



实验内容
爬取新闻网站数据,并搭建网站可视化爬取结果。本次实验使用爬取了中国新闻网、网易新闻、搜狐新闻三个代表性的新闻网站数据并存储在mySQL数据库中,并利用Angular和express脚手架建立网站提供对爬取内容的分项全文搜索、关键词的时间热度分析、词云图展示三个功能。
实验环境
- 系统环境:macOS Monterey 12.3
- 开发环境:Visual Studio Code 1.69
- 语言版本:Node.js 16.15.1
实验过程
新闻爬虫
本次实验使用爬取了中国新闻网、网易新闻、搜狐新闻三个代表性的新闻网站。针对不同网站的新闻页面进行分析,爬取出编码、标题、作者、时间、关键词、摘要、内容、来源等结构化信息,并将爬取到的结果存储在mySQL数据库中。
请求模块
使用request方法构造一个模仿浏览器的request来获取网页内容,并将浏览器的user-agent信息填充到headers参数中,从而模拟浏览器,避免被待爬取的目标新闻网站屏蔽。此外,我们通过使用回调函数来异步地爬取网页的url,提高爬取效率。
var myRequest = require('request');
//防止网站屏蔽我们的爬虫
var headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36'
}
//request模块异步fetch url
function request(url, callback) {
var options = {
url: url,
encoding: null,
//proxy: 'http://x.x.x.x:8080',
headers: headers,
timeout: 10000 //
}
myRequest(options, callback)
};
网页信息提取模块
读取种子页面,解析出种子页面里所有的链接。
//用iconv转换编码
var html = myIconv.decode(body, myEncoding);
//准备用cheerio解析html
var $ = myCheerio.load(html, { decodeEntities: true });
var seedurl_news;
try {
seedurl_news = eval(seedURL_format);
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
遍历种子页面里所有的链接,并规整化所有链接,如果符合新闻URL的正则表达式就爬取,并将爬取到的内容保存在fetch对象中。
seedurl_news.each(function(i, e) { //遍历种子页面里所有的a链接
var myURL = "";
try {
//得到具体新闻url
var href = "";
href = $(e).attr("href");
if (href == undefined) return;
if (href.toLowerCase().indexOf('http://') >= 0) myURL = href; //http://开头的
else if (href.startsWith('//')) myURL = 'http:' + href; ////开头的
else myURL = seedURL.substr(0, seedURL.lastIndexOf('/') + 1) + href; //其他
} catch (e) { console.log('识别种子页面中的新闻链接出错:' + e) }
if (!url_reg.test(myURL)) return; //检验是否符合新闻url的正则表达式
var fetch_url_Sql = 'select url from fetches where url=?';
var fetch_url_Sql_Params = [myURL];
mysql.query(fetch_url_Sql, fetch_url_Sql_Params, function(qerr, vals, fields) {
