




缓存三兄弟
1. 缓存穿透

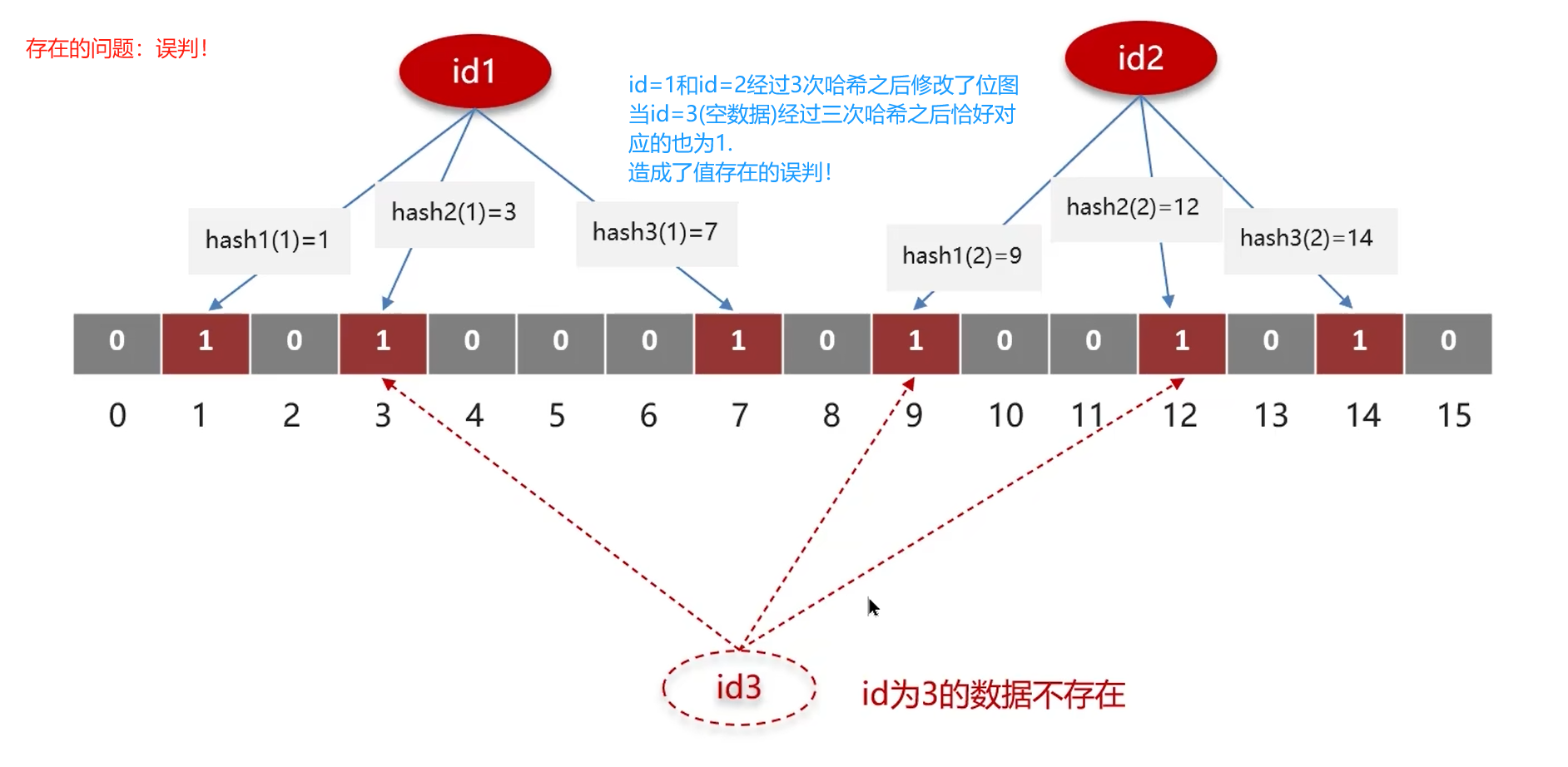

误判率:数组越小,误判率越大;数组越大,误判率越小,但带来了更多的内存消耗。
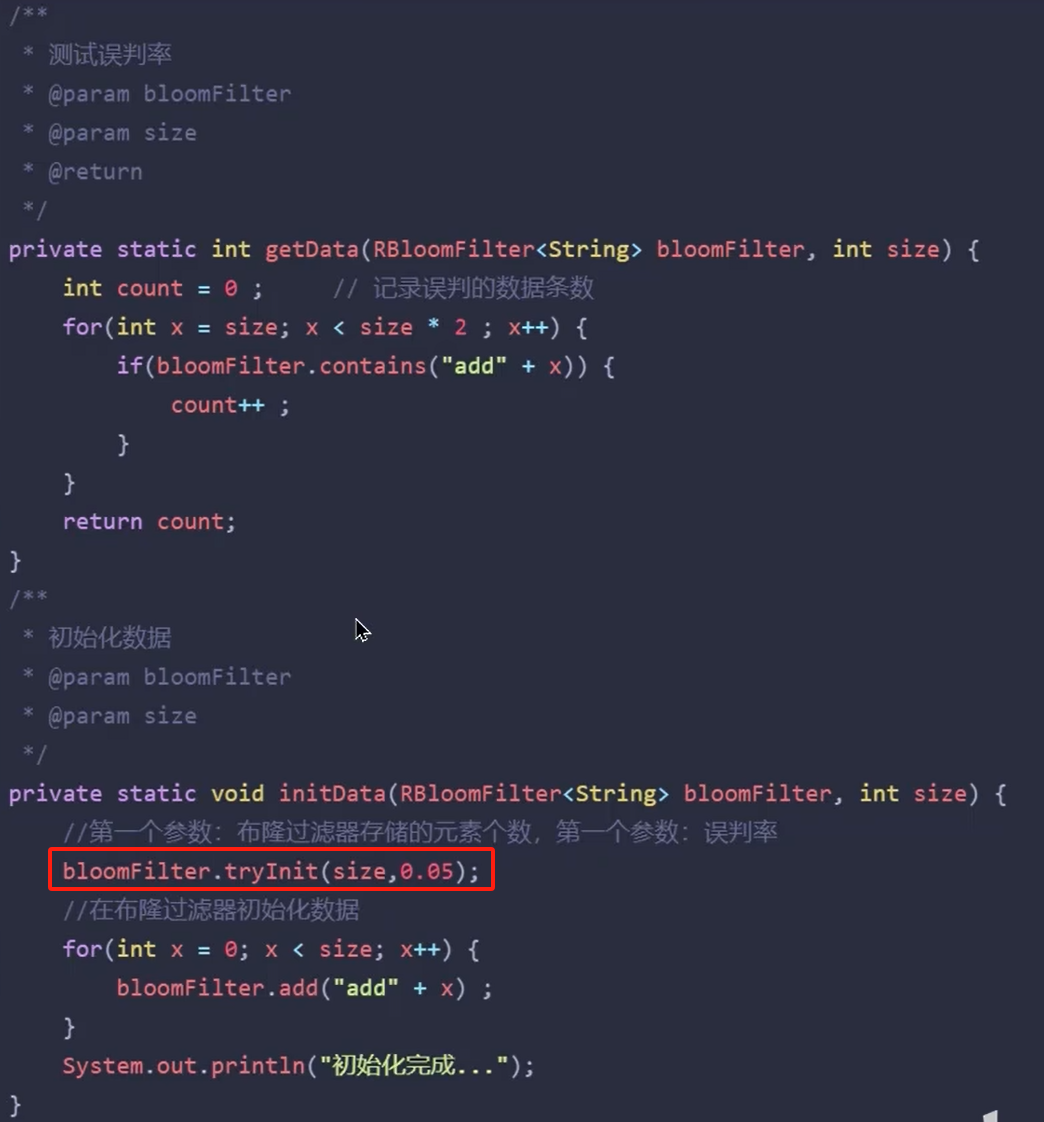
布隆过滤器的实现方案:Redisson、Guava。一般设置一个误判率,5%以内。
优点:内存占用少,没有多余key;
缺点:实现复杂,存在误判,但是通过设置误判率,可以精准控制内存成本(根据误判率自动计算处数组长度和hash函数个数),设置边界可匹配数据库的承载能力。
总结
- Redis 使用场景
根据自己的项目回答:缓存 or 分布式锁(常用的);
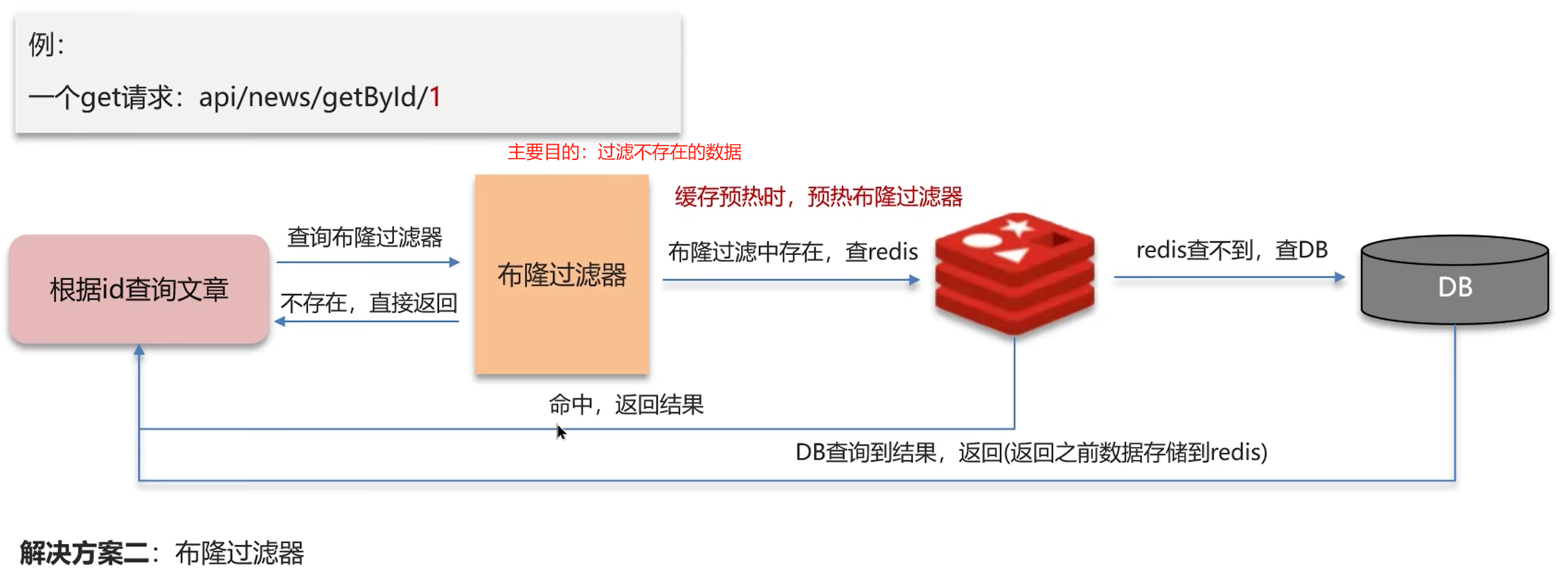
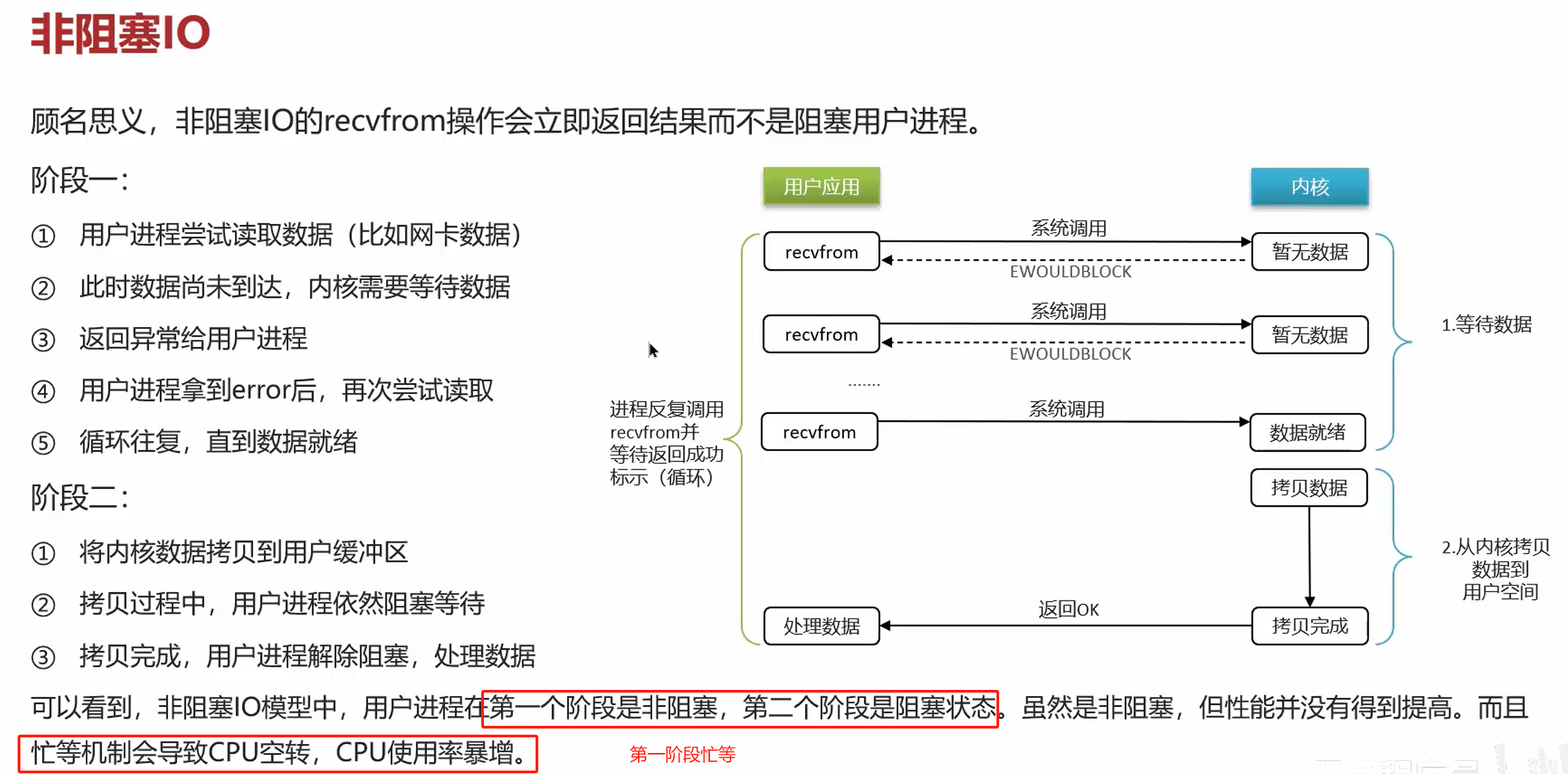
- 什么是缓存穿透?如何解决?
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
方案一:缓存空数据
方案二:布隆过滤器
2. 缓存击穿
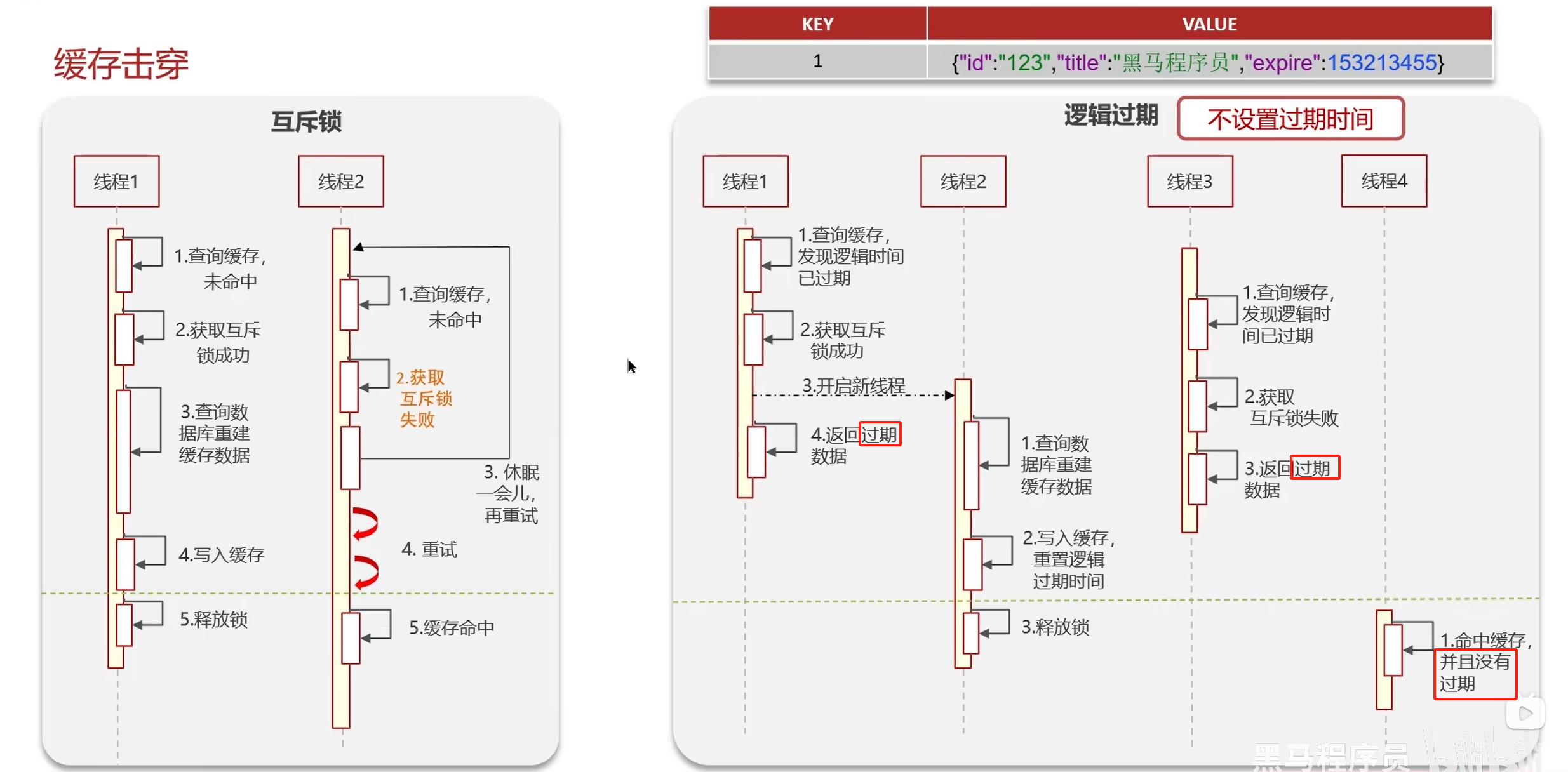 互斥锁:强一致,性能差(银行行业);
互斥锁:强一致,性能差(银行行业);
逻辑过期:高可用,性能优(互联网);
总结
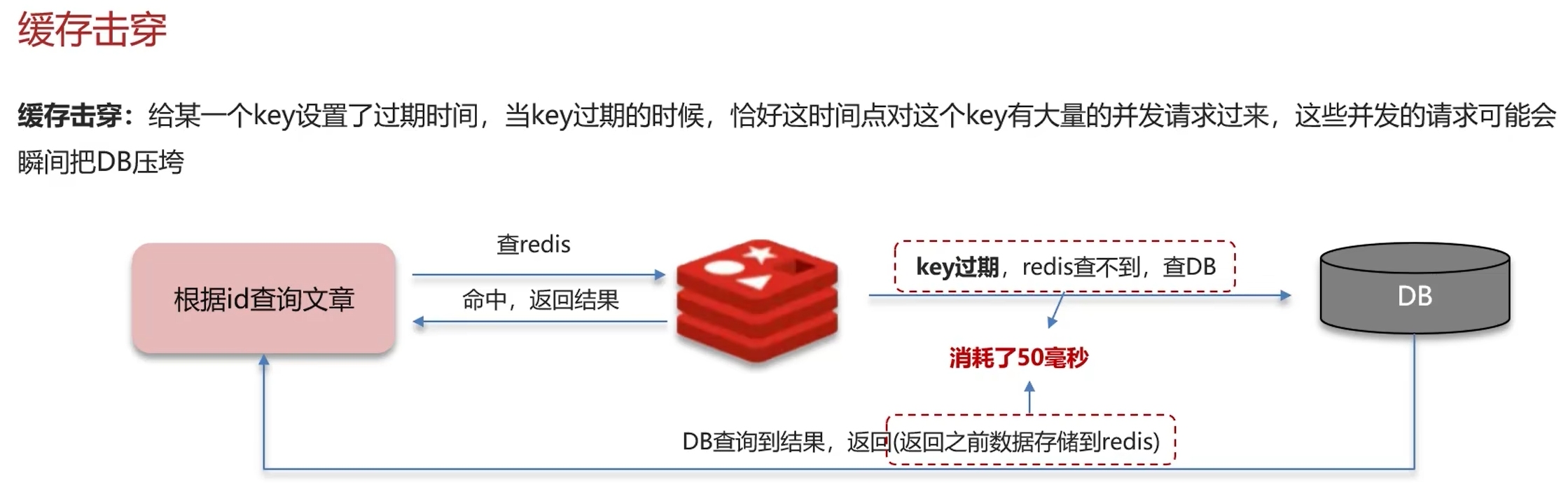
- 解释一下缓存击穿
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮。
解决方案一:互斥锁,强一致,性能差
解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致
3. 缓存雪崩

