




详细的STL接口及介绍可以参考官方文档:https://cplusplus.com/reference/,本文重点介绍不同容器的底层原理以及使用注意事项。
需要特别说明的是,所有是STL容器或适配器,都不是线程安全的,因此在多线程环境保证外部同步。
各容器clear()行为总结:
| 容器类型 | clear() 是否释放内存 | 说明 |
|---|---|---|
vector | ❌ 不释放 | 只销毁元素,容量保持不变 |
deque | ⚠️ 部分释放 | 释放数据块,中控器可能保留 |
list / forward_list | ✅ 完全释放 | 释放所有节点内存 |
set / map 等树容器 | ✅ 完全释放 | 释放所有树节点内存 |
unordered_set 等哈希容器 | ⚠️ 部分释放 | 释放元素,桶数组通常保留 |
1. std::vector
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 随机访问 | O(1) | 常量时间 |
| 在末尾插入/删除 | O(1) 均摊 | 可能触发扩容 |
| 在开头或中间插入/删除 | O(n) | 需要移动元素 |
| 查找 | O(n) | 线性搜索 |
| 排序 | O(n log n) | 使用std::sort |
| 扩容 | O(n) | 拷贝所有元素 |
vector是一种序列容器,其内存管理是一个一块连续分配的内存,支持随机访问,支持以移动拷贝的方式进行动态扩展(一般以2倍大小进行扩展),std::vector 的典型实现包含三个关键指针:
/*
_M_start _M_finish _M_end_of_storage
↓ ↓ ↓
[0 | 1 | 2 | 3 | ? | ? | ? | ? ]
│ │ │
│ │ └── 分配的内存边界
│ └────────────── 已构造的元素边界
└───────────────────────────── 内存块起始位置
size() = 4 (已使用元素数量)
capacity() = 8 (总容量)
*/
template<typename T, typename Allocator = std::allocator<T>>
class vector {
private:
T* _M_start; // 指向已使用内存的起始位置
T* _M_finish; // 指向已使用内存的结束位置(最后一个元素的下一个)
T* _M_end_of_storage; // 指向整个分配内存的结束位置
// 内存分配器
Allocator _M_alloc;
public:
// 关键成员函数
size_type size() const noexcept { return _M_finish - _M_start; }
size_type capacity() const noexcept { return _M_end_of_storage - _M_start; }
bool empty() const noexcept { return _M_start == _M_finish; }
};在使用std::vector时,有以下几点需要特别注意下:
- 因为std::vector是动态扩容的,因此在多线程使用时,需要特别注意迭代器失效问题。
- 在调用std::vector的成员函数clear()时,其内存并没有立即释放,若需要其立即释放,建议通过以下方式实现:
std::vector<int> vec(1000000);
// 方法1: clear() + shrink_to_fit() (C++11)
vec.clear();
vec.shrink_to_fit(); // 请求释放未使用内存(仅仅是请求)
// 方法2: swap技巧 (C++98/03)
std::vector<int>().swap(vec); // 保证释放所有内存
// 方法3: 赋值空vector
vec = std::vector<int>(); // 移动赋值或拷贝赋值,释放旧内存
// 方法4: resize(0) + shrink_to_fit()
vec.resize(0);
vec.shrink_to_fit();// 仅仅是请求
// 性能测试:方法2通常最可靠,但C++11后方法1更直观- 坚决避免使用std::vector< bool>类型,因为其底层不是直接存储了1字节的bool,而是存储了bit位,如下所示:
std::vector<int> int_vec{1, 0, 1}; // 真正的数组:每个int占4字节
std::vector<bool> bool_vec{true, false, true}; // 位压缩:3个bit只占1字节
/*
vector<int>: [0x00000001 | 0x00000000 | 0x00000001] // 12字节
vector<bool>: [0b00000101] // 1字节(位压缩)
*/这通常导致使用方式不当会产生奇奇怪怪的问题,例如:
std::vector<bool> flags{true, false, true};
// 看起来element 是bool,实际上是std::vector<bool>::reference
auto element = flags[0];2. std::list
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 在任意位置插入/删除 | O(1) | 已知位置时 |
| 随机访问 | O(n) | 需要遍历 |
| 查找 | O(n) | 线性搜索 |
| 排序 | O(n log n) | 成员函数sort |
