







 博客介绍了分类中的ROC曲线和AUC指标。ROC曲线展示分类模型在所有分类阈值下的性能,绘制真阳性率和假阳性率。AUC计算ROC曲线下的面积,综合衡量所有可能分类阈值的效果,具有不受尺度和分类阈值影响的优点,但在某些场合其使用会受到限制。
博客介绍了分类中的ROC曲线和AUC指标。ROC曲线展示分类模型在所有分类阈值下的性能,绘制真阳性率和假阳性率。AUC计算ROC曲线下的面积,综合衡量所有可能分类阈值的效果,具有不受尺度和分类阈值影响的优点,但在某些场合其使用会受到限制。
Classification: ROC curve and AUC
参考
[1] https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc
ROC curve
An ROC curve(receiver operating characteristic curve) is a graph showing the performance of a classification model at all classification thresholds. This curve plots two parameters.
- True positive rate
- False positive rate
True Positive Rate(TPR)
TPR is a synonym(同义词) for recall and is therefore defined as follows:
T
P
R
=
T
P
T
P
+
F
N
T P R=\frac{T P}{T P+F N}
TPR=TP+FNTP
False Positive Rate(FPR) is defined as follows:
F
P
R
=
F
P
F
P
+
T
N
F P R=\frac{F P}{F P+T N}
FPR=FP+TNFP
An ROC curve plots TPR vs. FPR at different classification thresholds. Lowering the classification threshold classifies more items as positive, thus increasing both False Positives and True Positives. The following figure shows a typical ROC curve.
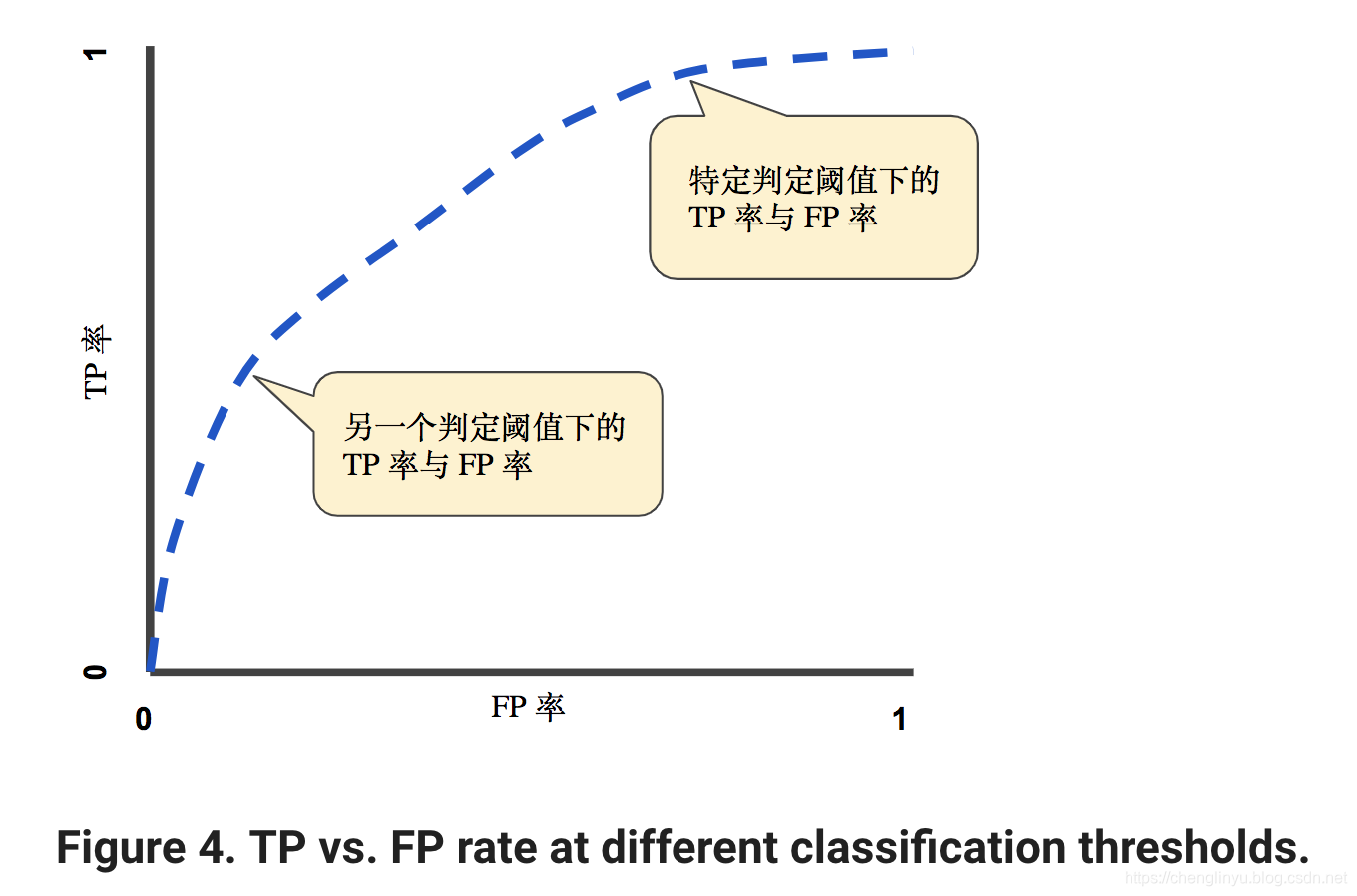
To compute the points in an ROC curve, we could evaluate a logistic regression model many times with different classification thresholds, but this would be inefficient.
Fortunately, there’a an efficient, sorting-based algorithm that can provide this information for us, called AUC.
AUC: Area Under the ROC Curve
AUC 计算了在整个ROC曲线(从(0,0)点到(1,1)点)下方的二维区域的面积。(参考积分学)
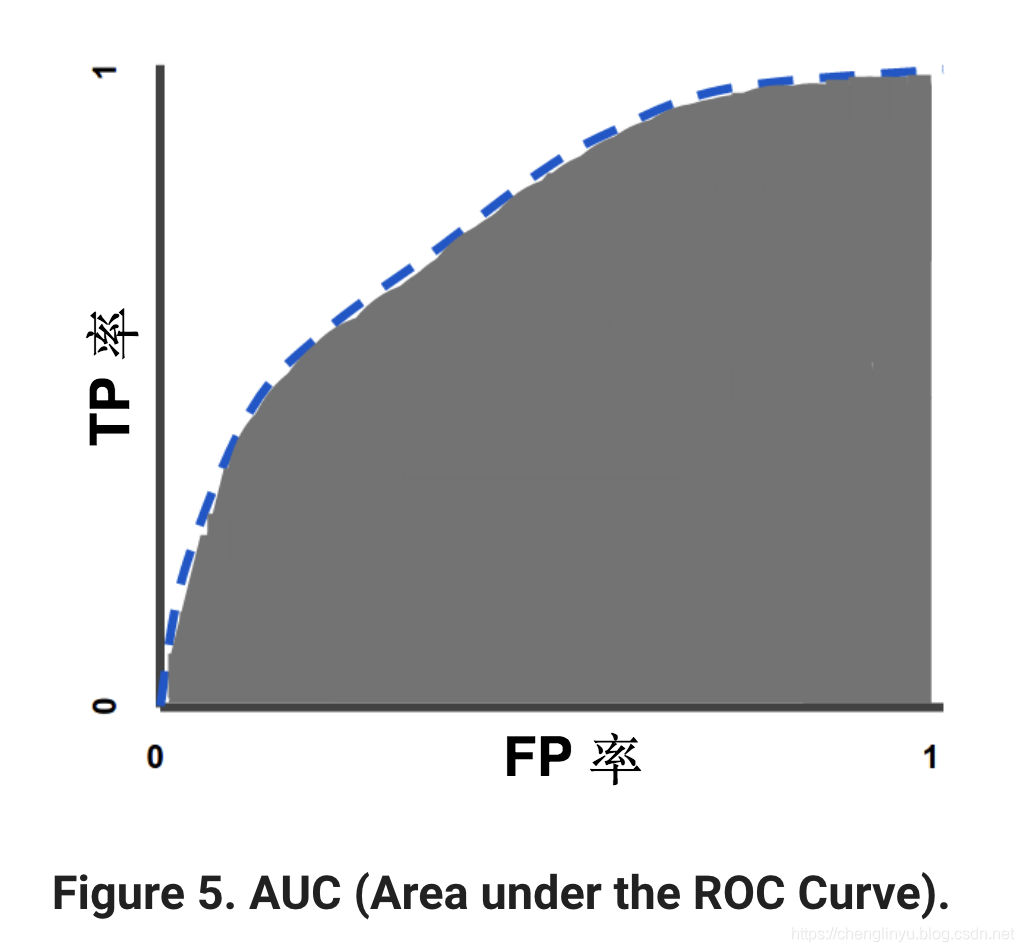
