




 本文详细介绍了如何搭建Hadoop分布式集群,包括环境准备、Hadoop版本选择、下载、编译,以及配置文件的设置,如hadoop-env.sh、core-site.xml等。此外,还涵盖了集群启动关闭流程,Hadoop UI的查看,日志记录和垃圾桶机制的开启与管理。
本文详细介绍了如何搭建Hadoop分布式集群,包括环境准备、Hadoop版本选择、下载、编译,以及配置文件的设置,如hadoop-env.sh、core-site.xml等。此外,还涵盖了集群启动关闭流程,Hadoop UI的查看,日志记录和垃圾桶机制的开启与管理。
1. 集群简介
Hadoop包括两个集群,hdfs集群和yarn集群
hdfs集群负责数据存储,主要角色有:NameNode,DataNode,SecondaryNameNode
yarn集群负责调度管理,主要角色有ResourceManager, NodeManager
两者逻辑上没有必要关联一定要放在一起,但一般放在一起。
2. 环境准备
centOS/VMWare开启三台虚拟机
bigdata01.virtualgroup.com
bigdata02.virtualgroup.com
bigdata03.virtualgroup.com
集群时间同步
防火墙关闭
主机名host映射
免密登陆
JDK1.8
分布模式
bigdata01.virtualgroup.com简称01,其余同理
01: NameNode; DataNode; ResourceManager; NodeManager;
02: SecondaryNameNode; DataNode; NodeManager;
03: DataNode; NodeManager;
文件夹设定
mkdir /export/servers #安装文件(JDK,Hadoop等)
mkdir /export/datas #存储数据
3. Hadoop版本及下载
3.1 Hadoop版本
社区版: Apache提供的官方版本
优点:版本功能新且全
缺点:不稳定
商业版:商业公司版本(以CDH cloudera为例)
优点:兼容性好
缺点:不是最新版,要钱
4.2 hadoop下载
采用cdh5.14.0–Hadoop2.6.0
http://archive.cloudera.com/cdh5/
4.3 hadoop编译
a. JDK1.7
b. cloudera公司jar包不在maven中央仓库,需要下载配置到编译的机器上
c. 网络畅通
(未展开论述)
4. Hadoop配置文件
4.1 hadoop-env.sh
配置环境变量 (jdk的安装路径)
export JAVA_HOME=/export/servers/jdk1.8.0_65
4.2 (core/hdfs/yarn/mapred)-site.xml
均有对应的xxx-default.xml文件,两者作用相同
先匹配xxx-site.xml,如没有再在xxx-default.xml文件中寻找属性设置
4.2.1 core-site.xml
核心配置文件
<!-- 用于设置Hadoop的文件系统,由URI指定,名称改为对应机器名 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01.virtualgroup.com:9000</value>
</property>
<!-- 配置Hadoop存储数据目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<!--/export/data为存储地址-->
<value>/export/data/hadoopdata</value>
</property>
4.2.2 hdfs-site.xml
hdfs核心配置文件
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- secondary namenode 所在主机的ip和端口,放在第二台机上-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02.virtualgroup.com:50090</value>
</property>
4.2.3 mapred-site.xml
MapReduce的核心配置文件
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.2.4 yarn-site.xml
yarn的核心配置文件
<!-- 指定YARN的主角色(ResourceManager)的地址,放第一台机上 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01.virtualgroup.com</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.2.5 slaves
集群节点主机名
(应该是部署DataNode和NodeManager的机器需要填入。
实测因为主机01除了部署NameNode和ResourceManager外,同时部署了DataNode和NodeManager,如果不写入这台机器名,则一键脚本启动无法开启DataNode和NodeManager)