以上三种模式,都可以用限流策略来保底。
双写一致性
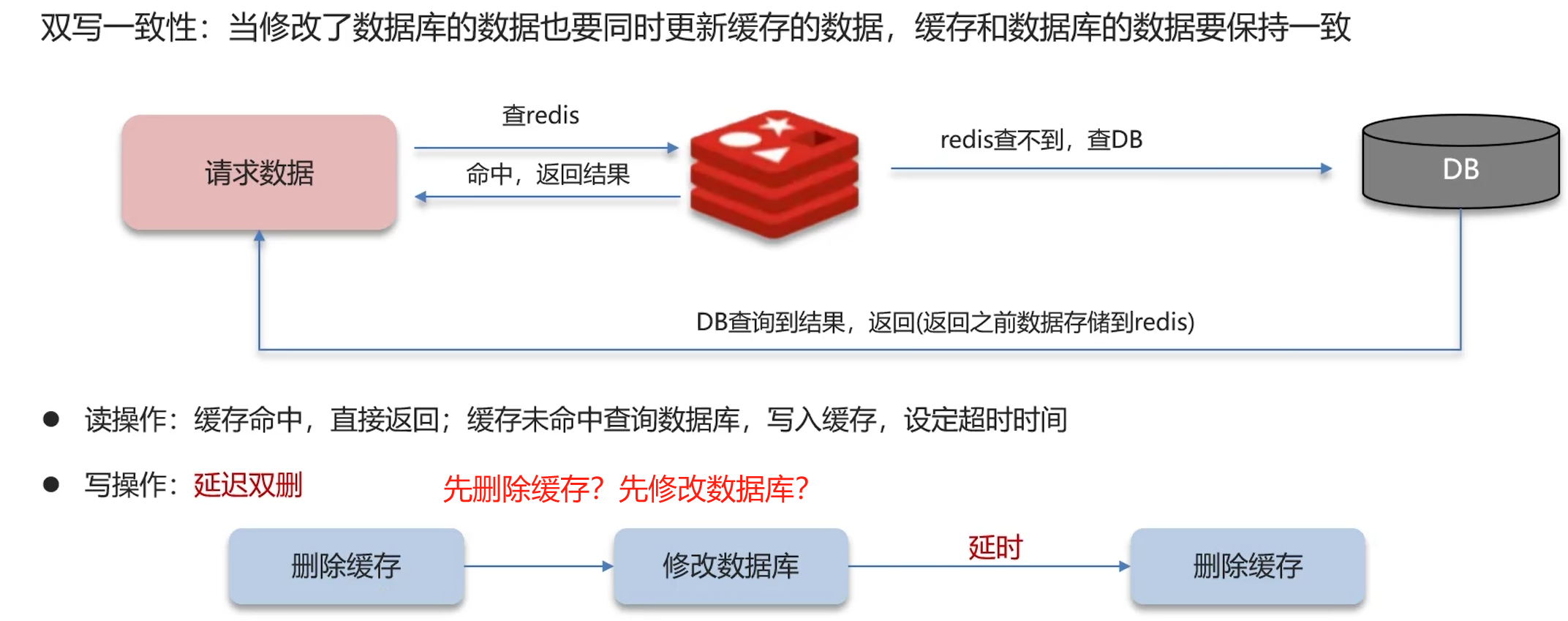
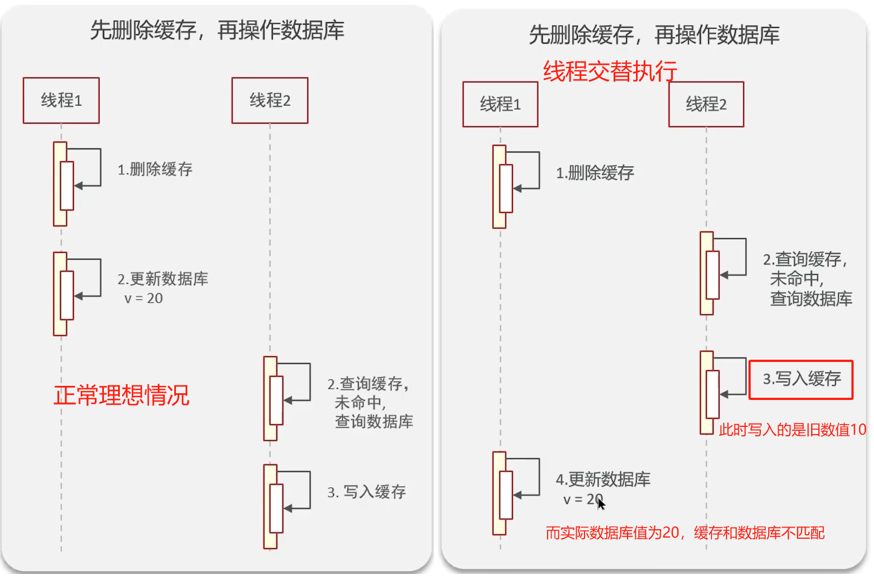
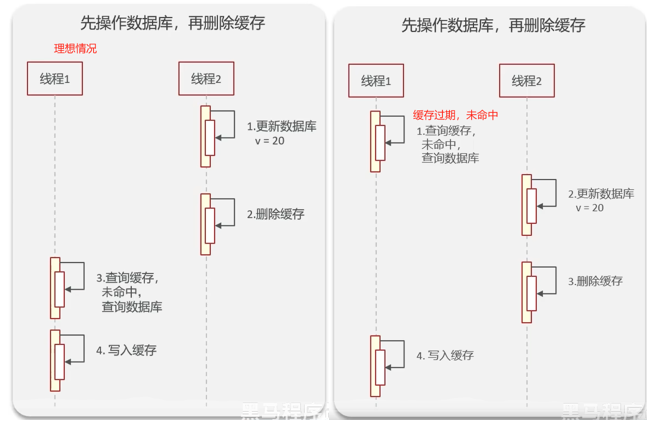
缺点:出现脏数据;因此删除两次;延时:主从DB,读写分离,需要等同步。

强一致性:
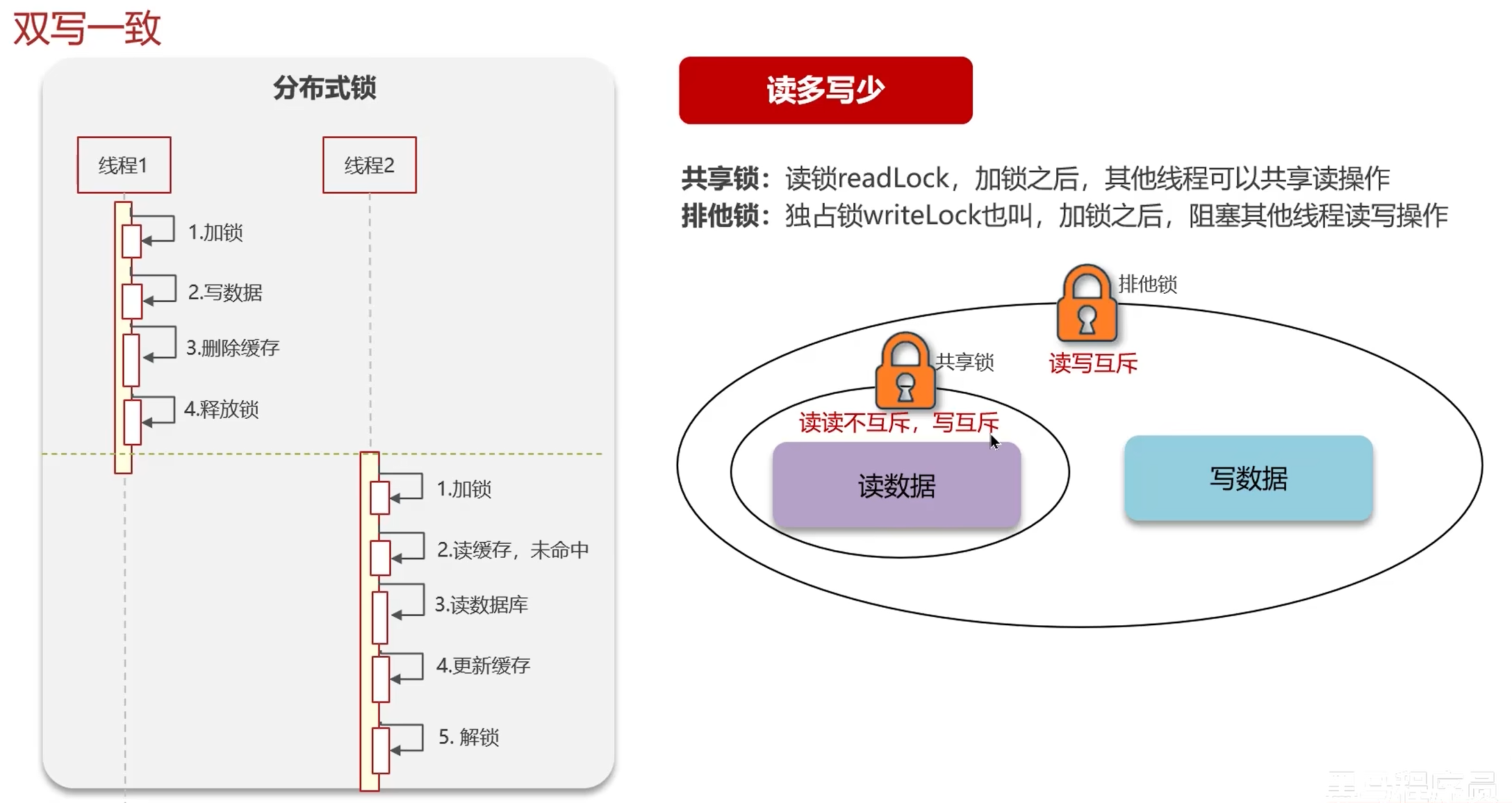
读时:共享锁;写时:排他锁。保证强一致性。
有很多时候只要保证最终一致性即可,允许短暂不一致:
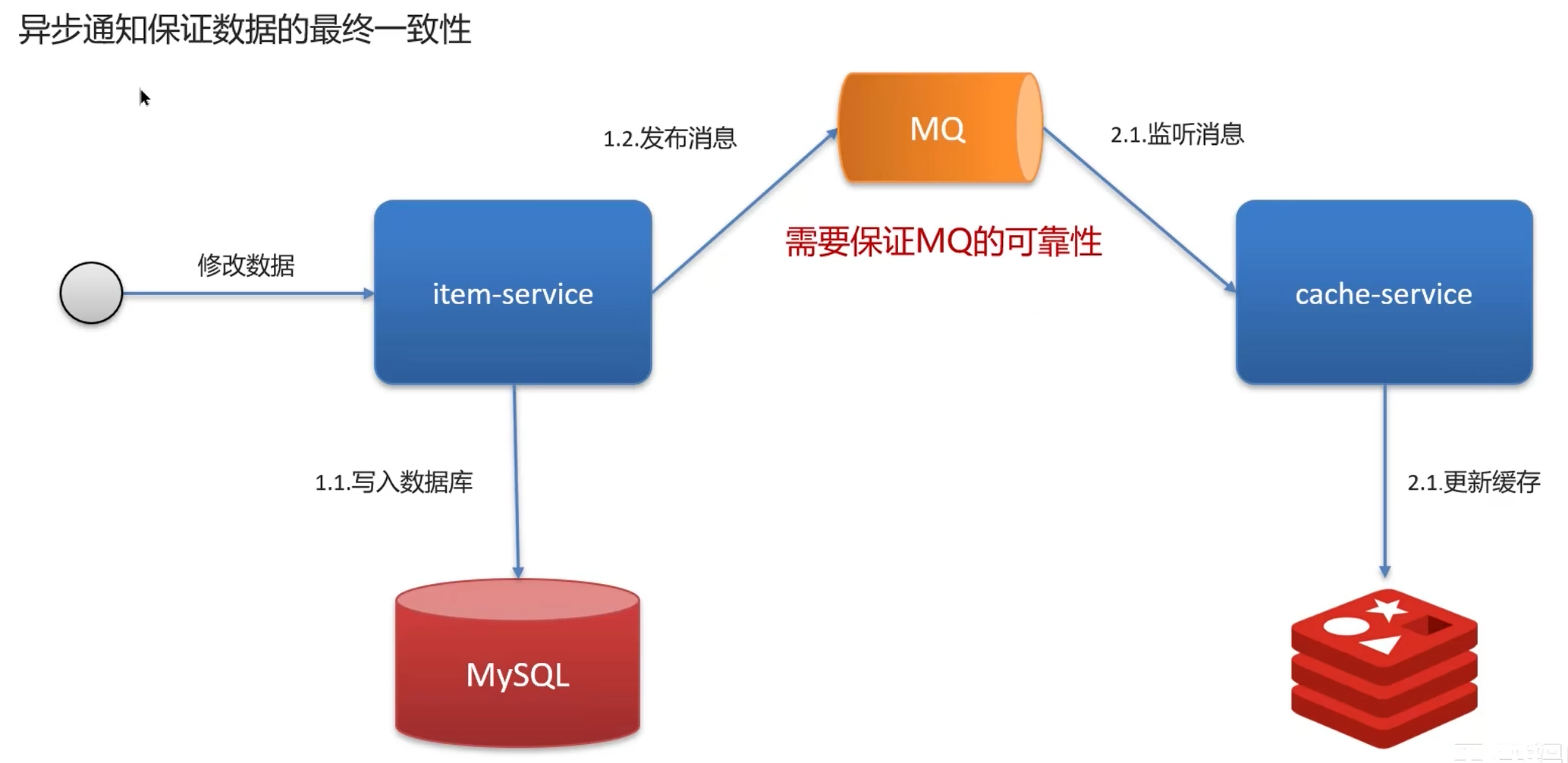
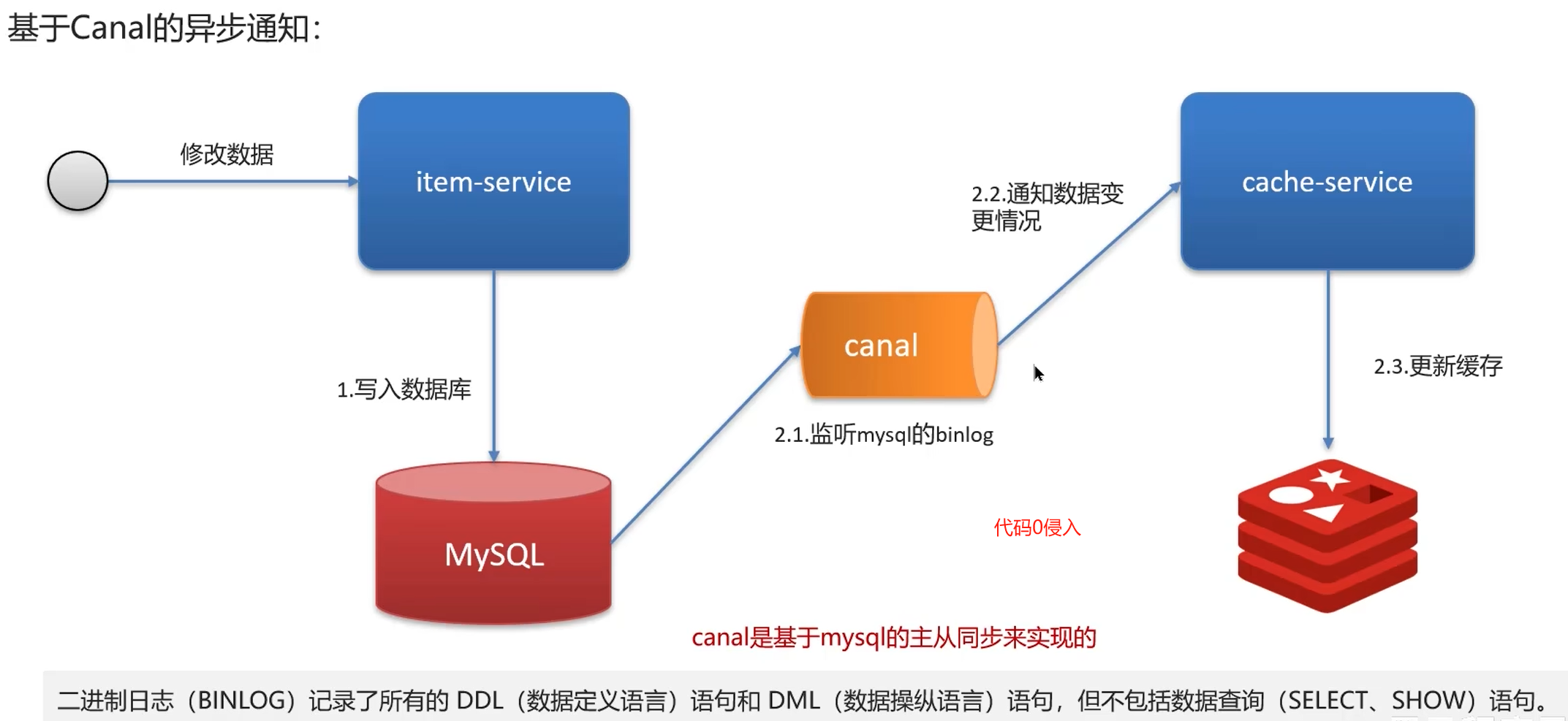