AUC对所有可能的分类阈值的效果进行综合衡量。
One way of interpreting AUC is as the probability that the model ranks a random positive example more highly than a random negative example.
For example, given the following examples, which are arranged from left to right in ascending order of logistic regression predictions:

AUC represents the probability that a random positive (green) example is positioned to the right of a random negative (red) example.
AUC ranges in value from 0 to 1. A model whose predictions are 100% wrong has an AUC of 0.0; one whose predictions are 100% right has an AUC of 1.0.
AUC这个指标受到大家青睐的原因有2个:
-
AUC is scale-invariant(不受尺度影响).
It measures how well predictions are ranked, rather than their absolute values. -
AUC is classification-threshold-invariant.
It measures the quality of the model’s predictions irrespective of what classification threshold is chosen.
AUC度量模型的好坏是不受分类阈值影响的。
然而,这两个原因都受到了一定程度的质疑,这可能在某些场合下限制AUC的使用。
-
Scale invariance is not always desirable.
举个例子,有的时候,我们真的确实需要标准的概率输出,而且AUC并不会告诉我们这件事情。 -
Classification-threshold invariance is not always desirable.
当false negatives和false positives的成本差别很大时,It may be critical to minimize one type of classification error. For example, when doing email spam detection, you likely want to prioritize minimizing false positives (even if that results in a significant increase of false negatives). AUC isn’t a useful metric for this type of optimization.


















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