bigdata01.virtualgroup.com
bigdata02.virtualgroup.com
bigdata03.virtualgroup.com
4.2.6 default配置
参阅官网如下
hadoop官网
“release archive”下找到对应版本,点击“documentation”
在新页面左下角,configuration,有对应各配置文件default设置链接
4.2.6 Hadoop环境变量
修改环境变量配置文件
vim /etc/profile
<!--hadoop安装目录,且同时配置bin和sbin两个目录 -->
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并刷新配置文件
source /etc/profile
至此Hadoop基本配置完成
5. Hadoop启动与关闭
5.1 格式化
配置完成,首次启动需要格式化
hadoop namenode -format
若不小心多次格式化,把三台机器上 hadoop.tmp.dir 指定的文件夹删除 重新format一次 此时就是一个新的集群
5.2 单节点启动关闭
开启/关闭 NameNode/DataNode/ResourceManager/NodeManager
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start resourcemanager
hadoop-daemon.sh start nodemanager
5.3 脚本一键启动
start-dfs.sh #开启hdfs
stop-dfs.sh #停止hdfs
start-yarn.sh #开启yarn
stop-yarn.sh #停止yarn
start-all.sh #开启全部
stop-all.sh #停止全部
6. 查看Hadoop UI
NameNode:http://nn_host:port/默认50070
e.g. http://bigdata01.virtualgroup.com:50070/
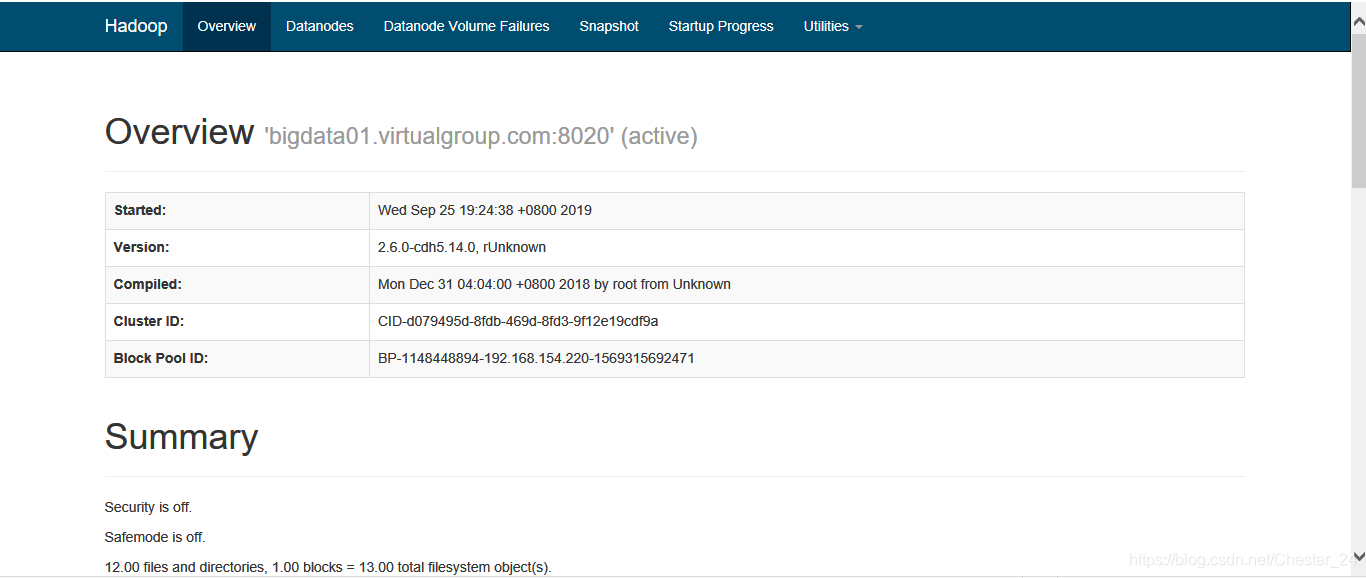
ResourceManager:http://rm_host:port/默认8088
e.g. http://bigdata01.virtualgroup.com:8088/

7. 开启日志记录及垃圾桶回收
7.1 日志记录
JobHistory默认未开启,需手动开启,可记录Hadoop操作记录
7.1.1 修改mapred-site.xml
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim mapred-site.xml
<!--MR JobHistory Server管理的日志的存放位置-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata01.virtualgroup.com:10020</value>
</property>
<!--查看历史服务器已经运行完的Mapreduce作业记录的web地址,需要启动该服务才行-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata01.virtualgroup.com:19888</value>
</property>
7.1.2 分发配置到其他机器
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
#发给bigdata02.virtualgroup.com机台
scp mapred-site.xml bigdata02.virtualgroup.com:/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
#发给bigdata03.virtualgroup.com机台
scp mapred-site.xml bigdata03.virtualgroup.com:/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
7.1.3 开启/关闭服务
该服务默认不开启,需手动开启关闭
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver
7.1.4 访问historyserver
http://bigdata01.virtualgroup.com:19888/jobhistory
7.2 垃圾桶机制
垃圾桶保存时间,默认时间为0(分钟),即没有误删恢复机制
修改默认属性,比如为1440,即保存一天,之后再自动删除
vim core-site.xml
<!--1440为1天,60min*24h-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
7.2 垃圾桶取回
删除时会显示移动的位置,mv指令移动出来即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









