使用的对象类型、属性类型不是最终类型,而是接口或者抽象类型,如Map接口等,此时jackson会选择一种常用的实现类来进行反序列化,如Map->HashMap,List->ArrayList,Set->HashSet等
如果在序列化时只想序列化对象某父级类型的属性,反序列化时希望指定接口或者抽象类型的实现类,jackson提供了以下注解:
. JsonDeserialize:通过as属性控制反序列化后最终的实现类
. JsonSerialize:通过as属性控制序列化时使用的实际父类
![]()
jackson.jsonNode是Jackson的json树模型(对象图模型)。Jackson能读JSON至JsonNode实例,写JsonNode到JSON。
TaskInstance实体下:
![]()
类通过实现java.io.Serializable接口可以启用其序列化功能。未实现次接口的类无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。序列化接口没有方法或字段,仅用于标识可序列化的语义。
要想序列化对象,必须先创建一个OutputStream,然后把它嵌进ObjectOutputStream。这时,就能用writeObject()方法把对象写入OutputStream了。

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









