




1.Hive简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并 提供类 SQL 查询功能。
其实Hive就是将我们的类似SQL(HQL)语句转换成MapReduce程序的工具。
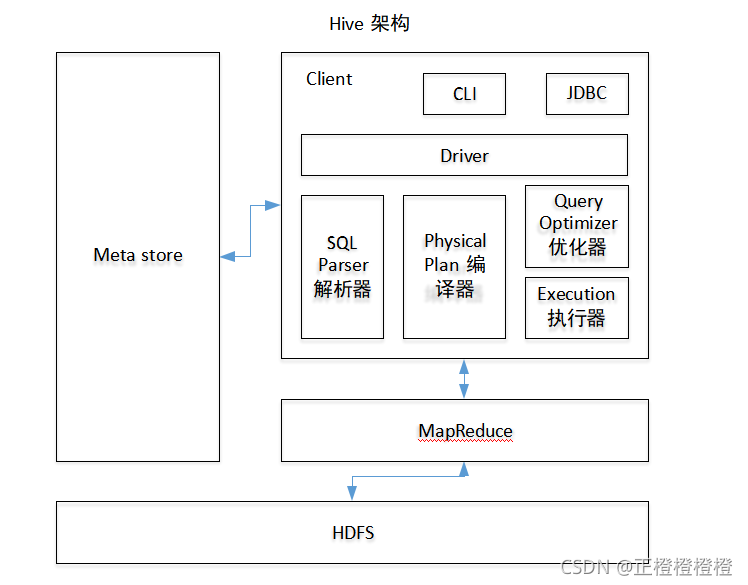
- Cli 用户接口(JDBC等)
- Metastore元数据:存储表名,表存在的数据库,表的拥有者等表的信息。、
- 使用HDFS存储,使用MapReduce计算
- Driver分为四步:解析器将SQL语句转化成抽象语法树AST。通过编译器将AST生成逻辑执行计划。优化器对计划极性优化。执行器将计划转化成物理计划。对于Hive而言就是MR/Spark
2.Hive与数据库的区别
Hive是为数据仓库设计的,是用于处理历史数据,而不是实时的业务数据。
Hive由于针对数仓,数仓的读多写少。因此,存储的数据都是已经确定的。
Hive查询数据慢,因为没有索引。其次,由于Hive基于MR,所以我们的数据量在足够大的情况下,Hive的并行计算才能体现出优势。
Hive搭配Mysql,Hive是不会在Mysql里存储原始数据的。会在Mysql里存储这些原始数据的路径或者一些信息(即元数据)。这些原始数据是会存储在HDFS中的。
3.Hive安装
(安装Mysql,准备好mysql-connector-java-5.1.37-bin,并且将Mysql里的权限给足)
选择mysql而不用默认的derby是因为mysql是支持多用户访问的。
从Apache上下载最新的apache-hive-3.1.2-bin.tar.gz
传到合适的目录,解压。
配置Hive环境变量
export HIVE_HOME=/export/servers/hive
export PATH=$PATH:$HIVE_HOME/bin解决日志jar包冲突
将hive/lib目录下的log4j-slf4j-impl-2.10.0.jar 重命名为log4j-slf4j-impl-2.10.0.bak
将mysql-connector-java-5.1.37-bin复制到Hive的lib目录下。
配置Metastore到Mysql(配置hive-site.xml)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://Hadoop-3:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>自己的mysql密码</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>初始化如果失败,出现:Error: FUNCTION 'NUCLEUS_ASCII' already exists. (state=X0Y68,code=30000)
Hive报错:Error: FUNCTION 'NUCLEUS_ASCII' already exists. (state=X0Y68,code=30000)_Magician的博客-优快云博客
启动Hive
在启动Hive之前,我们需要先初始化元数据库
在对Mysql进行初步处理,创建Metastore,给予足够的用户权限!即可初始化。(遇到问题可查,解决bug的过程也是对这些环境与知识,更好的了解)
补充配置hive-site.xml
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://Hadoop3:9083</value>
</property>
</configuration>初始化元数据
schematool -dbType mysql -initSchema启动Hive的方式:
hive --service metastore;hive使用hiveserver2启动并依赖JDBC连接
在配置中加上(如果不用JDBC就取消)
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>Hadoop3</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>hive --service metastore;
hive --service hiveserver2;
/beeline -u jdbc:hive2://Hadoop3:10000 -n rootHive的使用
多数命令与Sql一致。适度复习一遍sql即可。语法基本一致。只不过Hive的特殊性,其本身就是一个将类sql语言转换成MR程序的一个组件。所以在数据量小时,其处理的速度慢。
在学习的路上,遇到了很多的困难,但是只要坚持下去,一点点去改进,找bug,查看日志,找到解决的方案,这对于提升自己的工程素养也是很有意义的。


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