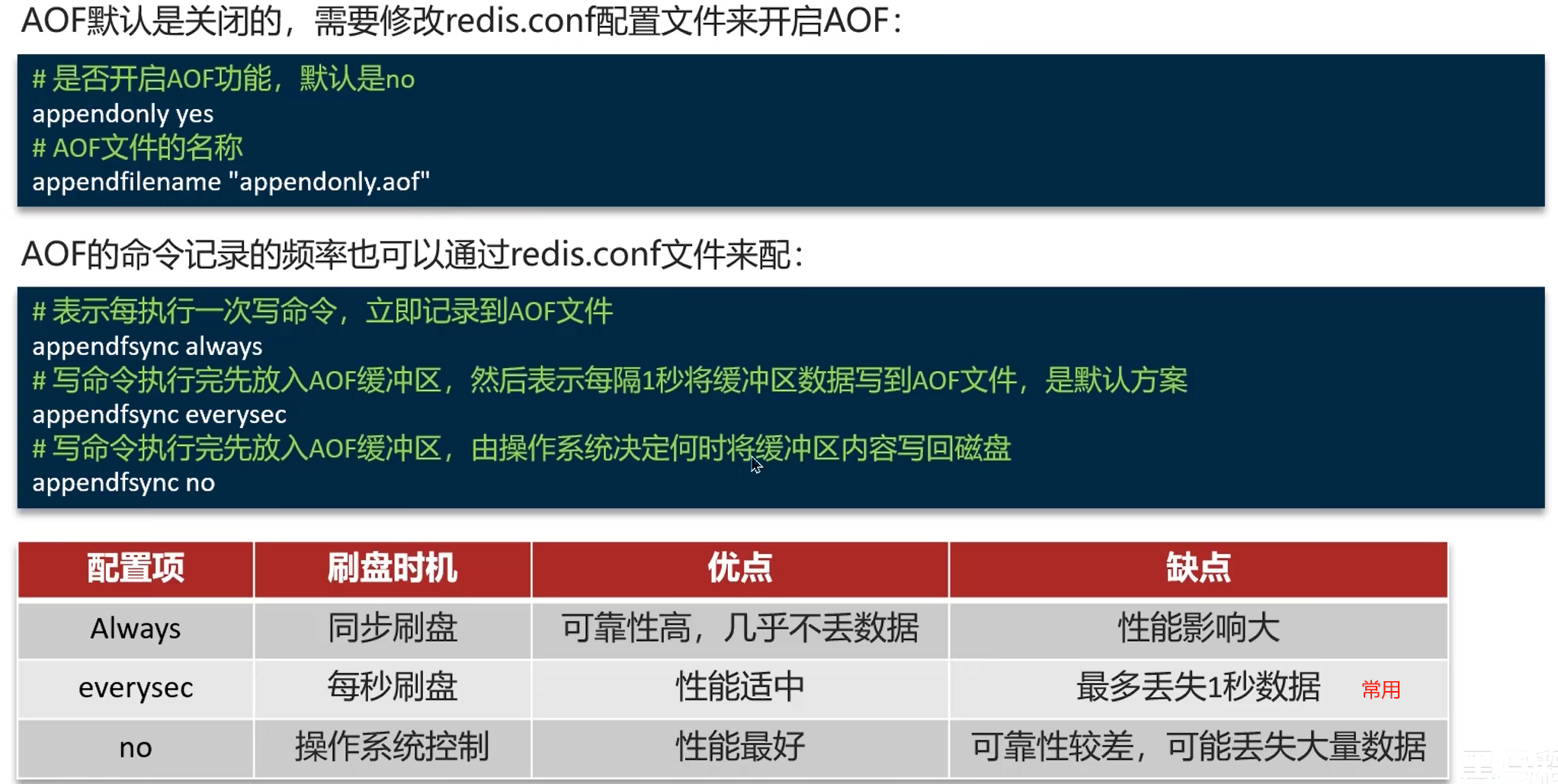
持久化
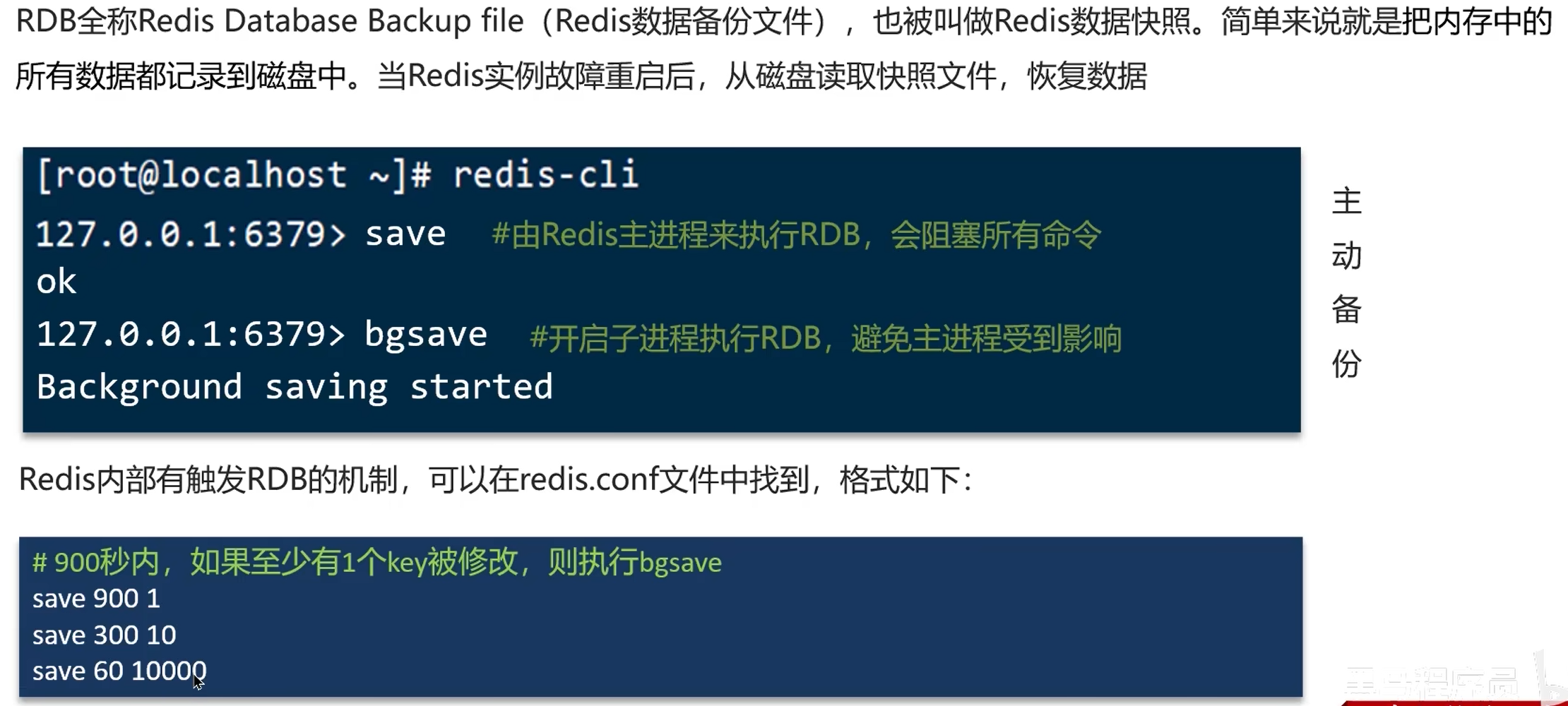
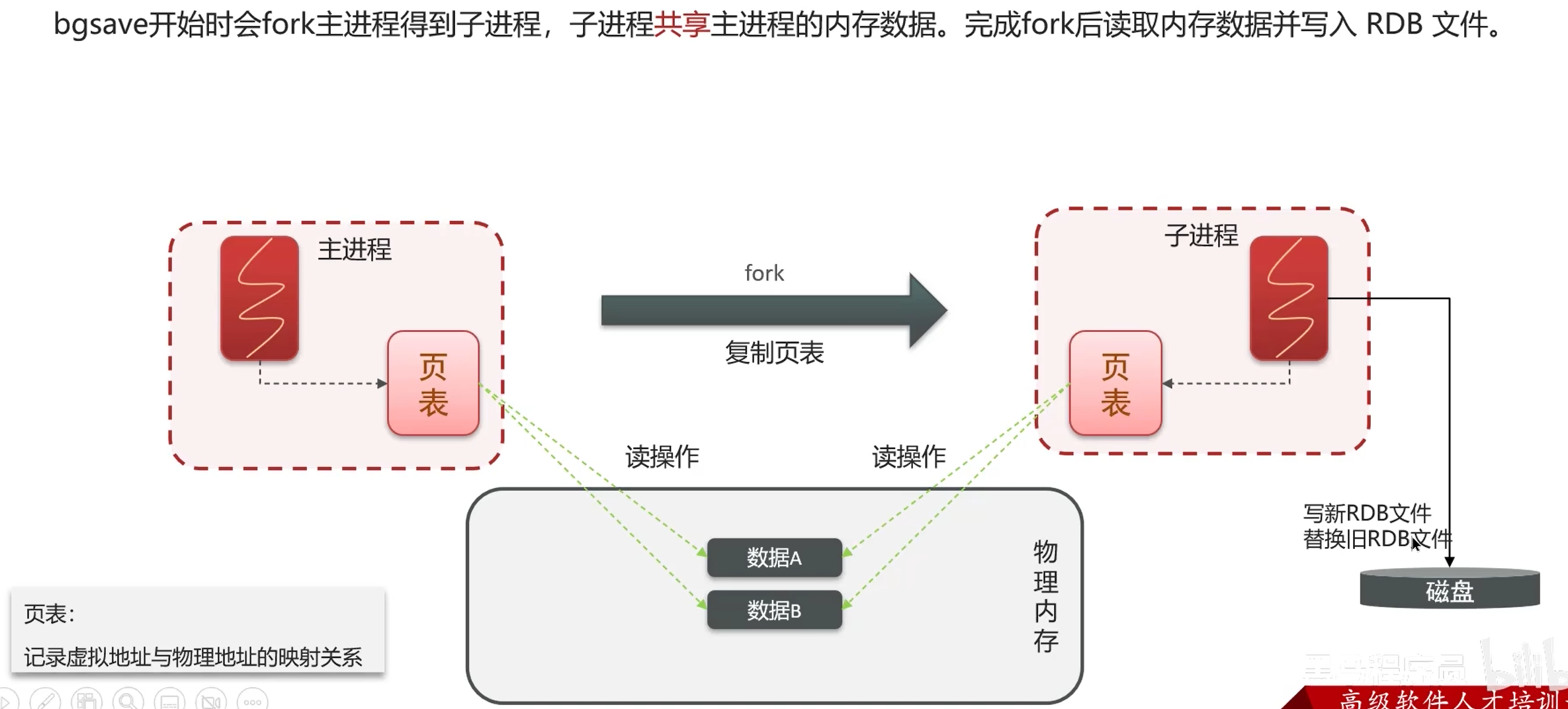
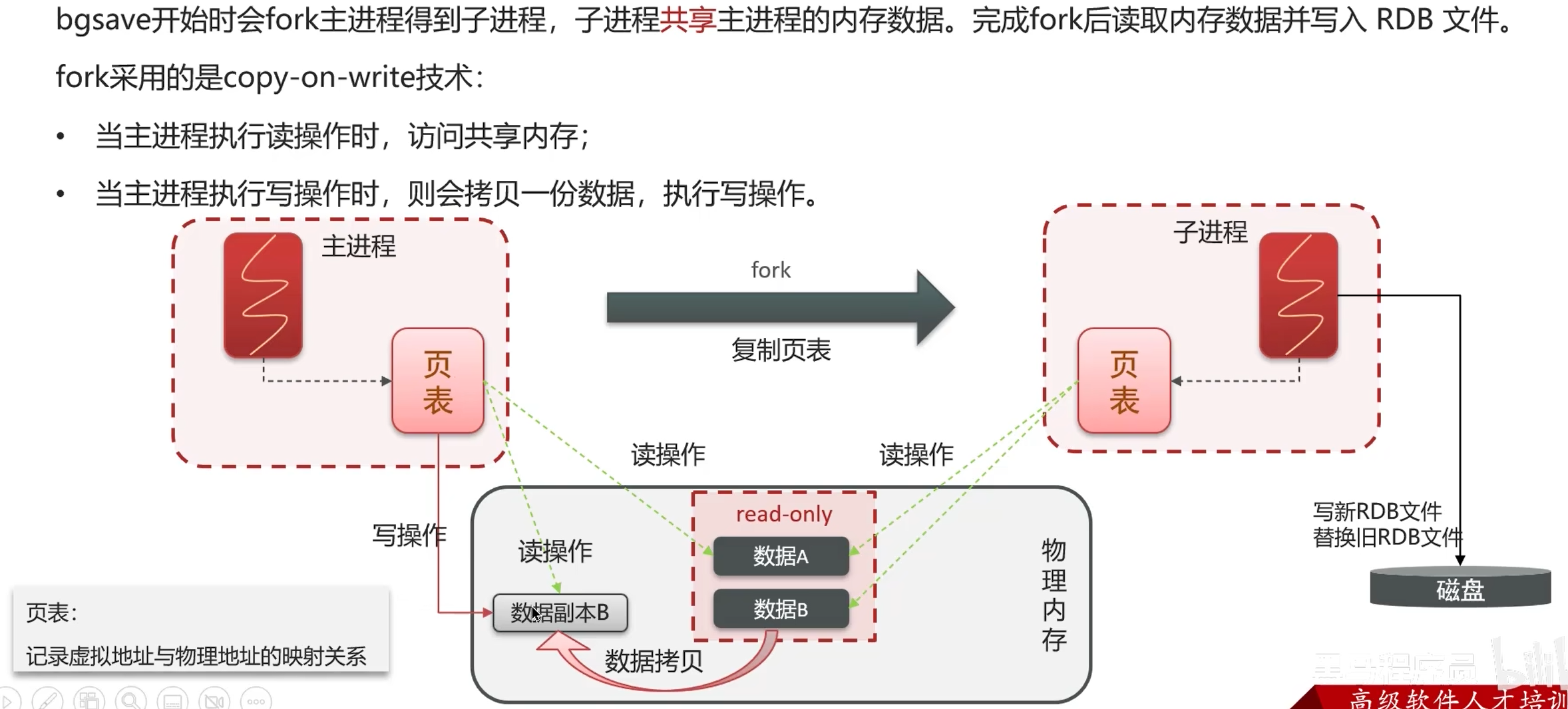
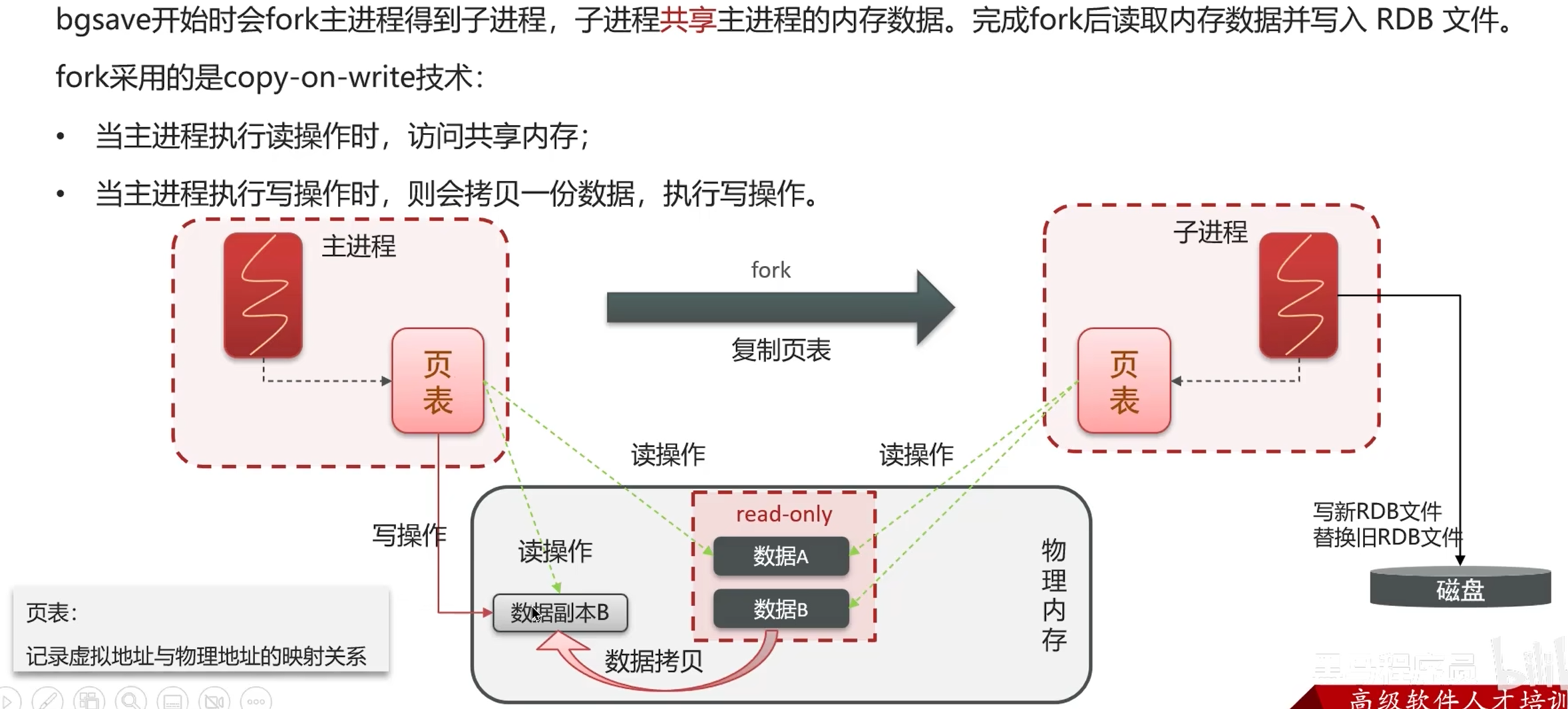
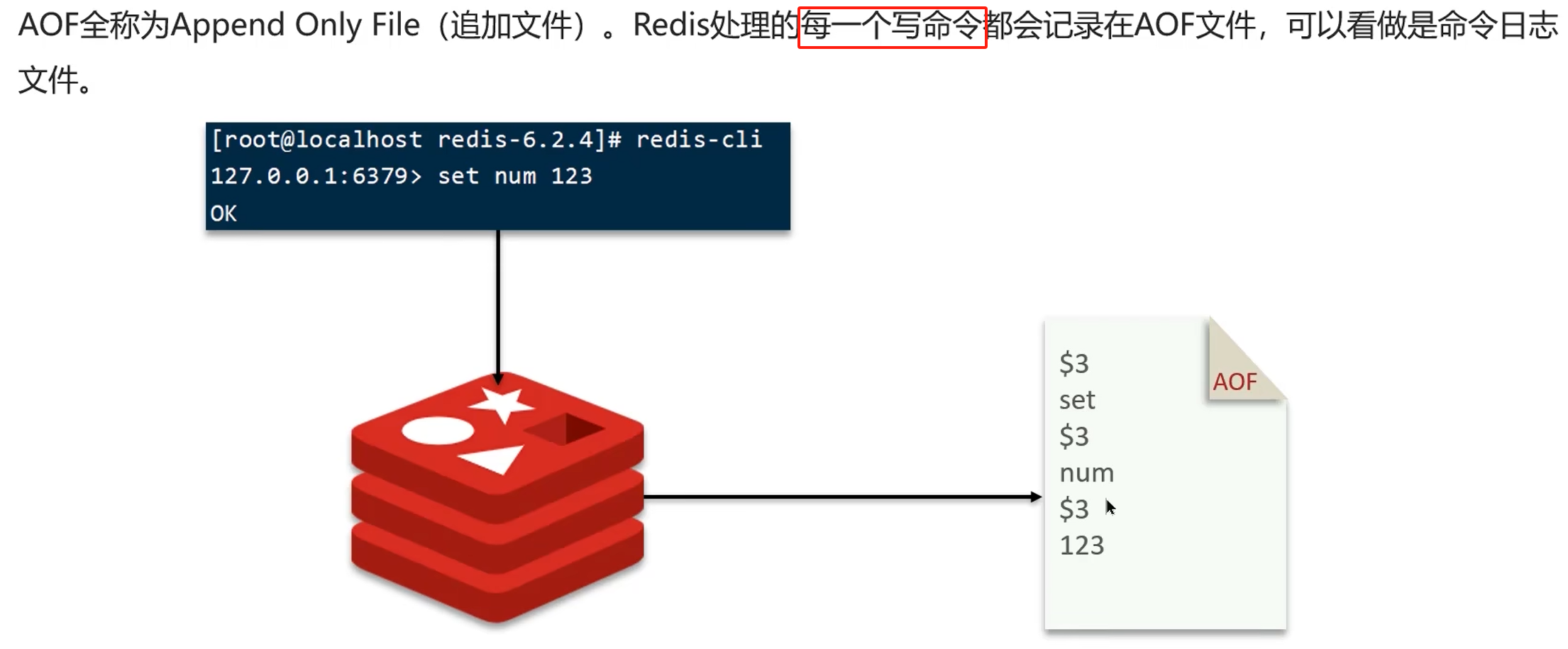

