



假设陈述(Hypothesis representation)
在上一篇的最后,我们提到想要解决分类问题,我们想要函数的输出保持在[0,1]里,为了解决这个问题,我们提出一个假设函数:,其中将
函数定义为:如果
是一个实数,那么
,这个函数就叫做sigmoid函数或logistic函数,将其带入到假设函数中,我们会得到:
,而
函数图像如下图所示:
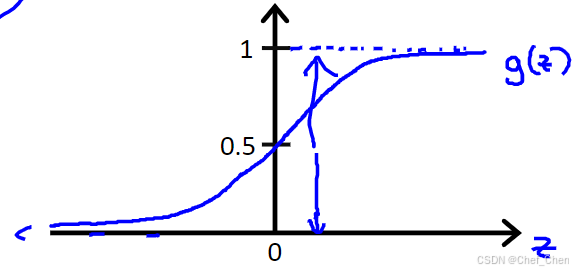
函数图像
如图,我们可以观察到图像是一条过点(0,0.5)的曲线,最重要的是,他有我们想要应用在分类问题上的输出:他的值始终在(0,1)之间。
回到之间所说的肿瘤问题,假设我们将一个特征量x喂给我们的假设函数,即,假设输出是0.7,这就代表输入了这个肿瘤的信息之后,函数告诉我们这个肿瘤有70%的可能性是恶性肿瘤。如果用概率的方式来表达则是
,意思是在给定
的条件下
的概率,概率的参数是
。由于
的值只可能是0或1,所以
。
决策界限(Decision boundary)
对于上面提到的假设函数,我们把其分成两种情况可能以便我们对值进行预测:若
,认为
更有可能偏向1而不是0;反之若
,则认为其更偏向0。但问题的关键在于,什么时候
呢?
从函数的图像我们可以看到,当
,
,也就意味着只要
,就能满足我们所说的
,从而预测
。类似的,当
时,我们也能预测到
。
假设我们有这样一个已经拟合好的数据集,他满足假设函数,拟合后的参数
,那么按照我们上面所说,只要满足
,就能得到
的预测值。也就是说,我们画出训练集的坐标图,以
为分界线,在线的右边便是满足条件的点,而这条线也就被叫做决策边界,如图:
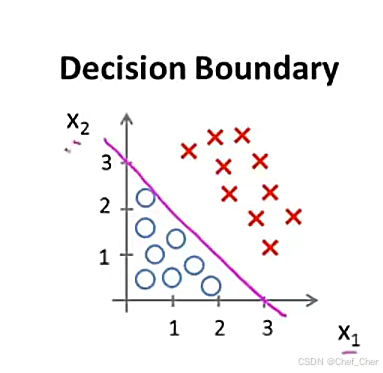
将正负样本通过决策边界划分出来
需要注意的是,决策边界是由假设函数的参数决定的,与数据集本身无关,即使去掉了这些数据点,决策边界以及划分的区域依然存在。
我们接着来看一个更复杂的例子,还是跟之前一样用×代表证样本,圆圈代表负样本,横坐标轴是,纵坐标轴是
,如图:
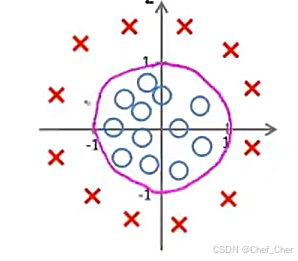
复杂函数的决策边界
其假设函数为,假设我们已经使用某种算法去拟合,得到的参数
,,也就是说当
,预测值
,显然,这个直线的意义便是取圆心为原点,半径为1的圆线上及圆以外的点,其预测值
。
。这个例子告诉我们,通过在假设函数中加入复杂的多项式,我们可以得到更复杂的决策边界,而不只是仅仅用直线分开正负样本。当然,加入更复杂的高阶多项式,得到的决策边界也会长得更加“奇怪”,能够更准确的分开正负样本。
学习内容来自于b站吴恩达大佬课程:https://www.bilibili.com/video/BV1By4y1J7A5?spm_id_from=333.788.player.switch&vd_source=867b8ecbd62561f6cb9b4a83a368f691&p=1

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