std::list是由环形双向链表实现的,每个节点存储一个元素,内存分配是不连续的,内存布局示意图如下
实际的链表结构:
_M_node (哨兵) ↔ 节点1 ↔ 节点2 ↔ 节点3 ↔ 回到_M_node
内存示意图:
_M_node: [prev→节点3 | next→节点1]
节点1: [prev→_M_node | data1 | next→节点2]
节点2: [prev→节点1 | data2 | next→节点3]
节点3: [prev→节点2 | data3 | next→_M_node]在使用std::list时,有两点需要额外注意的:
- list的迭代器在插入和删除操作后仍然保持有效(除了被删除元素的迭代器),这是它的一个重要优势。但需要注意的是,虽然迭代器本身有效,但指向的内容可能已经改变。
- 在遍历list时删除元素需要特别小心。错误的做法是在删除后继续使用原来的迭代器。正确的做法是使用 erase 函数的返回值来更新迭代器,因为 erase 返回指向下一个元素的迭代器。
void correct_traversal_erase_return() {
std::list<int> lst = {1, 2, 3, 4, 2, 5, 2};
for (auto it = lst.begin(); it != lst.end(); ) {
if (*it == 2) {
it = lst.erase(it); //erase返回指向下一个元素的迭代器,更新it,不需要手动++it
} else {
++it; // 只有没有删除时才前进
}
}
// 现在lst包含: 1, 3, 4, 5
}3. std::forward_list
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 在头部插入/删除 | O(1) | push_front(), pop_front() |
| 在已知位置后插入/删除 | O(1) | insert_after(), erase_after() |
| 随机访问 | O(n) | 需要从头遍历 |
| 查找 | O(n) | 线性搜索 |
| 获取大小 | O(n) | std::distance(begin(), end()) |
| 排序 | O(n log n) | 成员函数 sort() |
| 合并 | O(n) | 成员函数 merge() |
| 反转 | O(n) | 成员函数 reverse() |
forward_list是一个序列容器,它的底层实现为单向链表。下面汇总了其核心特性和与 std::list 的主要区别,帮你快速把握要点:
| 特性维度 | std::forward_list (单向链表) | std::list (双向链表) |
|---|---|---|
| 内存布局 | 每个节点含数据和一个后继指针 next | 每个节点含数据、一个前驱指针和一个后继指针 |
| 迭代器类型 | 前向迭代器,仅支持 ++ 操作 | 双向迭代器,支持 ++ 和 -- 操作 |
| 随机访问 | 不支持,访问元素需线性时间遍历 | 不支持,访问元素需线性时间遍历 |
| 头部操作 | push_front(), pop_front() 等,O(1) | push_front(), pop_front() 等,O(1) |
| 尾部操作 | 不直接提供,因需从头遍历,代价高 | push_back(), pop_back() 等,O(1) |
| 中间插入/删除 | insert_after(), erase_after(),O(1) | insert(), erase(),O(1) |
size() 成员函数 | 无,计算大小需 std::distance(begin, end),O(n) | 有,通常 O(1) |
| 内存开销(64位) | 每个节点约 sizeof(T) + 8 字节 | 每个节点约 sizeof(T) + 16 字节 |
| 迭代器失效 | 插入操作通常不使其他迭代器失效;被删除元素的迭代器会失效-1 | 插入操作不使其他迭代器失效;被删除元素的迭代器会失效 |
4. std::deque
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 在头部插入/删除 | O(1) | push_front(), pop_front() |
| 在尾部插入/删除 | O(1) | push_back(), pop_back() |
| 随机访问 | O(1) | operator[], at() |
| 在中间插入/删除 | O(n) | insert(), erase() |
| 查找 | O(n) | 线性搜索 |
| 排序 | O(n log n) | std::sort() |
std::deque(双端队列):是一种双开口的“连续”空间的数据空间,双开口的含义是:可以在头尾俩段进行插入和删除操作,且时间复杂度为O(1)。与vector相比,头插效率高,不需要搬移元素;与list相比,空间利用率高。
和 vector 容器采用连续的线性空间不同,deque 容器存储数据的空间是由一段一段等长的连续空间构成,各段空间之间并不一定是连续的,可以位于在内存的不同区域。为了管理这些连续空间,deque 容器用数组(数组名假设为 map)存储着各个连续空间的首地址。也就是说,map数组中存储的都是指针,指向那些真正用来存储数据的各个连续空间,这也就意味着对std::deque的索引访问必须执行两次指针引用(vector仅需要执行一次):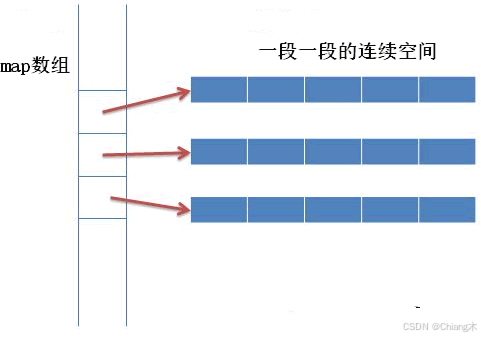
动态扩容策略,当在两端插入元素时:
-
前端插入:如果第一个数据块还有空间,直接使用;否则分配新数据块并更新中控器
-
后端插入:如果最后一个数据块还有空间,直接使用;否则分配新数据块
-
中控器扩容:当数据块数量超过中控器容量时,重新分配更大的中控器
在使用std::deque时,有以下几点需要特别注意下(同std::vector):
- 因为std::deque是动态扩容的,因此在多线程使用时,需要特别注意迭代器失效问题。
- 在调用std::deque的成员函数clear()时,其内存并没有立即释放,若需要其立即释放,建议通过以下方式实现:
std::deque<int> deq(1000000);
// 方法1: clear() + shrink_to_fit() (C++11)
deq.clear();
deq.shrink_to_fit(); // 请求释放未使用内存(仅仅是请求)
// 方法2: swap技巧 (C++98/03)
std::deque<int>().swap(deq); // 保证释放所有内存
// 方法3: 赋值空vector
deq= std::deque<int>(); // 移动赋值或拷贝赋值,释放旧内存
// 方法4: resize(0) + shrink_to_fit()
deq.resize(0);
deq.shrink_to_fit();// 仅仅是请求
// 性能测试:方法2通常最可靠,但C++11后方法1更直观5. std::array
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 随机访问 | O(1) | operator[], at(), front(), back() |
| 遍历访问 | O(n) | 需要访问n个元素 |
| 查找 | O(n) | 线性搜索 |
| 排序 | O(n log n) | std::sort() |
| 大小查询 | O(1) | size(), empty() |
| 填充 | O(n) | fill() |
std::array本质是C数组包装:零开销抽象,性能与C数组完全相同,其空间是在编译期确定大小,内存是完全连续的内存,不支持动态分配。
零大小的std::array是合法的,但它们不应该被引用以访问它的内容。
6. std::queue
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
入队 (push()) | O(1) | 在尾部添加元素 |
出队 (pop()) | O(1) | 移除头部元素 |
访问队首 (front()) | O(1) | 查看头部元素 |
访问队尾 (back()) | O(1) | 查看尾部元素 |
大小查询 (size(), empty()) | O(1) | 元素数量查询 |
| 查找元素 | 不支持 | 队列不支持查找 |
std::queue被实现为容器适配器,是一种 FIFO(先进先出)数据结构,无迭代器,对空队列操作 front()/pop() 会导致未定义行为,默认使用 std::deque 作为底层容器,但也可以指定其他容器,例如:
// 默认使用 deque,所有操作: O(1)
std::queue<int> q1;
// 显式指定 deque
std::queue<int, std::deque<int>> q2;
// 显式指定 list,所有操作仍然是 O(1),但内存开销更大
std::queue<int, std::list<int>> q;
// 显式指定 vector,出队操作变成 O(n), 不推荐!
std::queue<int, std::vector<int>> q;7. std::priority_queue
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
插入元素 (push()) | O(log n) | 堆插入操作 |
删除堆顶 (pop()) | O(log n) | 堆删除操作 |
访问堆顶 (top()) | O(1) | 直接访问根部 |
大小查询 (size(), empty()) | O(1) | 元素数量查询 |
std::priority_queue 的排序通常是基于完全二叉树来实现的,默认使用vector作为其底层容器,当然也可以选择deque, 不支持随机访问或迭代器。
// 默认使用vector,缓存友好
std::priority_queue<int> pq;
// deque也可以工作
std::priority_queue<int, std::deque<int>> pq;
// 错误!list不支持随机访问,堆算法无法工作
std::priority_queue<int, std::list<int>> bad_pq;8. std::stack
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
入栈 (push()) | O(1) | 在栈顶添加元素 |
出栈 (pop()) | O(1) | 移除栈顶元素 |
访问栈顶 (top()) | O(1) | 查看栈顶元素 |
大小查询 (size(), empty()) | O(1) | 元素数量查询 |
stack是一种容器适配器,专门设计用于执行 LIFO(后进先出)操作的适配器,其元素仅从适配器的一端进行插入和提取,默认使用std::deque 作为底层容器,但也可以指定其他容器,但性能差异较大:
| 操作 | std::deque(默认) | std::vector | std::list |
|---|---|---|---|
push() | O(1) | O(1) 均摊 | O(1) |
