




前言
近日闲来无事,一直想着学习LLM、VLM和VLA的内容,把理论和实践走一遍,在最近把LLM和VLM/VLA的综述看完,索性操刀实践一波LLM和VLM的相关项目。这就是这篇LLM的实操记录的缘由。
项目介绍
Minimind 是一个目标在于以最小成本训练LLM的项目,其中包含两种尺寸的模型:0.025b模型和0.1b模型,包括模型的全生态训练:预训练、微调、人类反馈增强、Lora和 R1-zero,以及api部署。以下将对本项目进行实操和测试。
本人在autodl租用了一款32GB服务器,完成了对0.025b模型的训练(预训练、微调、人类反馈增强和 R1-zero)和api部署。模型的结构如下,隐藏层维度为512,transformer layer为8层。
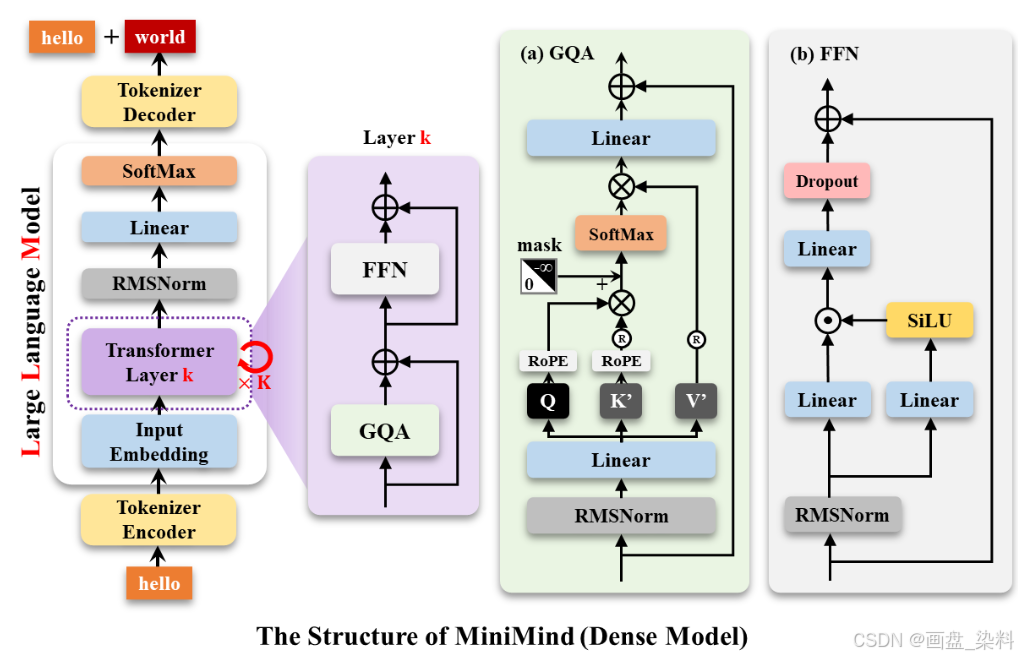
Tokenizer 采用 Minimind作者预训练的minimind-tokenizer,词表大小仅为6,400,以方便在性能预算不足的设备进行精度尚可的快速推理。以下是目前市面上较好的Tokenizer:
| Tokenizer模型 | 大小 | 来源 |
|---|---|---|
| yi tokenizer | 64,000 | 01万物 |
| qwen2 tokenizer | 151,643 | 阿里云 |
| glm tokenizer | 151,329 | 智谱AI |
| mistral tokenizer | 32,000 | Mistral AI |
| llama3 tokenizer | 128,000 | Meta |
| minimind tokenizer | 6,400 | 作者训练 |
Benchmark
以下是对minidmind作者训练的0.1b微调模型的推理测试。


可见效果非常好,足够一般的使用场景。
R1-zero模型
训练全过程
没有使用预训练权重,初始化一个torch模型,0.025b (25MB) ,8层transformer layers和512的隐藏层宽度。依次进行下述流程的训练:
预训练: 在一个1.6G的中文数据集(提取自匠数大模型数据集)上进行训练,4个epoch。该预训练流程用于灌输维基百科类型的事实知识给模型。
数据内容预览:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