if (vals == null || vals.length == 0) {
newsGet(myURL);
} else{
console.log('URL duplicate!');
} //读取新闻页面
});
});
注:需要在浏览器中查看网站页面的源文件,根据页面源文件信息来书写正则表达式提取结构化的信息。下面以搜狐新闻为例进行说明。
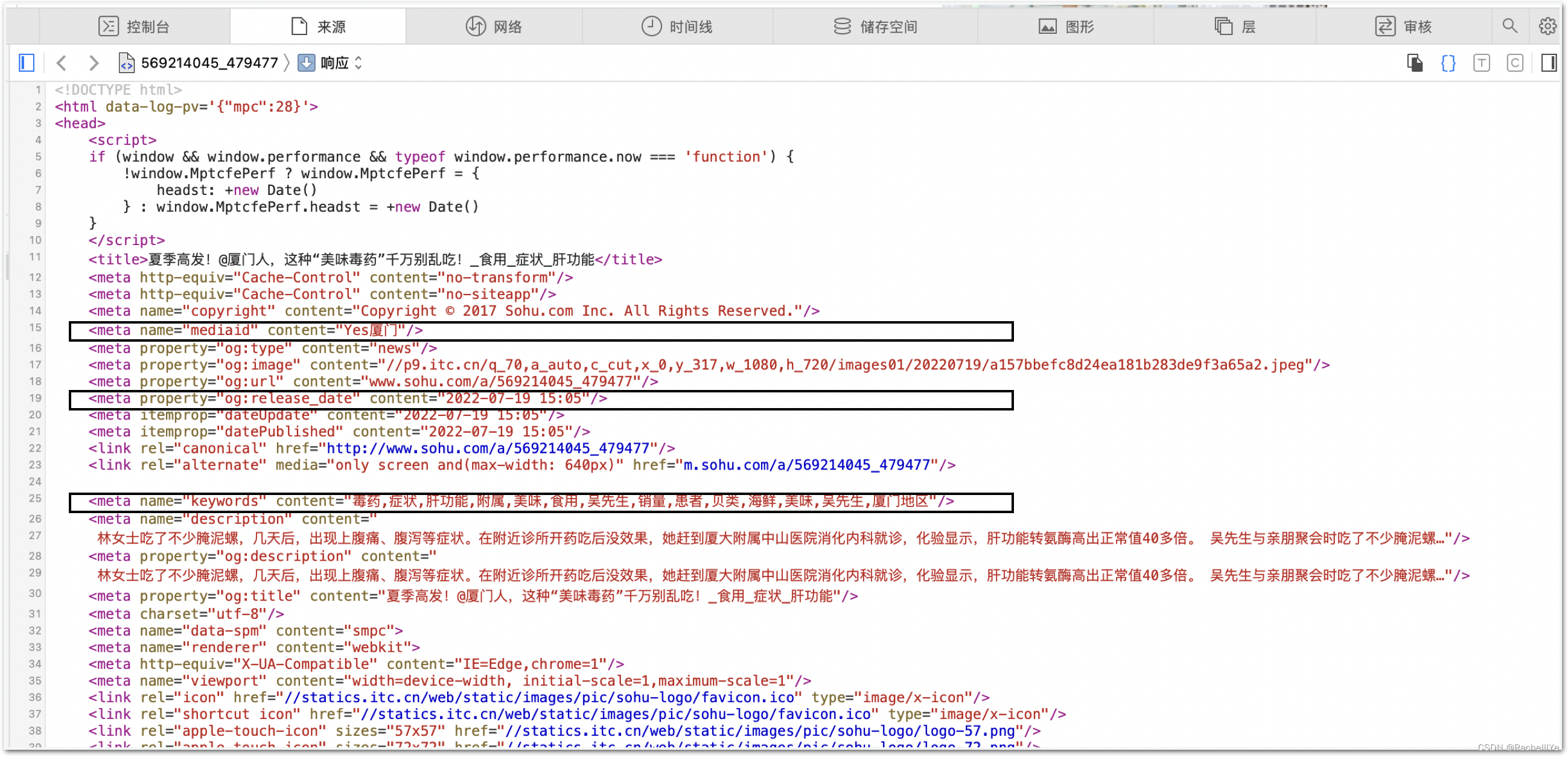
var source_name = "搜狐新闻";
var domain ='https://sports.sina.com.cn';
var myEncoding = "utf-8";
var seedURL = 'https://sports.sina.com.cn';
var seedURL = 'http://news.sohu.com/';//主页面
var seedURL_format = "$('a')";//寻找子页面
var keywords_format = "$('meta[name=\"keywords\"]').eq(0).attr(\"content\")";//关键词
var title_format = "$('title').text()";//标题
var date_format = "$('meta[property=\"og:release_date\"]').eq(0).attr(\"content\")";//日期
var author_format = "$('meta[name=\"mediaid\"]').eq(0).attr(\"content\")";//编辑
var content_format = "$('article').text()";//文章
var url_reg = /\/a\/(\d{9})\_/;//用于匹配主页面中的新闻子页面的正则表达式
var source_format = "";
数据库存储模块
每次爬取页面前先查询数据库,若该url已经爬取过,则不会重复爬取,若未爬取过,则爬取相应的网站信息并存储在数据库中。
//判断该url是否爬取过
var fetch_url_Sql = 'select url from fetches where url=?';
var fetch_url_Sql_Params = [myURL];
mysql.query(fetch_url_Sql, fetch_url_Sql_Params, function(qerr, vals, fields) {
if (vals == null || vals.length == 0) {
newsGet(myURL);
} else{
console.log('URL duplicate!');
}
});
var fetchAddSql = 'INSERT INTO fetches(url,source_name,source_encoding,title,' +
'keywords,author,publish_date,crawltime,content) VALUES(?,?,?,?,?,?,?,?,?)';
var fetchAddSql_Params = [fetch.url, fetch.source_name, fetch.source_encoding,
fetch.title, fetch.keywords, fetch.author, fetch.publish_date,
fetch.crawltime.toFormat("YYYY-MM-DD HH24:MI:SS"), fetch.content
];
//执行sql,数据库中fetch表里的url属性是unique的,不会把重复的url内容写入数据库
mysql.query(fetchAddSql, fetchAddSql_Params, function(qerr, vals, fields) {
if (qerr) {