pop() | O(1) | O(1) | O(1) |
top() | O(1) | O(1) | O(1) |
size() | O(1) | O(1) | O(1) |
| 内存开销 | 中等 | 低 | 高 |
| 缓存性能 | 良好 | 最佳 | 差 |
在空栈上调用top()或pop()是未定义行为,没有迭代器。
9. std::multiset/set/multimap/map
时间复杂度分析:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
插入元素 (insert()) | O(log n) | 红黑树插入 |
删除元素 (erase()) | O(log n) | 红黑树删除 |
查找元素 (find()) | O(log n) | 二叉搜索树查找 |
计数元素 (count()) | O(log n + k) | k为元素出现次数 |
范围查询 (lower/upper_bound()) | O(log n) | 边界查找 |
最小值/最大值 (begin(), rbegin()) | O(1) | 最左/最右节点 |
访问元素 (operator[]) | O(log n) | map特有,查找或插入 |
| 遍历所有元素 | O(n) | 中序遍历 |
std::multiset/std::set/std::multimap/std::map通常基于红黑树(Red-Black Tree)实现,这是一种自平衡的二叉搜索树。
std::map的operator[]函数会在键值不存在时,自动插入新元素:
std::map<int, std::string> m;
// 键值5不存在,则自动插入键值为5,value为空字符串的元素
std::string value = m[5];
// 若键值已存在,则会被强制覆盖替换
m[5] == "something";
// 编译错误!multimap 没有 operator[]
std::multimap<int, std::string> mm;
auto value = mm[5]; 关于迭代器何时失效方面(只有被删除元素的迭代器会失效):
-
插入新元素不会使现有迭代器失效
-
删除其他元素不会影响指向未被删除元素的迭代器
-
删除元素会使指向该元素的迭代器失效
-
清除整个容器会使所有迭代器失效
10. std::unordered_set/unordered_multiset/unordered_map/unordered_multimap
时间复杂度分析:
| 操作 | 平均情况 | 最坏情况 | 说明 |
|---|---|---|---|
插入元素 (insert(), emplace()) | O(1) | O(n) | 哈希表插入 |
删除元素 (erase()) | O(1) | O(n) | 哈希表删除 |
查找元素 (find()) | O(1) | O(n) | 键查找 |
访问元素 (operator[], at()) | O(1) | O(n) | unordered_map/unordered_multimap特有 |
计数元素 (count()) | O(1) | O(n) | 键的出现次数 |
| 遍历所有元素 | O(n) | O(n) | 遍历所有桶 |
| 桶操作和哈希策略 | O(1) | O(1) | 元数据访问 |
std::unordered_set 和 std::unordered_multiset以及unordered_map、unordered_multimap都是基于开链法(Separate Chaining)的哈希表实现。
std::unordered_map的operator[]函数会在键值不存在时,自动插入新元素:
std::unordered_map<int, std::string> m;
// 键值5不存在,则自动插入键值为5,value为空字符串的元素
std::string value = m[5];
// 若键值已存在,则会被强制覆盖替换
m[5] == "something";
// 编译错误!multimap 没有 operator[]
std::unordered_multimap<int, std::string> mm;
auto value = mm[5]; 关于迭代器何时失效方面(只有被删除元素的迭代器会失效):
-
插入新元素不会使现有迭代器失效
-
删除其他元素不会影响指向未被删除元素的迭代器
-
删除元素会使指向该元素的迭代器失效
-
清除整个容器会使所有迭代器失效
- 重新哈希会使所有迭代器失效
哈希函数将键映射到桶索引,其质量直接影响哈希碰撞的概率,这将导致不同健映射到同一个桶中,这引发一系列性能问题:
-
链表长度增加:在开链法实现中,同一个桶内的元素形成链表。碰撞越多,链表越长。
-
查找性能退化:在链表中查找元素的时间复杂度是 O(k),其中 k 是链表长度。最坏情况下,所有元素都碰撞到同一个桶,查找性能从 O(1) 退化为 O(n)。
-
缓存不友好:链表节点在内存中不连续,导致大量的缓存未命中。现代CPU中,缓存未命中的代价比指令执行代价高几个数量级。
负载因子 = 元素数量 / 桶数量,负载因子与性能的关系:
-
低负载因子(如 0.1-0.5):链表短,查找速度快,性能稳定,很少触发重哈希
- 适中负载因子(如 0.7-1.0):查找性能仍然很好,重哈希频率适中
- 高负载因子(如 >1.5):内存利用率最高,链表长,查找性能显著下降,性能不稳定,频繁触发重哈希


















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











