







 本文深入解析了Java并发包中的核心组件AQS(AbstractQueuedSynchronizer)的工作原理及其实现机制,包括独占和共享模式下的资源获取与释放流程。
本文深入解析了Java并发包中的核心组件AQS(AbstractQueuedSynchronizer)的工作原理及其实现机制,包括独占和共享模式下的资源获取与释放流程。
Java并发包(JUC)中有几个重要并发类如CounDownLatch、Semaphore、CyclicBarrier以及我们重要的可重入锁ReentrantLock等。它们的底层实现就是基于AQS实现的。看过源码之后,会惊叹设计者的设计之妙!说到AQS,在Java并发中,还有一种CAS算法,它是Java并发包下原子类的实现的底层算法,这个笔者会另起篇幅来做学习总结。
什么是AQS
AbstractQueuedSynchronizer,简称AQS。抽象的队列式的同步器,AQS提供了一种实现阻塞锁和一系列依赖FIFO等待队列的同步器的框架。它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)
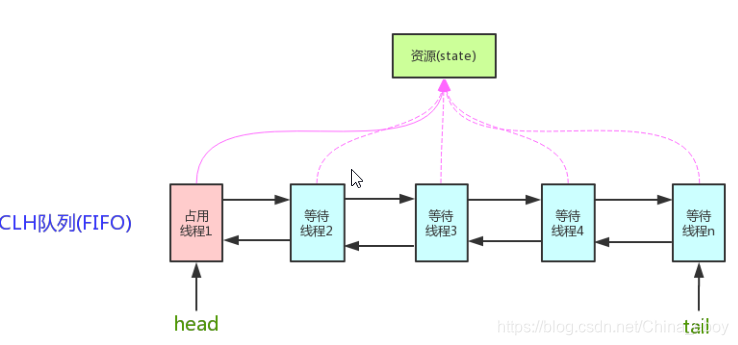
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
AQS实现
根据独占(acquire-release)以及共享(acquireShared-releaseShared)分为两大模块
独占:
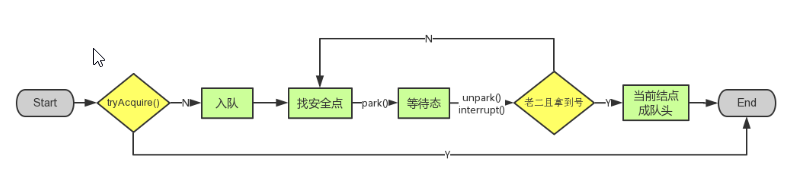
acquire(int):此方法是独占模式下线程获取共享资源的顶层入口。如果获取到资源,线程直接返回,否则进入等待队列,直到获取到资源为止,且整个过程忽略中断的影响。这也正是lock()的语义,当然不仅仅只限于lock()。
public final void acquire(int arg) {
//tryAcquire()尝试直接去获取资源,如果成功则直接返回;
if (!tryAcquire(arg) &&
//将线程封装成一个Node节点,加入等待队列的尾部,并标记为独占模式;
//acquireQueued()使线程在等待队列中获取资源,一直获取到资源后才返回。如果在整个等待过程中
//被中断过,则返回true,否则返回false。
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
//如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断
//selfInterrupt(),将中断补上。
selfInterrupt();
}该方法内部实现流程总结:
- 调用自定义同步器的tryAcquire()尝试直接去获取资源,如果成功则直接返回;
- 没成功,则addWaiter()将该线程加入等待队列的尾部,并标记为独占模式;
- acquireQueued()使线程在等待队列中休息,有机会时(轮到自己,会被unpark())会去尝试获取资源。获取到资源后才返回。如果在整个等待过程中被中断过,则返回true,否则返回false。
- 如果线程在等待过程中被中断过,它是不响应的。只是获取资源后才再进行自我中断selfInterrupt(),将中断补上。
release(int) :此方法是独占模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果彻底释放了(即state=0),它会唤醒等待队列里的其他线程来获取资源。这也正是unlock()的语义,当然不仅仅只限于unlock()。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;//找到头结点
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);//唤醒等待队列里的下一个线程
return true;
}
return false;
}逻辑并不复杂。它调用tryRelease()来释放资源。有一点需要注意的是,它是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自定义同步器在设计tryRelease()的时候要明确这一点!!跟tryAcquire()一样,这个方法是需要独占模式的自定义同步器去实现的。正常来说,tryRelease()都会成功的,因为这是独占模式,该线程来释放资源,那么它肯定已经拿到独占资源了,直接减掉相应量的资源即可(state-=arg),也不需要考虑线程安全的问题。但要注意它的返回值,上面已经提到了,release()是根据tryRelease()的返回值来判断该线程是否已经完成释放掉资源了!所以自义定同步器在实现时,如果已经彻底释放资源(state=0),要返回true,否则返回false。
共享:
acquireShared(int):此方法是共享模式下线程获取共享资源的顶层入口。它会获取指定量的资源,获取成功则直接返回,获取失败则进入等待队列,直到获取到资源为止,整个过程忽略中断。