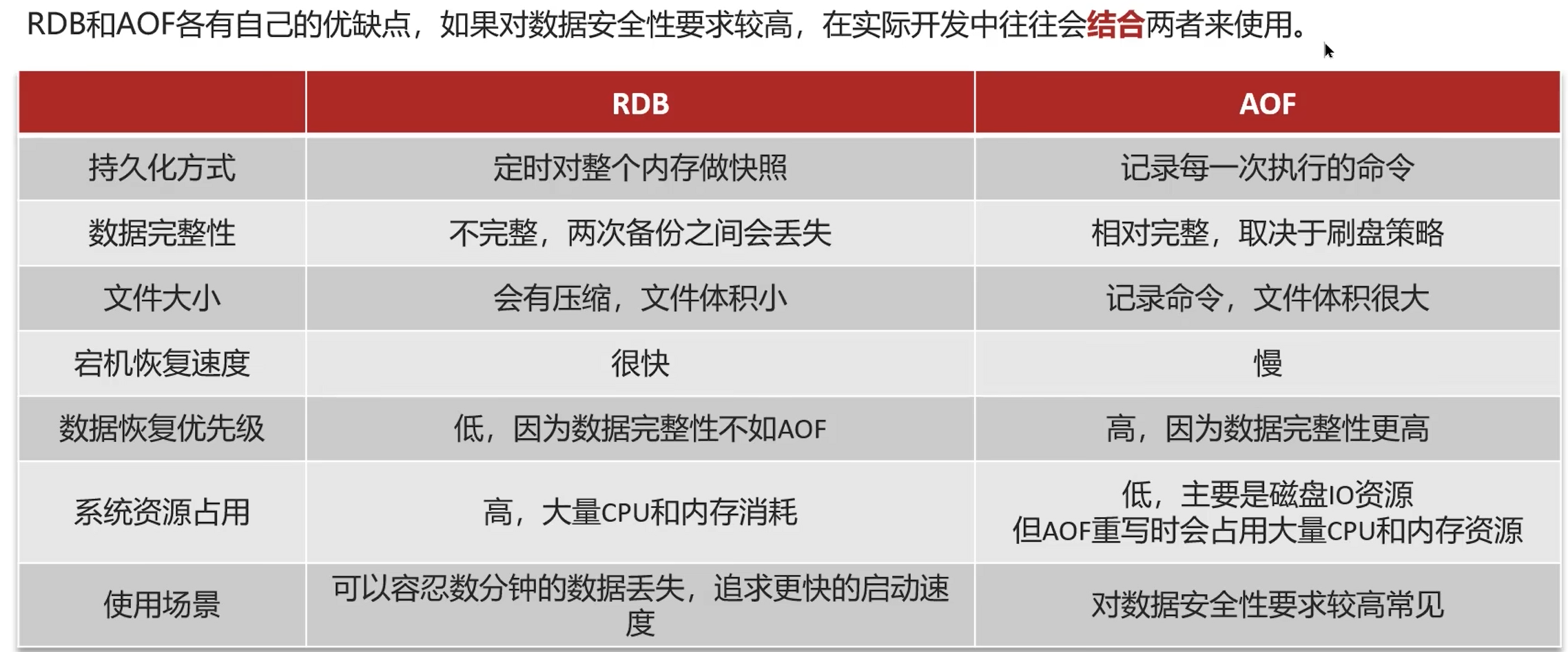
数据过期策略


Redis的过期删除策略:惰性删除+定期删除两种策略进行配合使用。
数据淘汰策略




分布式锁
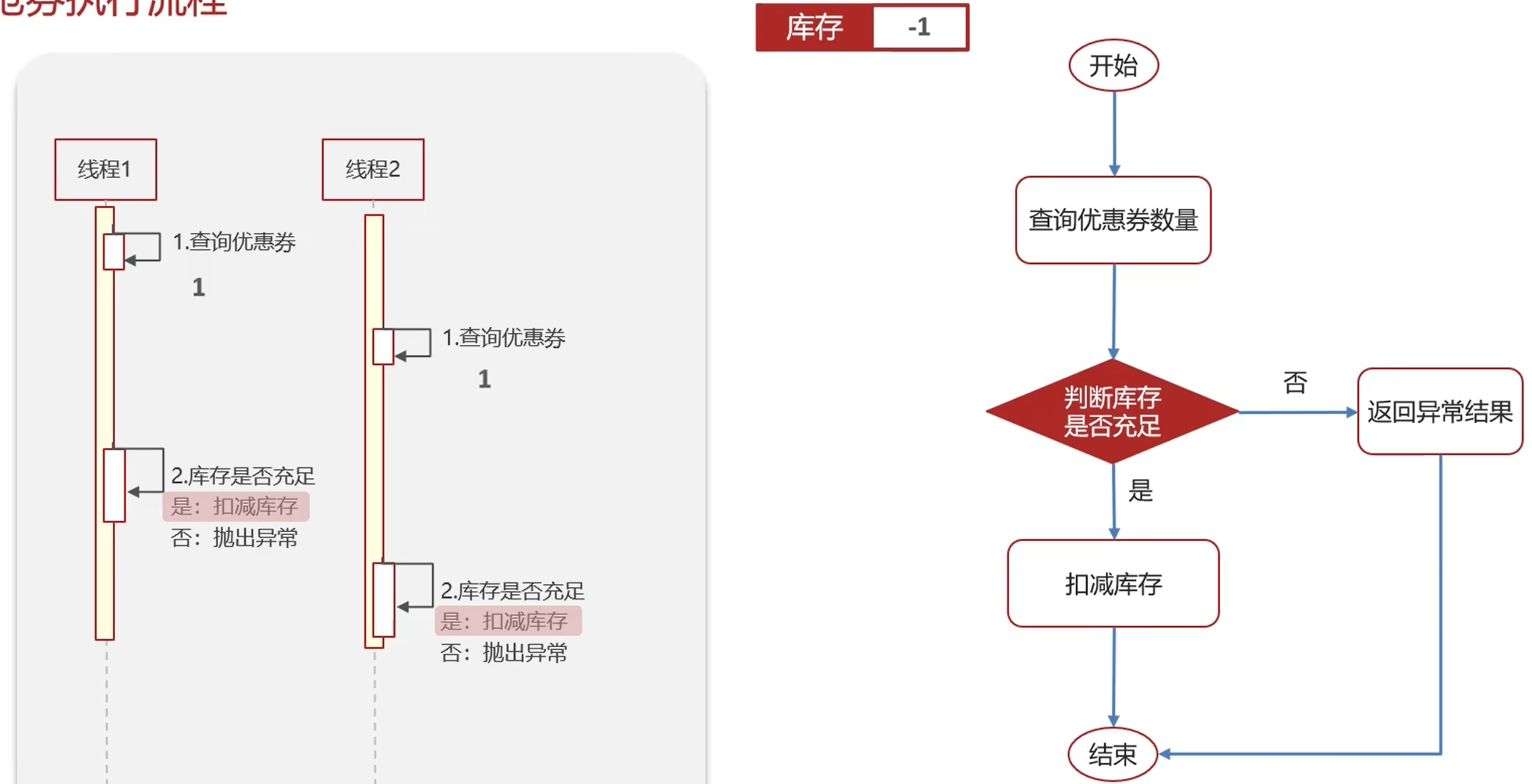
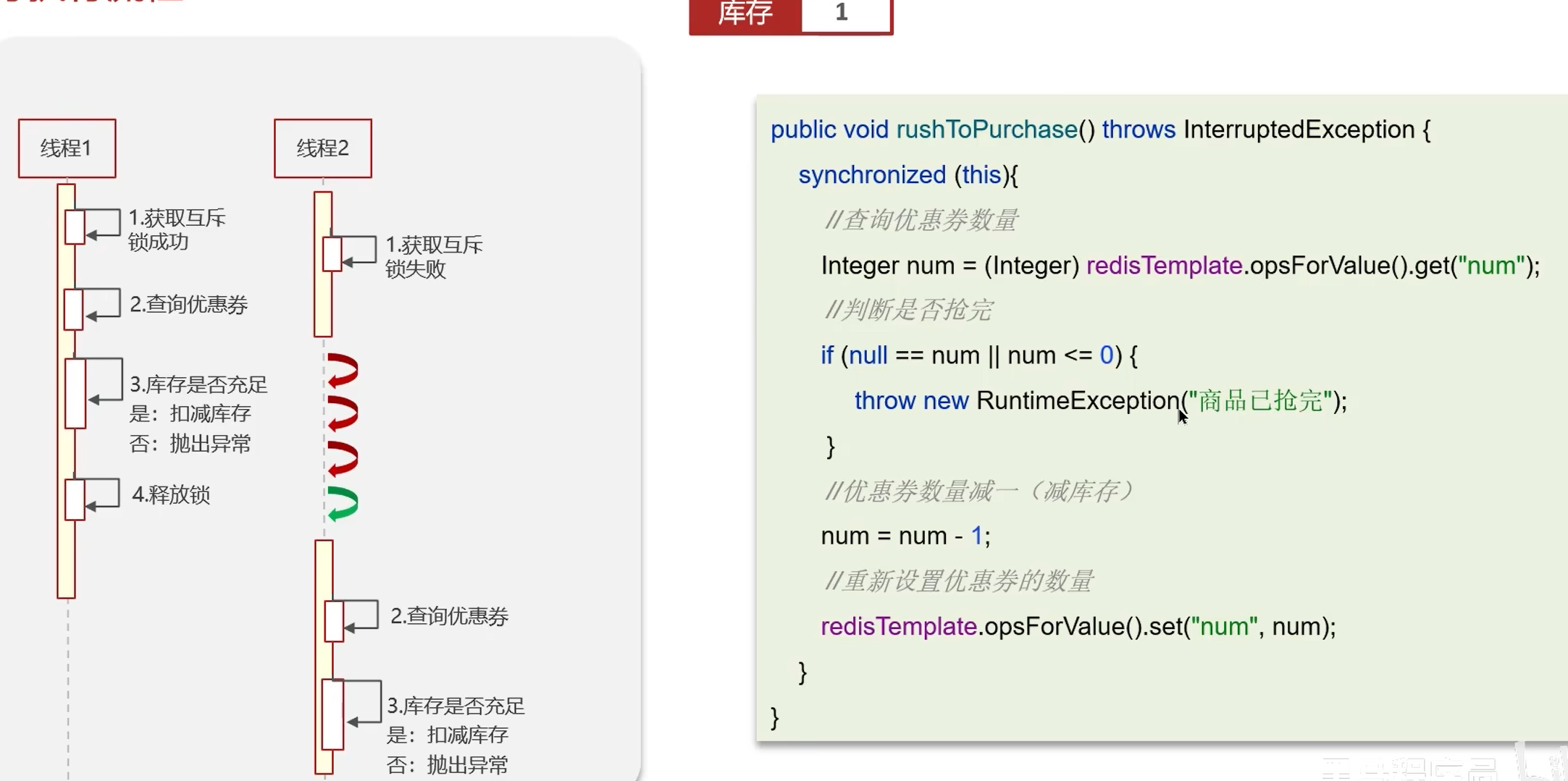