console.log(qerr);
}
}); //mysql写入
利用MySQLWorkbench可视化工具,查看数据爬取情况,最终共爬取到大约5000条数据。

此外我们还可以设置爬虫定时工作,保证一定的爬取数量。引入第三方包node-schedule设置定时。
//!定时执行
var rule = new schedule.RecurrenceRule();
var times = [0, 12]; //每天2次自动执行
var times2 = 5; //定义在第几分钟执行
rule.hour = times;
rule.minute = times2;
//定时执行httpGet()函数
schedule.scheduleJob(rule, function() {
seedget();
});
网站搭建
以上是爬虫的部分,下面我们将搭建网站来可视化爬取到的存储在mySQL数据库中的数据。利用Angular+express脚手架实现网站的前后端搭建。首先请求index.html文件,达到网站的导航页面,主要包括全文搜索,时间热度分析和词云图三个功能。点击不同的按钮,跳转到不同页面,实现不同功能。

在此,想主要讲解一下页面之间跳转的实现,也是本次项目中比较麻烦的一个点。实验利用ng-include并配合使用ng-hide,ng-show两个参数来控制页面的展示布局。以全文搜索的实现为例进行代码说明:
<div ng-show="isShow" ng-include="showType" style="width: 1300px;position:relative; top:70px;left: 80px"></div>
ng-show表示页面是否展示,ng-include表示展示的页面,若参数"isShow"为True则展示相参数"showType"对应的页面内容。
<div class="container">
<div class="navbar-header">
<a class="navbar-brand" href="#">导航栏</a>
</div>
<div id="navbar" class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li ><a ng-click="showSearch()">全文搜索</a></li>
$scope.search = function () {
//提取参数
var title = $scope.title;
var source = $scope.source;
var sorted = $scope.sorted;
var myurl = `/search?title=${title}&source=${source}&sorted=${sorted}`;
//请求路由
$http.get(myurl).then(
function (res) {
if(res.data.message=='data'){
$scope.isshowresult = true; //显示表格查询结果
$scope.initPageSort(res.data.result)
}else {
window.location.href=res.data.result;
}
},function (err) {
$scope.msg = err.data;
});
};
点击导航页面的全文搜索按钮,触发ng-click,跳转到showSearch()函数,修改isShow参数值为True和showType参数值为search.html,这样search页面就展示在前端。
以上就是整个框架实现页面控制的逻辑。下面将依次展示三个功能的实现与结果。
全文搜索
用户可以输入关键词、选择新闻来源和结果排序方式,根据输入的关键词做like搜索,根据新闻来源过滤掉不符合条件的内容,并按照一定的方式进行排序最后将查询结果返回到页面。
- 用户可以输入多个关键词,关键词之间用空格分隔
- 查询返回结果数目很多,实现了分页展示查询结果的功能
代码说明