这里tryAcquireShared()依然需要自定义同步器去实现。但是AQS已经把其返回值的语义定义好了:负值代表获取失败;0代表获取成功,但没有剩余资源;正数表示获取成功,还有剩余资源,其他线程还可以去获取。所以这里acquireShared()的流程就是:
- tryAcquireShared()尝试获取资源,成功则直接返回;
- 失败则通过doAcquireShared()进入等待队列park(),直到被unpark()/interrupt()并成功获取到资源才返回。整个等待过程也是忽略中断的。
其实跟acquire()的流程大同小异,只不过多了个自己拿到资源后,还会去唤醒后继队友的操作(这才是共享嘛)
跟独占模式比,还有一点需要注意的是,这里只有线程是head.next时(“老二”),才会去尝试获取资源,有剩余的话还会唤醒之后的队友。那么问题就来了,假如老大用完后释放了5个资源,而老二需要6个,老三需要1个,老四需要2个。老大先唤醒老二,老二一看资源不够,他是把资源让给老三呢,还是不让?答案是否定的!老二会继续park()等待其他线程释放资源,也更不会去唤醒老三和老四了。独占模式,同一时刻只有一个线程去执行,这样做未尝不可;但共享模式下,多个线程是可以同时执行的,现在因为老二的资源需求量大,而把后面量小的老三和老四也都卡住了。当然,这并不是问题,只是AQS保证严格按照入队顺序唤醒罢了(保证公平,但降低了并发)。
releaseShared:此方法是共享模式下线程释放共享资源的顶层入口。它会释放指定量的资源,如果成功释放且允许唤醒等待线程,它会唤醒等待队列里的其他线程来获取资源。
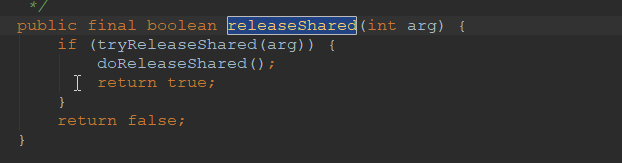
此方法的流程也比较简单,一句话:释放掉资源后,唤醒后继。跟独占模式下的release()相似,但有一点稍微需要注意:独占模式下的tryRelease()在完全释放掉资源(state=0)后,才会返回true去唤醒其他线程,这主要是基于独占下可重入的考量;而共享模式下的releaseShared()则没有这种要求,共享模式实质就是控制一定量的线程并发执行,那么拥有资源的线程在释放掉部分资源时就可以唤醒后继等待结点。例如,资源总量是13,A(5)和B(7)分别获取到资源并发运行,C(4)来时只剩1个资源就需要等待。A在运行过程中释放掉2个资源量,然后tryReleaseShared(2)返回true唤醒C,C一看只有3个仍不够继续等待;随后B又释放2个,tryReleaseShared(2)返回true唤醒C,C一看有5个够自己用了,然后C就可以跟A和B一起运行。而ReentrantReadWriteLock读锁的tryReleaseShared()只有在完全释放掉资源(state=0)才返回true,所以自定义同步器可以根据需要决定tryReleaseShared()的返回值。


















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