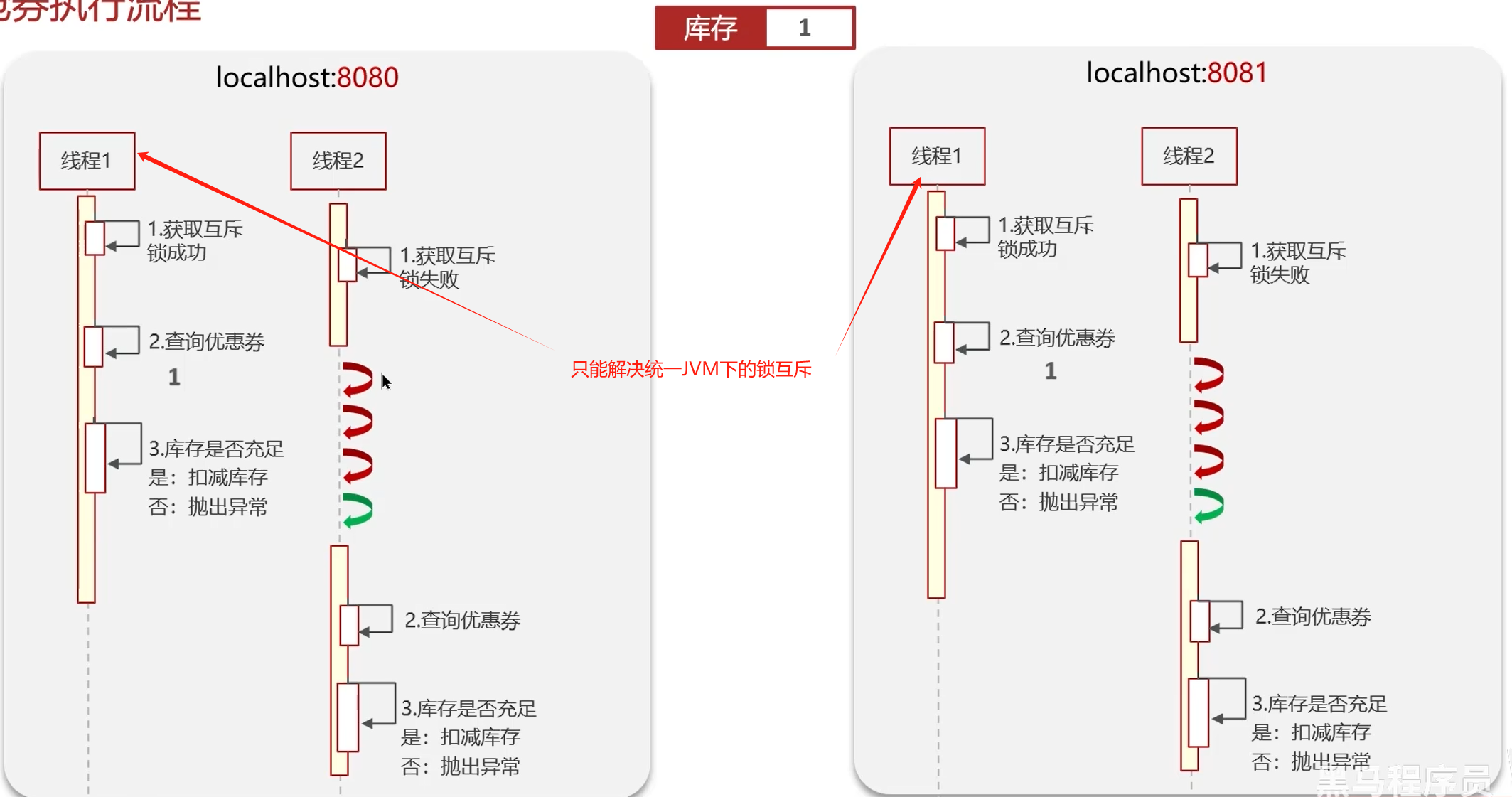
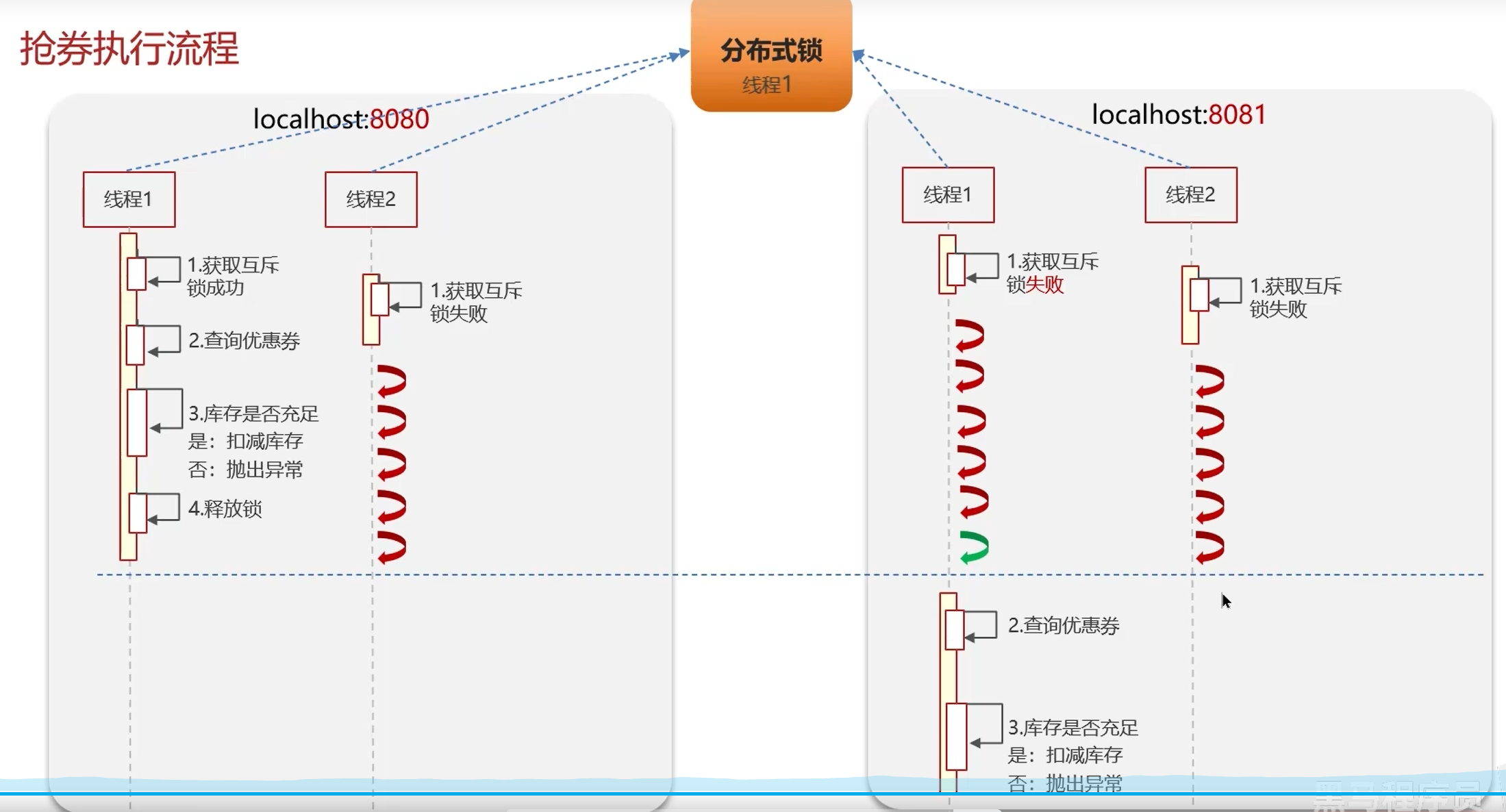
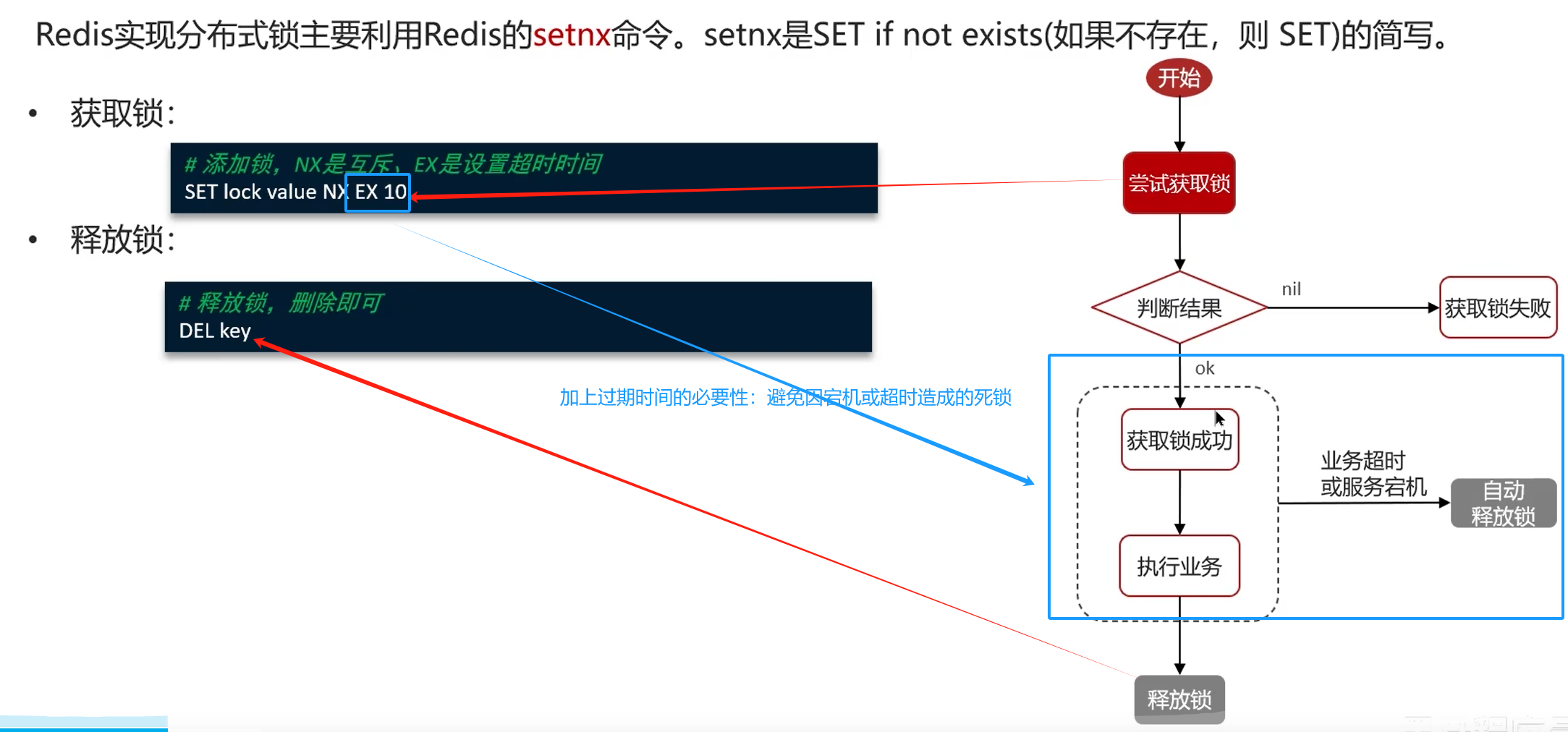

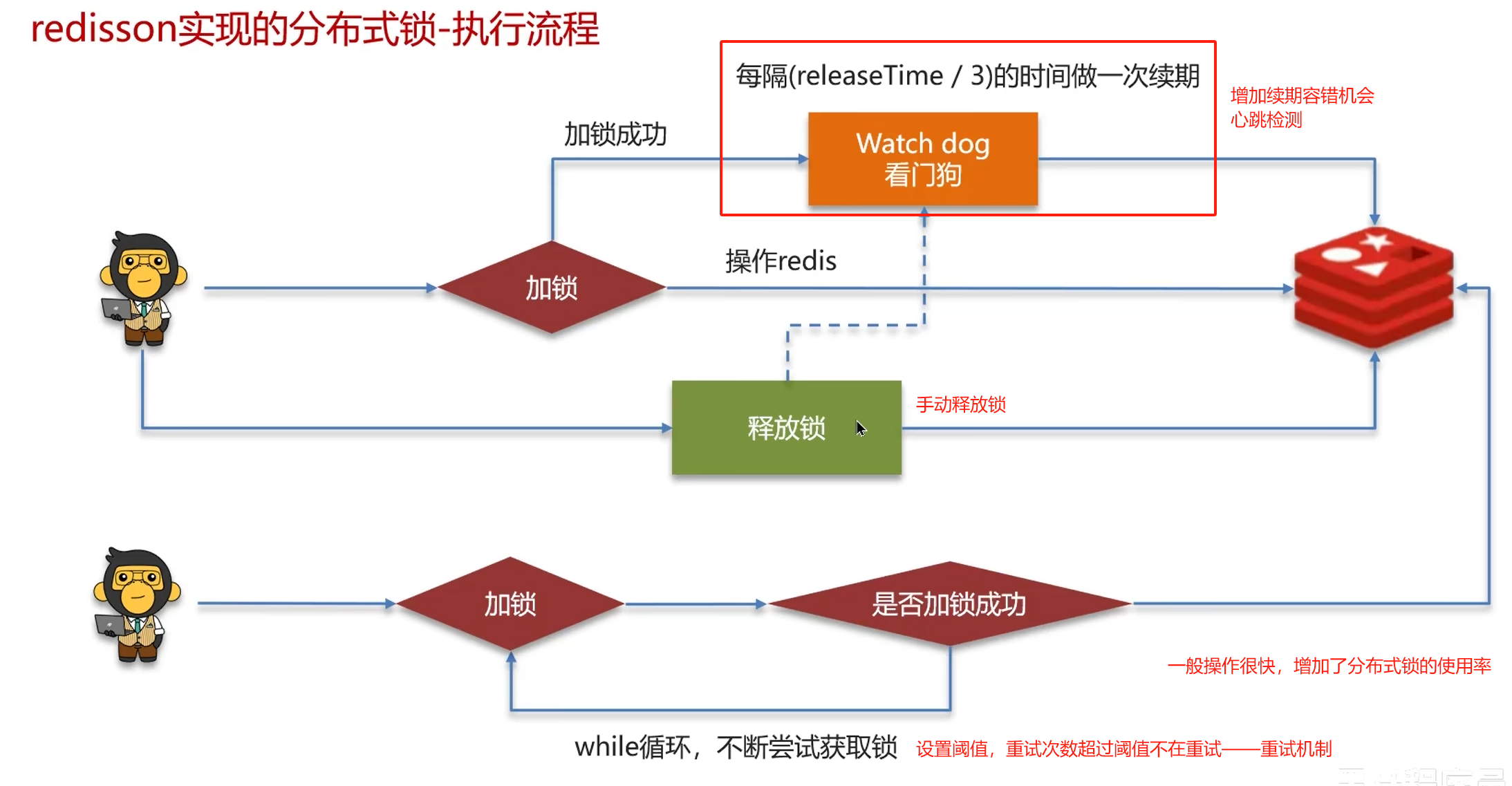
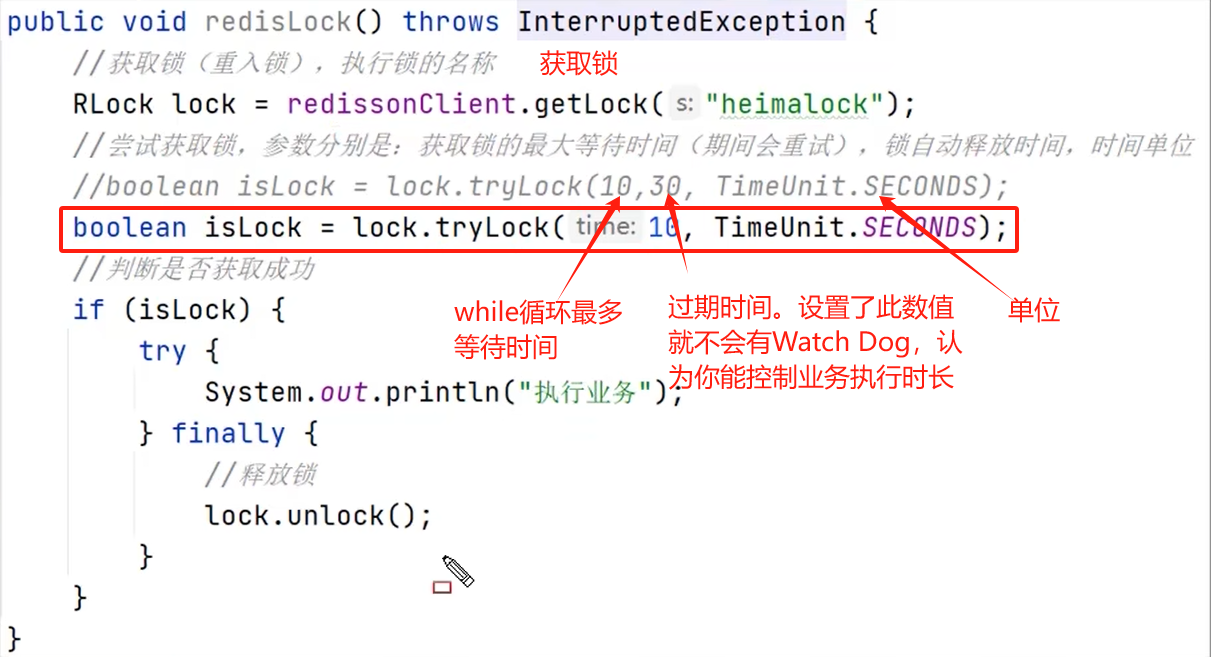