<div class="row" style="margin-bottom: 5px;">
<label class="col-lg-2 control-label">标题关键词</label>
<div class="col-lg-3">
<input type="text" class="form-control" placeholder="输入查询的关键词【用空格分隔】" ng-model="$parent.title">
</div>
</div>
</div>
ng-model指令将输入的关键词绑定到当前的作用域的变量title中,以便$scope对象传递数据
<div class="row" style="margin-bottom: 5px;">
<label class="col-lg-2 control-label"></label>
<div class="col-lg-3">
<button type="submit" class="btn btn-default" ng-click="search()">查询</button>
</div>
</div>
点击查询按钮,ng-click被触发,调用search()函数。
$scope.search = function () {
//提取参数
var title = $scope.title;
var source = $scope.source;
var sorted = $scope.sorted;
var myurl = `/search?title=${title}&source=${source}&sorted=${sorted}`;
//请求路由
$http.get(myurl).then(
function (res) {
if(res.data.message=='data'){
$scope.isshowresult = true; //显示表格查询结果
$scope.initPageSort(res.data.result)
}else {
window.location.href=res.data.result;
}
},function (err) {
$scope.msg = err.data;
});
};
通过 $scope 对象获取关键词,并将参数放在url中,发送GET请求。
router.get('/search', function(request, response) {
var fetchSql="";
if(request.query.source != "所有网站"){
//sql字符串和参数
var fetchSql = "select title,source_name,publish_date,url " +
"from fetches where source_name like '%" + request.query.source+"%'";
// console.log(fetchSql);
var keywords = request.query.title.split(" ");
for(var i=0;i<keywords.length;i++){
fetchSql+="and title like '%"+ keywords[i] + "%'";
}
}else{
var keywords = request.query.title.split(" ");
var fetchSql = "select title,source_name,publish_date,url from fetches"
// console.log(fetchSql);
for(var i=0;i<keywords.length;i++){
if(i == 0){
fetchSql+=" where title like '%"+ keywords[i] + "%'";
}else{
fetchSql+="and title like '%"+ keywords[i] + "%'";
}
}
}
console.log(request.query.sorted);
