







 本文介绍了使用Prometheus和Grafana进行前端业务性能指标监控的必要性,详细讲解了Prometheus的工作流程、时序数据库的优势、数据类型,以及Grafana的自定义图表配置和告警功能。通过Prometheus采集指标,Grafana进行可视化,形成有效的监控和告警系统,确保服务稳定性和效率。
本文介绍了使用Prometheus和Grafana进行前端业务性能指标监控的必要性,详细讲解了Prometheus的工作流程、时序数据库的优势、数据类型,以及Grafana的自定义图表配置和告警功能。通过Prometheus采集指标,Grafana进行可视化,形成有效的监控和告警系统,确保服务稳定性和效率。
为什么需要指标监控告警
一个复杂的应用,往往由很多个模块组成,而且往往会存在各种各样奇奇怪怪的使用场景,谁也不能保证自己维护的服务永远不会出问题,等用户投诉才发现问题再去处理问题就为时已晚,损失已无法挽回。
所以,通过数据指标来衡量一个服务的稳定性和处理效率,是否正常运作,监控指标曲线的状态,指标出现异常时及时主动告警,这一套工具就十分重要。
常见的一些指标,包括但不限于:
- QPS
- 请求处理耗时
- 进程占用内存
- 进程占用CPU
- golang 服务的 goroutine
- nodejs 的 event loop lag
- 前端应用的 Performance 耗时
- …
举个例子,假如一个服务:
- 使用内存随着时间逐渐上涨
- CPU 占用越来越高
- 请求耗时越来越高,请求成功率下降
- 磁盘空间频频被挤爆
一旦服务存在某些缺陷导致这些问题,通过服务日志,很难直观快速地察觉到这些指标的变化波动。
通过监控和告警手段可以有效地覆盖了「发现」和「定位」问题,从而更有效率地排查和解决问题。
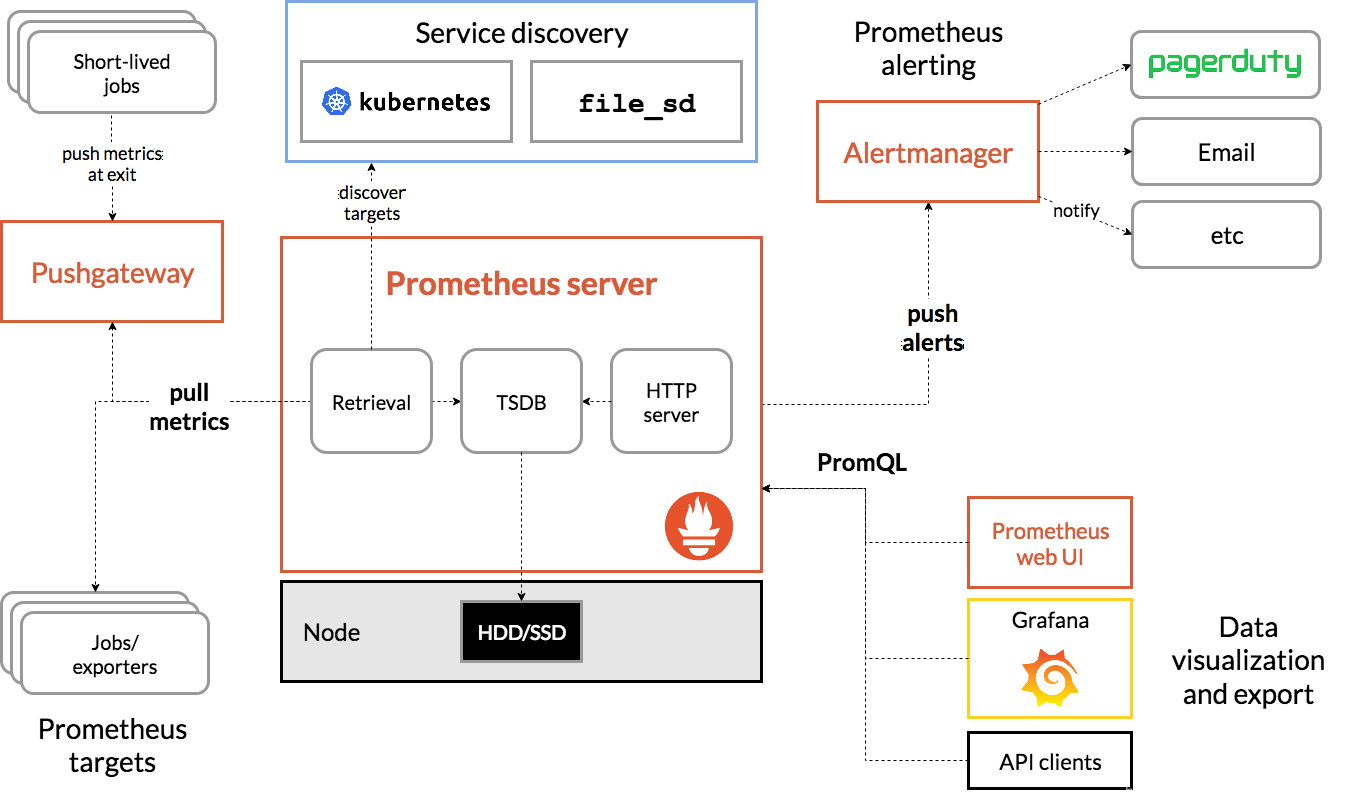
指标监控系统:Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。
工作流可以简化为:
- client 采集当前 机器/服务/进程 的状态等相关指标数据
- Prometheus server 按一定的时间周期主动拉取 client 的指标数据,并存储到时序数据库中
- 发现指标异常后,通过 alert manager 将告警通知给相关负责人
具体的架构设计如下:
为什么不用 mysql 存储?
Prometheus 用的是自己设计的时序数据库(TSDB),那么为什么不用我们更加熟悉,更加常用的 mysql, 或者其他关系型数据库呢?
假设需要监控 WebServerA 每个API的请求量为例,需要监控的维度包括:服务名(job)、实例IP(instance)、API名(handler)、方法(method)、返回码(code)、请求量(value)。

如果以SQL为例,演示常见的查询操作:
# 查询 method=put 且 code=200 的请求量
SELECT * from http_requests_total WHERE code=”200” AND method=”put” AND created_at BETWEEN 1495435700 AND 1495435710;
# 查询 handler=prometheus 且 method=post 的请求量
SELECT * from http_requests_total WHERE handler=”prometheus” AND method=”post” AND created_at BETWEEN 1495435700 AND 1495435710;
# 查询 instance=10.59.8.110 且 handler 以 query 开头 的请求量
SELECT * from http_requests_total WHERE handler=”query” AND instance=”10.59.8.110” AND created_at BETWEEN 1495435700 AND 1495435710;
通过以上示例可以看出,在常用查询和统计方面,日常监控多用于根据监控的维度进行查询与时间进行组合查询。如果监控100个服务,平均每个服务部署10个实例,每个服务有20个API,4个方法,30秒收集一次数据,保留60天。那么总
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