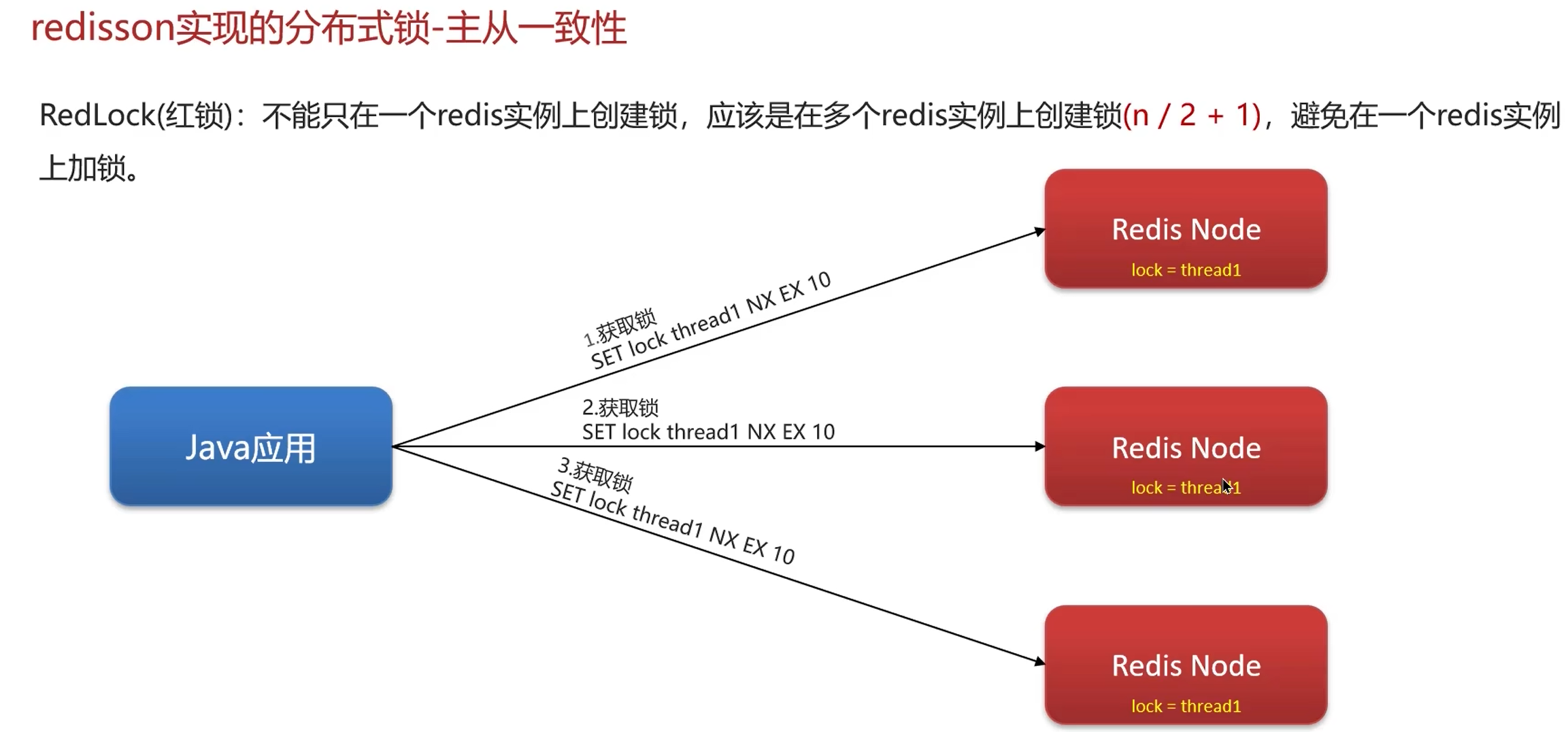
实现复杂、性能差、运维繁琐。如果非要:使用zookeeper保证强一致性。

Redis集群方案

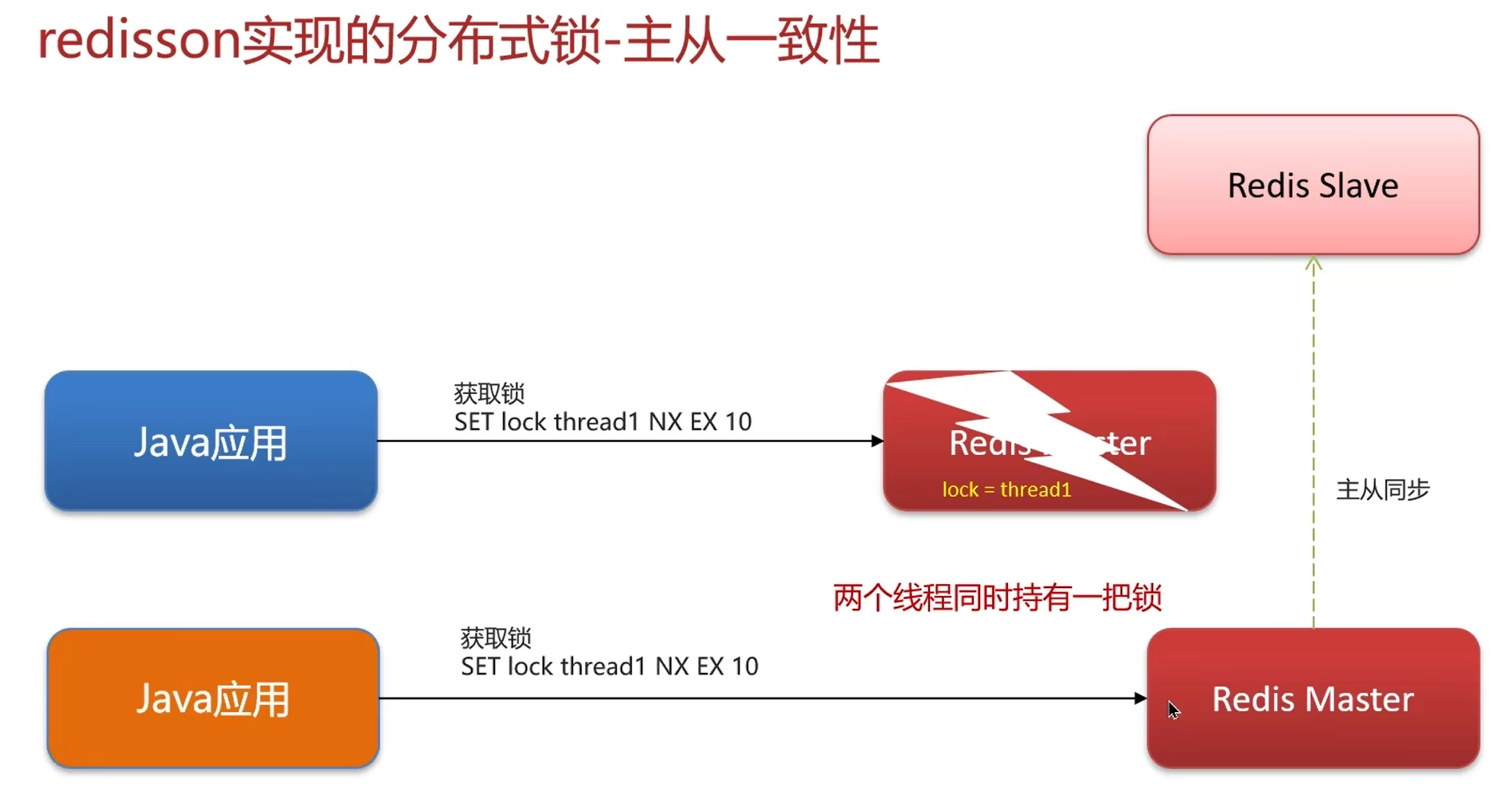
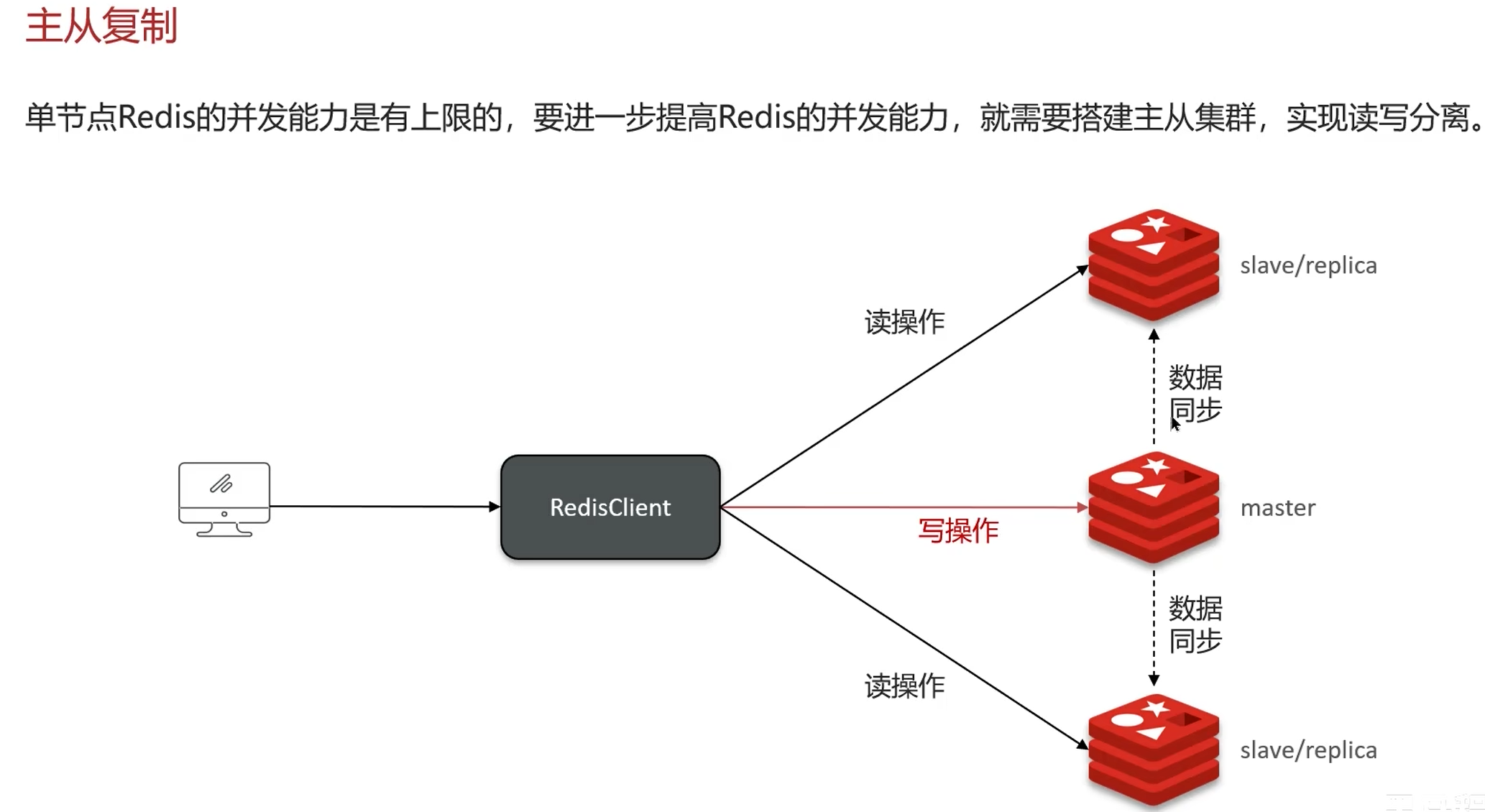
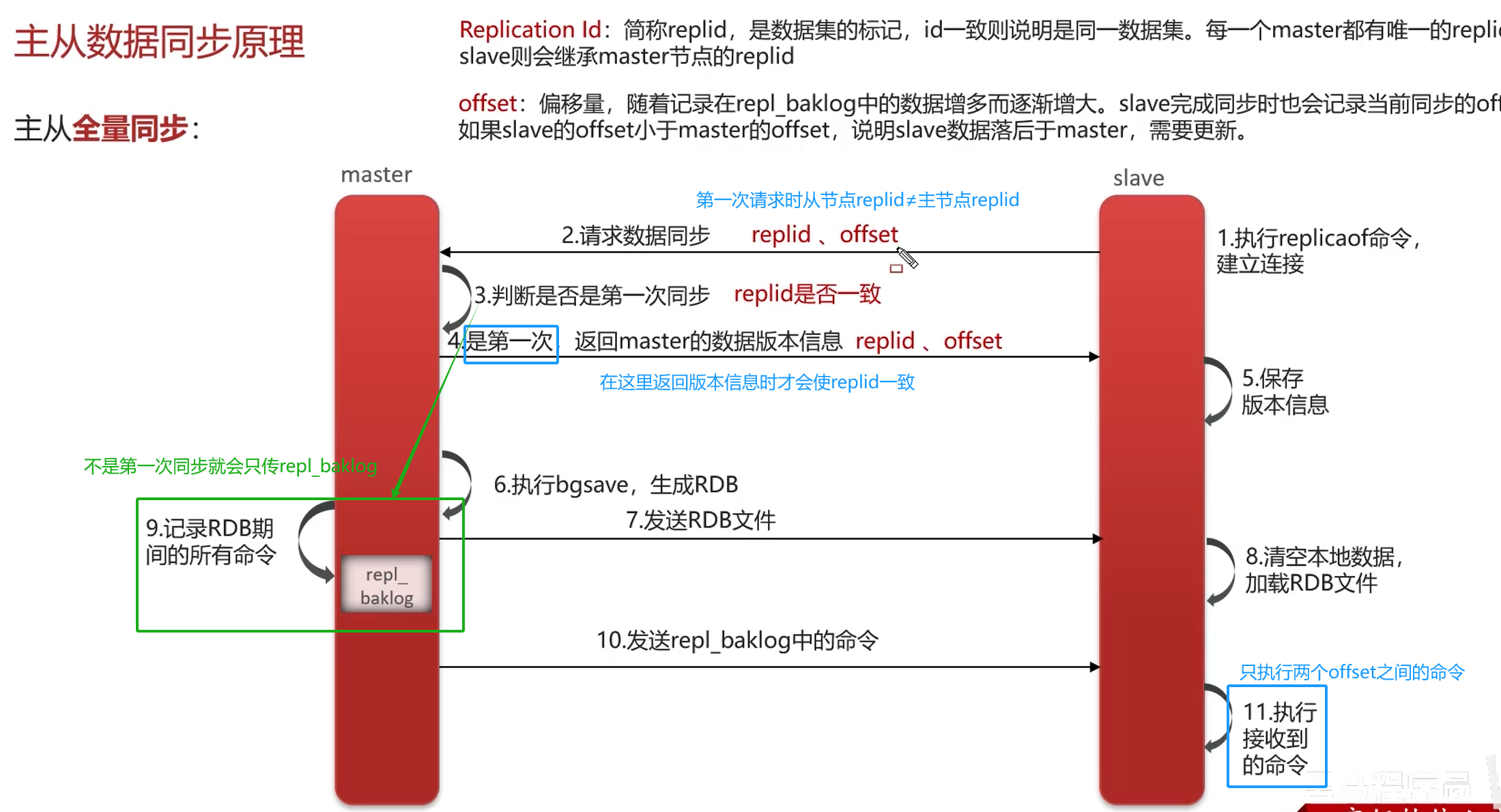
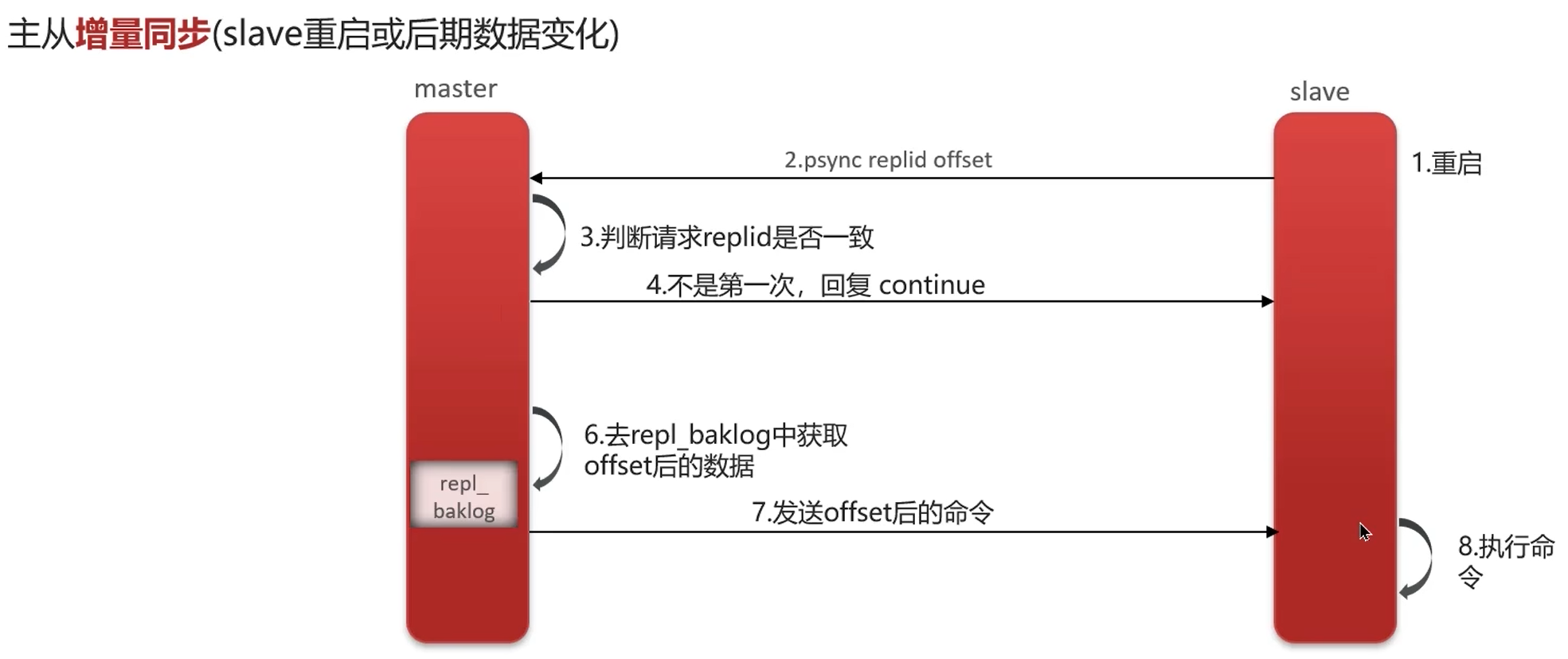
1. 主从一致