if(request.query.sorted == '默认'){
fetchSql += ";";
} else if(request.query.sorted == '顺序'){
fetchSql += " order by publish_date;";
}
else{
fetchSql +=" order by publish_date desc;";
}
console.log(fetchSql);
mysql.query(fetchSql, function(err, result, fields) {
var res = result;
regExp = /(\d{4})-(\d{2})-(\d{2})/
for (var i = 0;i<res.length;i++){
tmp = (res[i]);
res[i].publish_date = regExp.exec(JSON.stringify(res[i].publish_date))[0];
}
response.json({message:'data',result:result});
});
});
根据路由调用相应的函数,处理请求,并将结果返回。
页面展示
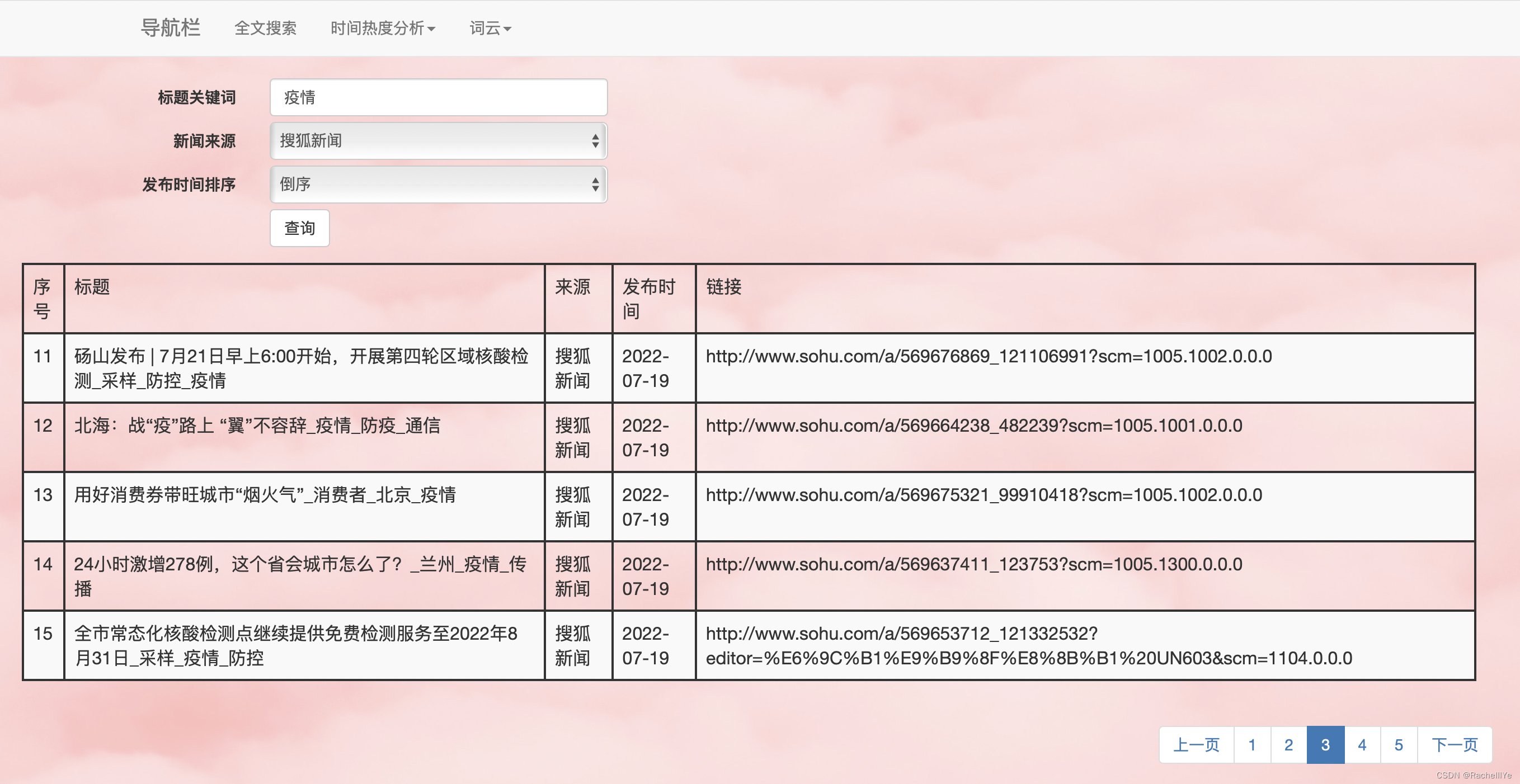
单关键词“疫情”全文搜索结果,分页展示。
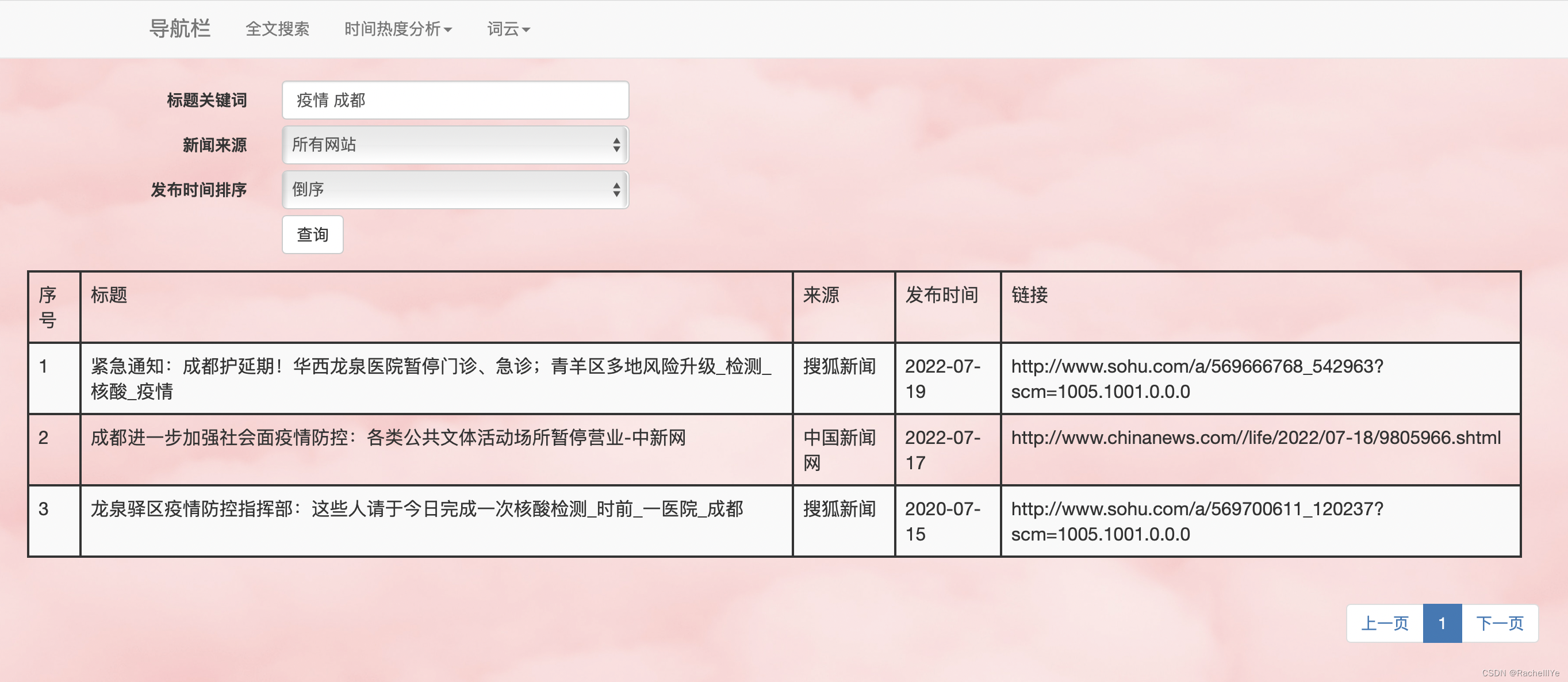
多关键词“疫情”“成都”全文搜索结果。
用户输入关键词,统计十天内包含该关键词的新闻数目,以直方图和折线图两种形式进行可视化展示。(以折线图为例进行代码说明,直方图与此类似)
时间热度分析
- 随着时间的变化,同一关键词的热度也在发生变化,相应的直方图和折线图呈现的结果也会根据当前数据库存储的数据而动态变化。
代码说明
ng-model指令将输入的关键词绑定到当前的作用域中;点击确认按钮,调用line()函数。
<form class="form-horizontal" role="form">
<div class="row" style="margin-bottom: 5px;">
<label class="col-lg-2 control-label">内容关键词</label>
<div class="col-lg-3">
<input type="text" class="form-control" placeholder="输入查询的关键词【用空格分隔】" ng-model="$parent.keyword">
</div>
</div>
<div class="row" style="margin-bottom: 5px;">
<label class="col-lg-2 control-label"></label>
<div class="col-lg-3">
<button type="submit" class="btn btn-default" ng-click="line()">确认</button>
</div>
</div>
</form>
$scope对象获取参数值,并利用参数构建url发送GET请求;根据路由指定的函数做相应的处理,提取参数值并构建sql语句进行查询,并将查询结果处理好后返回,最后根据数据库查询的结果作图。
router.get('/line',function(request,response){
var keyword = request.query.keyword;
console.log(keyword);
var fetchSql = "select publish_date,count(*) as num from fetches where content like '%"+keyword+"%' and publish_date>'2022-7-10' group by publish_date order by publish_date;";
console.log(fetchSql);
mysql.query(fetchSql,function(err, result,fields){
var time = [];
var num = [];
// console.log(result);
regExp = /(\d{4})-(\d{2})-(\d{2})/
//处理查询的结果,以便符合作图时的数据格式
for (var i = 0;i<result.length;i++){
time.push(regExp.exec(JSON.stringify(result[i].publish_date))[0]);
num.push(result[i].num);
}
response.json({message:'data',time:time,num:num});
});
});
//时间热度分析
$scope.line = function () {
var keyword = $scope.keyword;
// $scope.isshowresult = true;
$scope.isShow = false;
var myurl = `/line?keyword=${keyword}`;
$http.get(myurl).then(
function (res) {
console.log("line chart");
var myChart = echarts.init(document.getElementById("main1"));
option = {
title: {
text: "十天内新闻关键词:"+keyword+"时间热度分析图"
},
xAxis: {
type: 'category',
data:res.data.time,
show: true,
},
yAxis: {
type: 'value'
},
series: [{
data:res.data.num,
type: 'line',
itemStyle: {normal: {label: {show: true}}}
}],
};
if (option && typeof option === "object") {
myChart.setOption(option, true);
}
});
};
前端页面展示
输入关键词,以疫情为例



词云
词云图过滤掉多数文本信息,较好地展示出新闻的热点。实验提取出爬取到的所有新闻的keywords,再进行分词,统计每个词语出现的频率,作为绘制词云图的数据集。
代码说明
选择词云调用wordclound()函数。
<li ><a ng-click="wordcloud()">词云</a></li>
前端页面为Echarts准备一个具备一定长宽大小的Dom,并定义id为main1
<!-- 所有的图片都绘制在main1位置-->
<span ng-hide="isShow" id="main1" style="width: 1000px;height:600px;position:fixed; top:70px;left:80px"></span>
基于准备好的Dom(main1)初始化echarts实例,并请求相应的url
$scope.wordcloud = function () {
$scope.isShow = false;
$http.get("/wordcloud").then(
function (res) {
var mainContainer = document.getElementById('main1');
var chart = echarts.init(mainContainer);
var maskImage = new Image();
maskImage.src = './images/logo.png';
var option = {
title: {
text: '新闻关键词的词云展示'
},
series: [{
type: 'wordCloud',
sizeRange: [12, 60],
rotationRange: [-90, 90],
rotationStep: 45,
gridSize: 2,