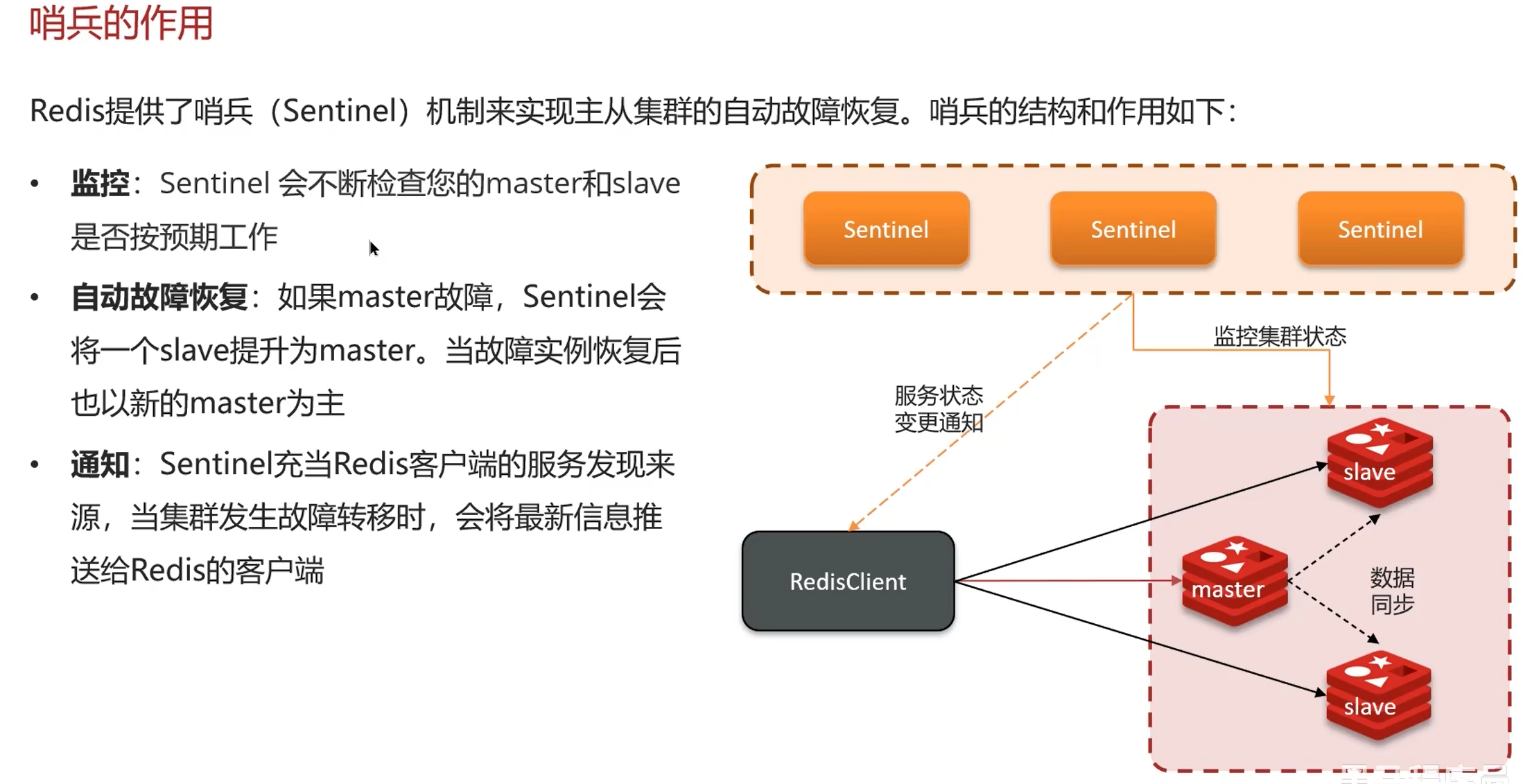
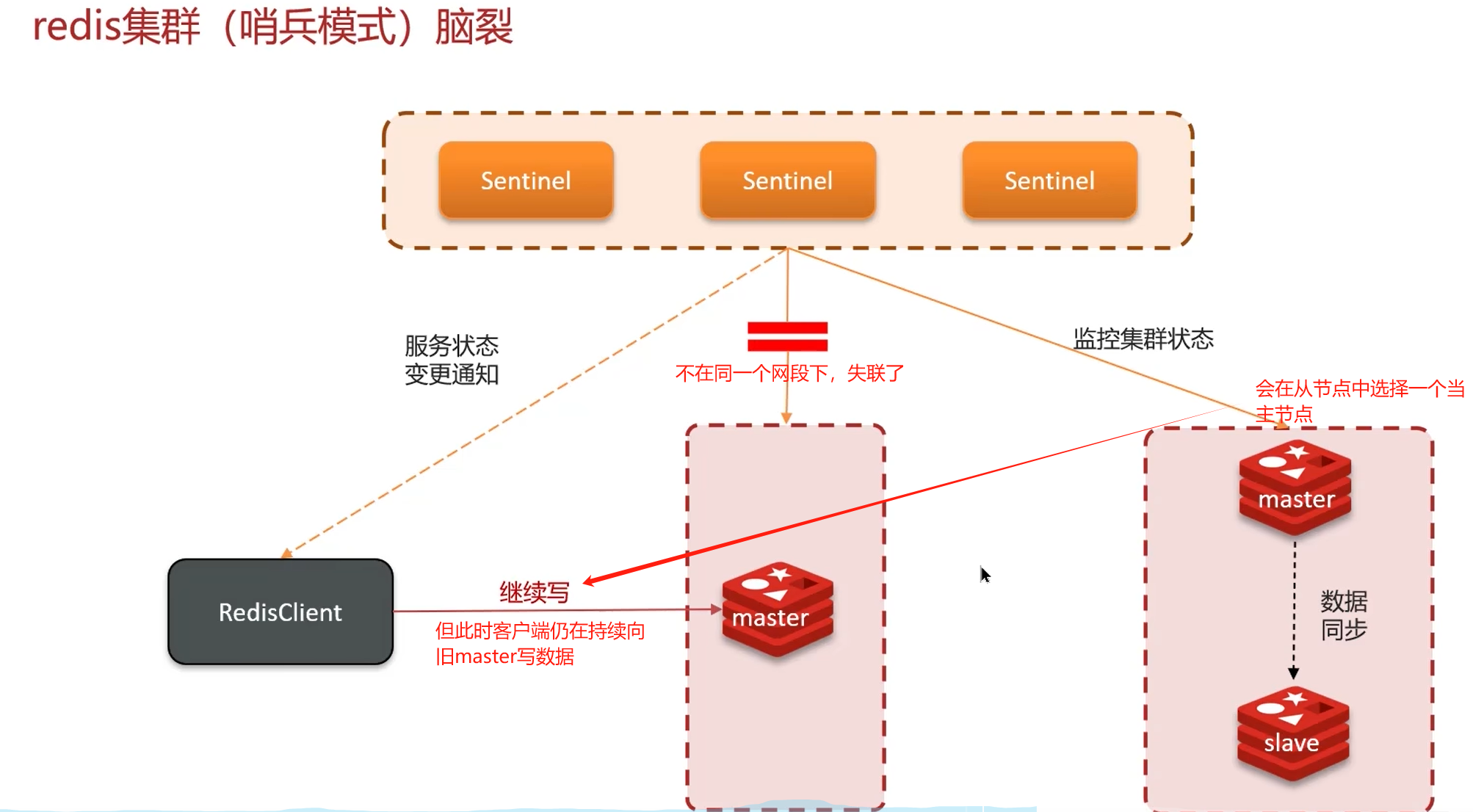
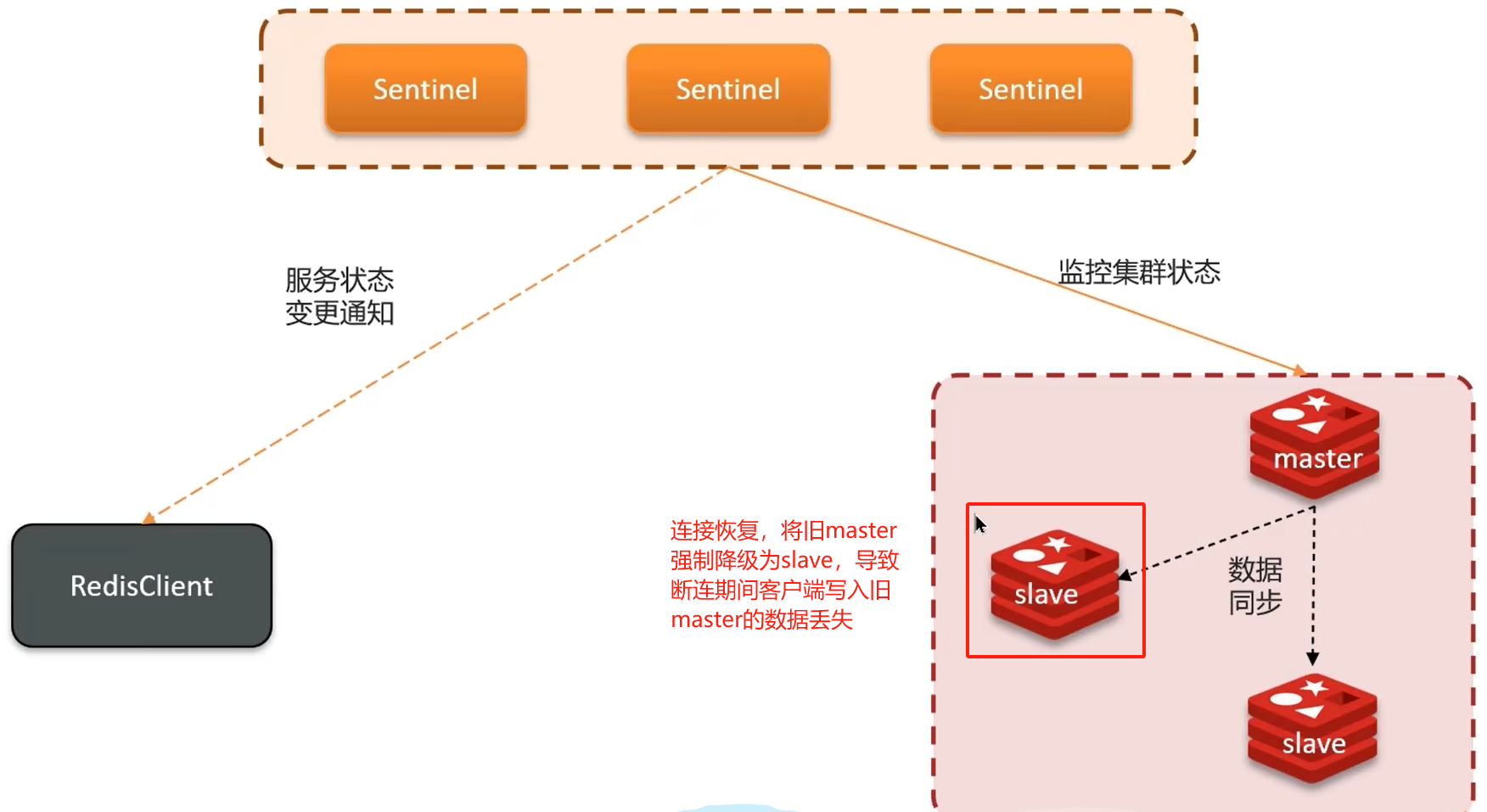
2. 哨兵模式
主从节点:保证不了集群的高可用,主节点宕机则失去写数据的能力。