shape: 'circle',
maskImage: maskImage,
drawOutOfBound: false,
textStyle: {
normal: {
fontFamily: 'sans-serif',
fontWeight: 'bold',
// Color can be a callback function or a color string
color: function () {
// Random color
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: res.data.result
}]
};
maskImage.onload = function () {
// option.series[0].data = data;
chart.clear();
chart.setOption(option);
};
window.onresize = function () {
chart.resize();
};
});
}
跳转到路由指定的函数,统计所有新闻keywords的词频,并将结果返回,词云图将基于处理好的返回结果进行绘图。
router.get('/wordcloud',function(request,response){
//正则表达式去掉一些无用的字符,与高频但无意义的词。
const regex = /[\t\s\r\n\d\w]|[\+\-\(\),\.。,!?《》@、【】::%-\/“”]/g;
var fetchSql = "select keywords from fetches;";
mysql.query(fetchSql,function(err, result,fields){
response.writeHead(200, {
"Content-Type": "application/json"
});
var word_freq = {};
result.forEach(function (content){
var newcontent = content["keywords"].replace(regex,",");
if(newcontent.length !== 0){
// console.log();
// var words = nodejieba.cut(newcontent);
var words = newcontent.split(",");
words.forEach(function (word){
word = word.toString();
if(word.indexOf("/undefined/")==-1){
word_freq[word] = (word_freq[word] +1 ) || 1;
}
});
};
});
var final = [];
for(var key in word_freq){
if(key!=""){
var tmp = {};
tmp["name"] = key;
tmp["value"] = word_freq[key]
final.push(tmp)
}
}
console.log(final);
response.write(JSON.stringify({message:'data',result:final}));
response.end();
});
});
前端页面展示

实验总结
通过本次实验学习了如何利用爬虫爬取新闻网站并且与数据库相连接将爬取到的数据存储在数据库中,对爬虫有了初步的学习与了解。除此之外,还利用Angular和express脚手架搭建了自己的网站实现了一些简单的功能,如:分词查询,时间热度分析和词云等等。在实验过程中遇到了很多的bug,不断地学习和查资料debug代码,最终也呈现出了一个完整的项目。继续加油!
注:博客中只放出了每个部分的核心代码,完整代码可以移步GitHub进行查看。

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