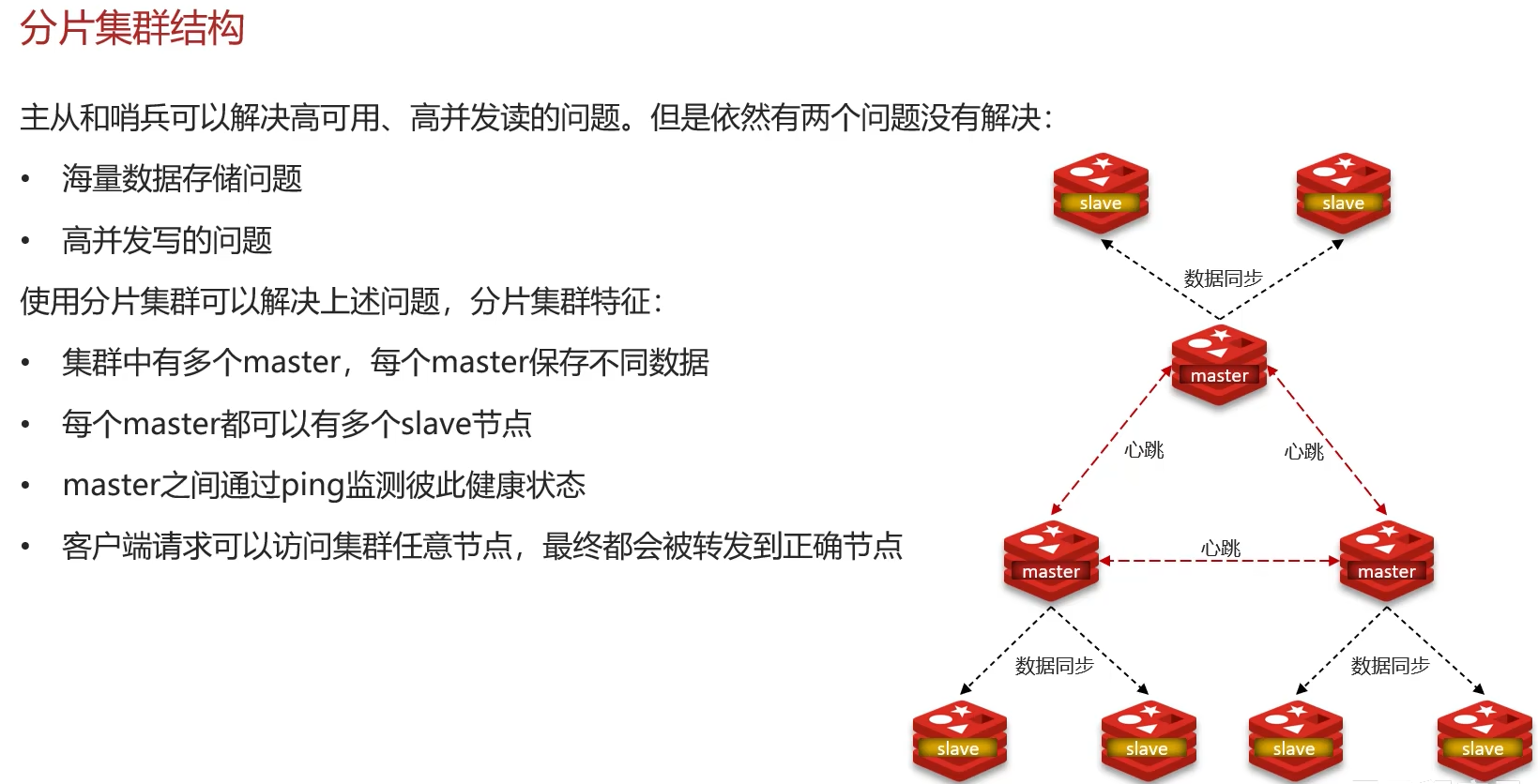
3. 分片集群


redis其他问题

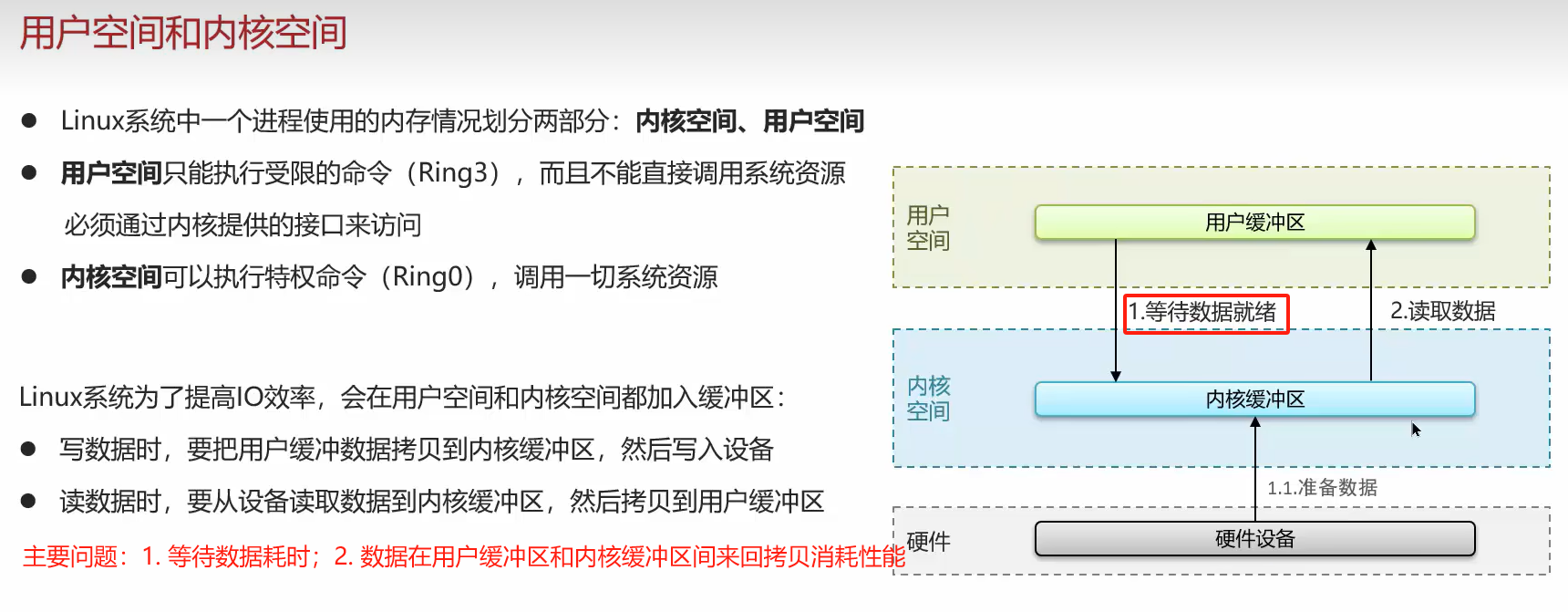
因此:
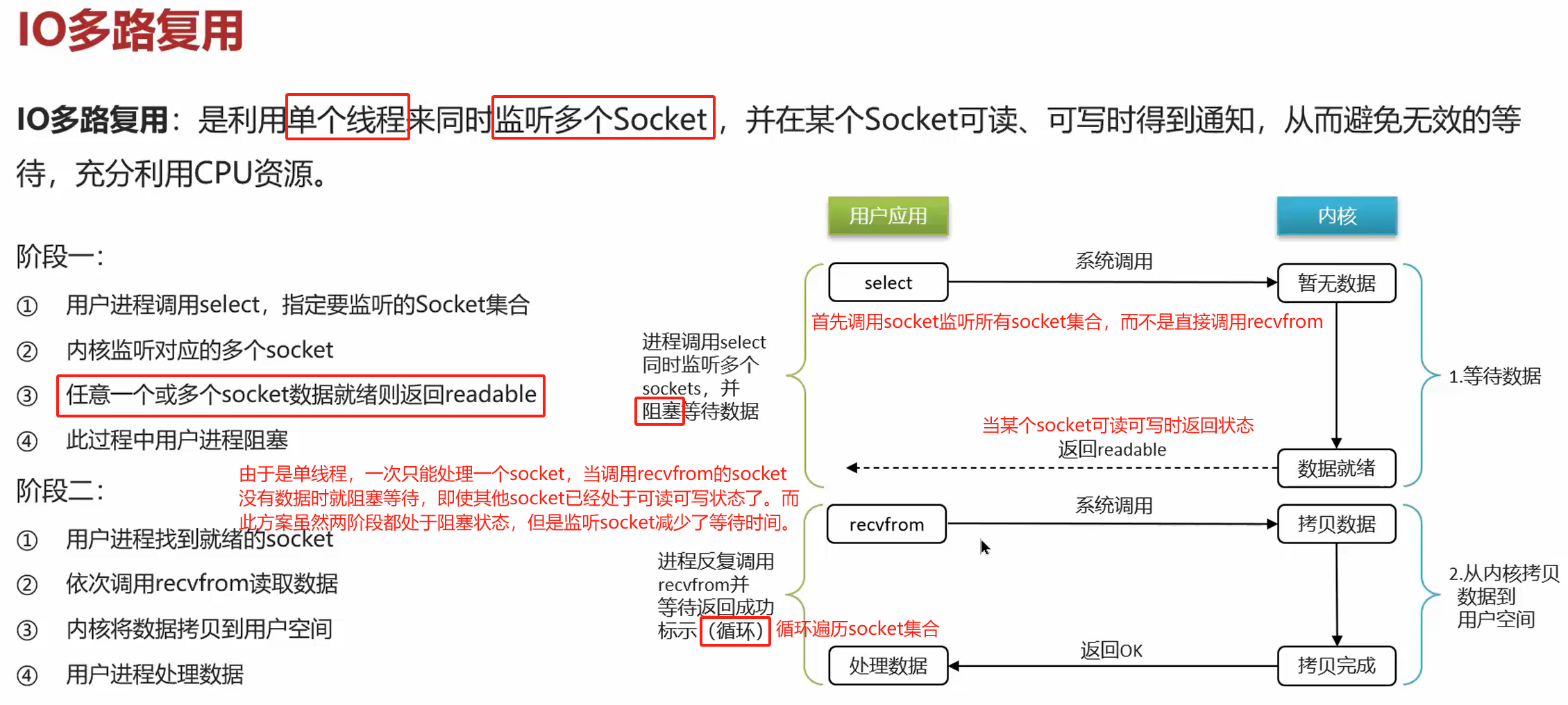
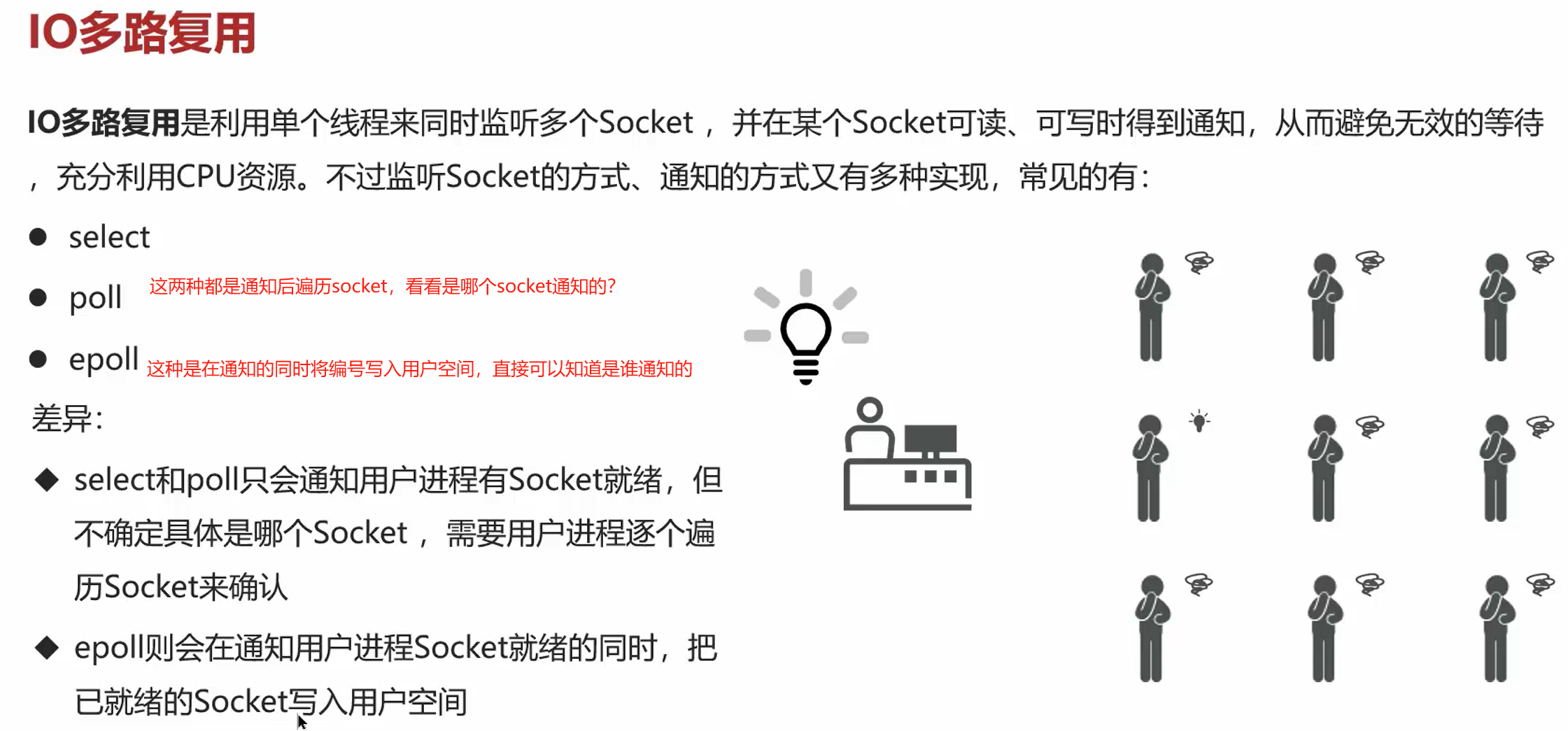
- 减少无效等待;
- 减少用户空间与内核空间的数据拷贝
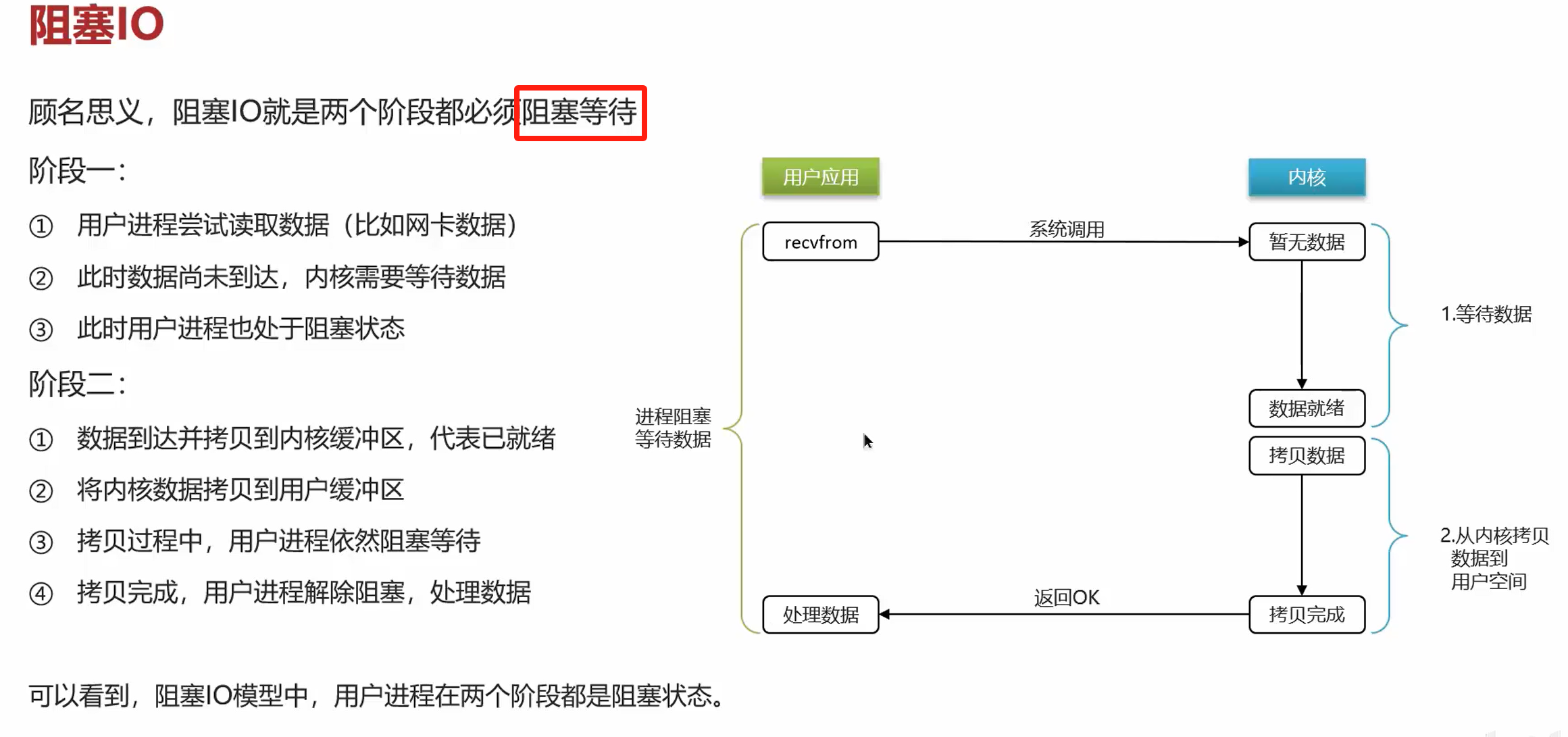
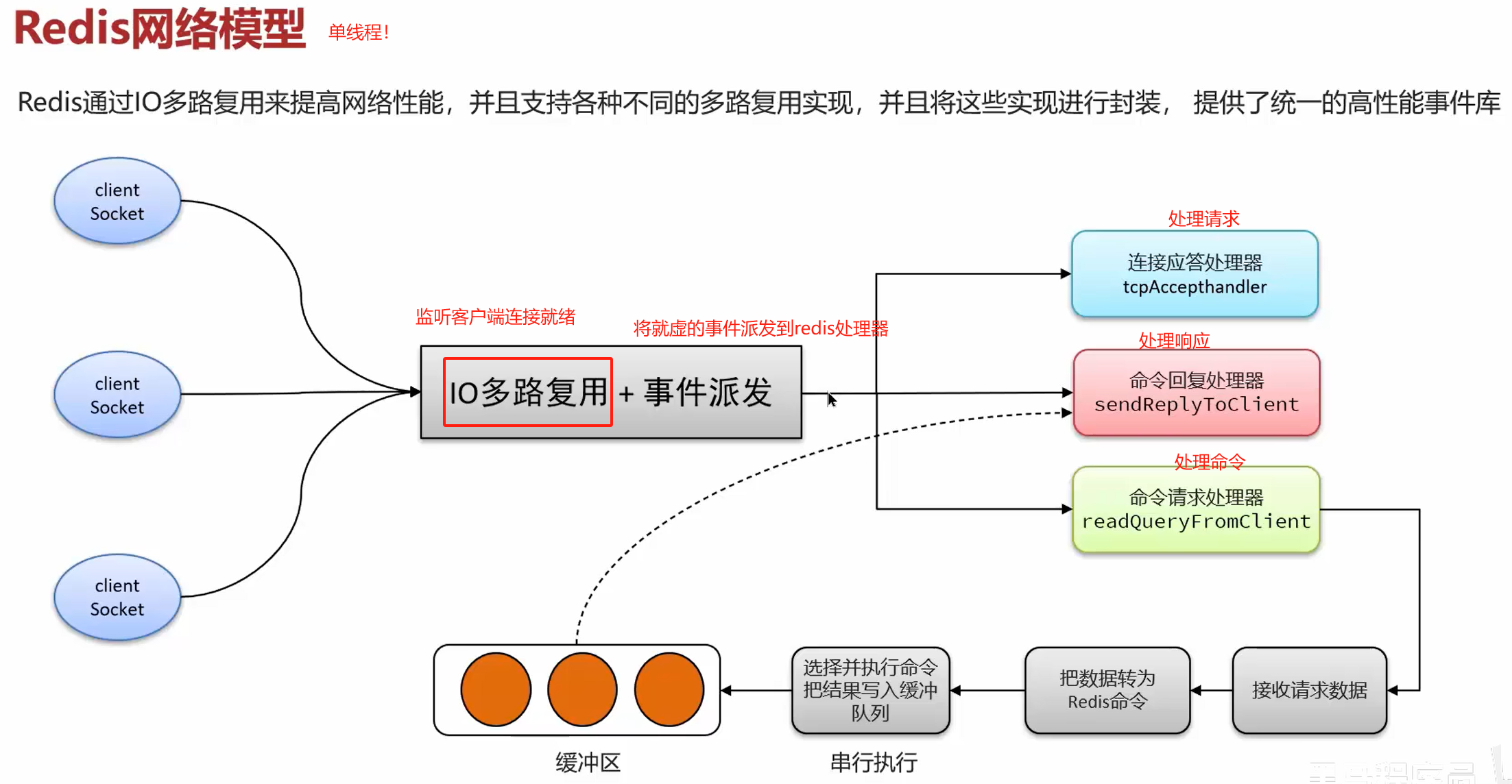
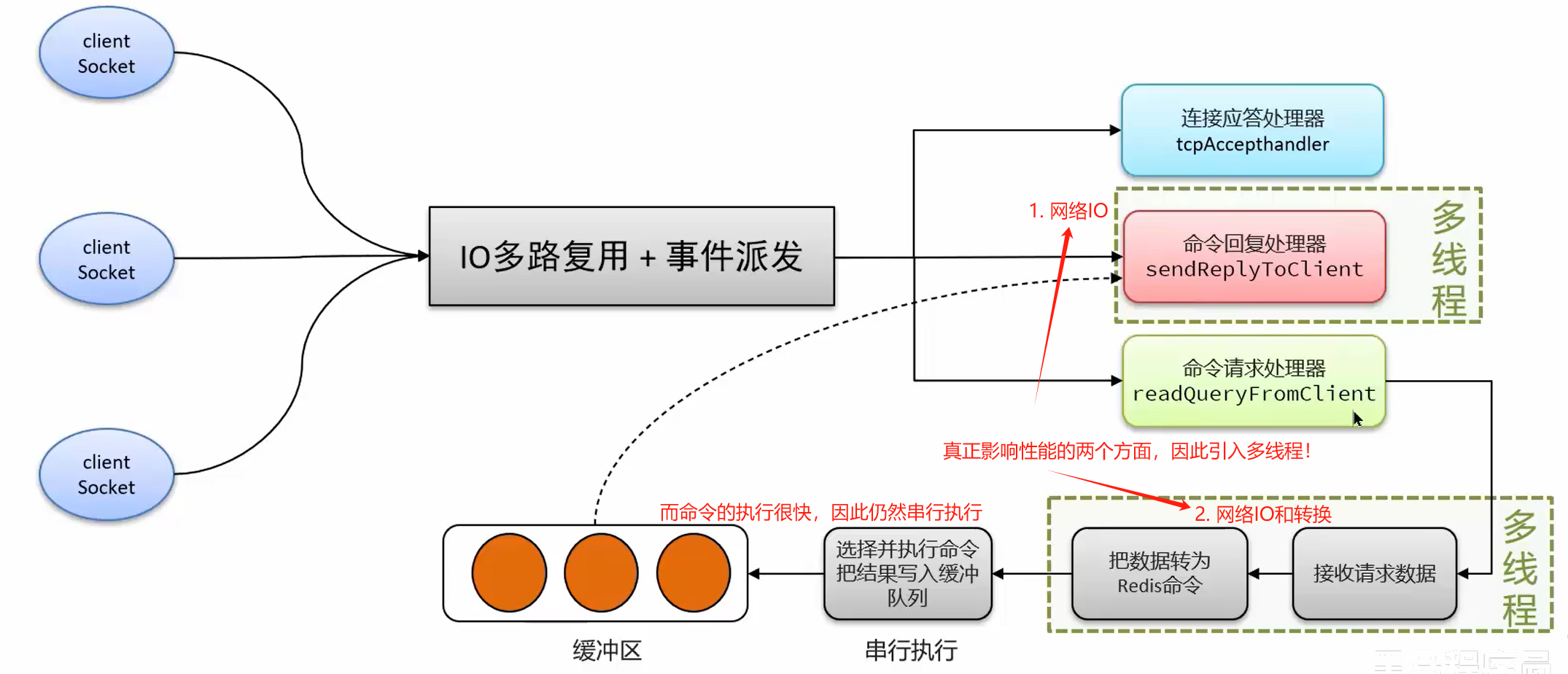
单线程模型下,真正影响性能的并不是IO多路复用的监听机制,也不是命令的执行,而是网络IO!
因此在命令解析(接受请求数据–>转为redis指令)和命令回复处理器引入了多线程。但是在命令执行时仍然是串行处理。


















 5738
5738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









