




 本文详细探讨了神经元的三种常见激活函数,如sgn、sigmoid和ReLU。接着,介绍了感知机与多层网络如何构建异或门,并涉及误差逆传播算法,包括BP流程及其控制过拟合的方法。还涵盖了全局与局部最小解的概念,以及RBF网络、ART网络和SOM网络等高级神经网络模型。最后,揭示了深度学习中的参数优化策略和无监督预训练技术。
本文详细探讨了神经元的三种常见激活函数,如sgn、sigmoid和ReLU。接着,介绍了感知机与多层网络如何构建异或门,并涉及误差逆传播算法,包括BP流程及其控制过拟合的方法。还涵盖了全局与局部最小解的概念,以及RBF网络、ART网络和SOM网络等高级神经网络模型。最后,揭示了深度学习中的参数优化策略和无监督预训练技术。
一、神经元Neuron
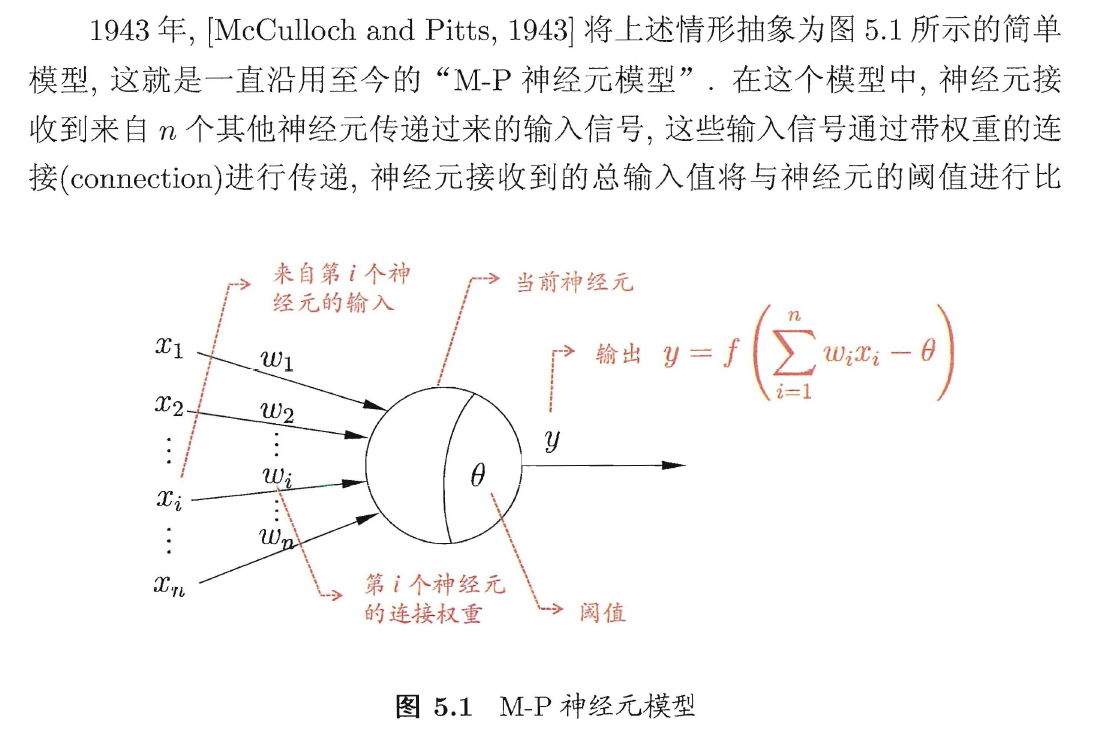
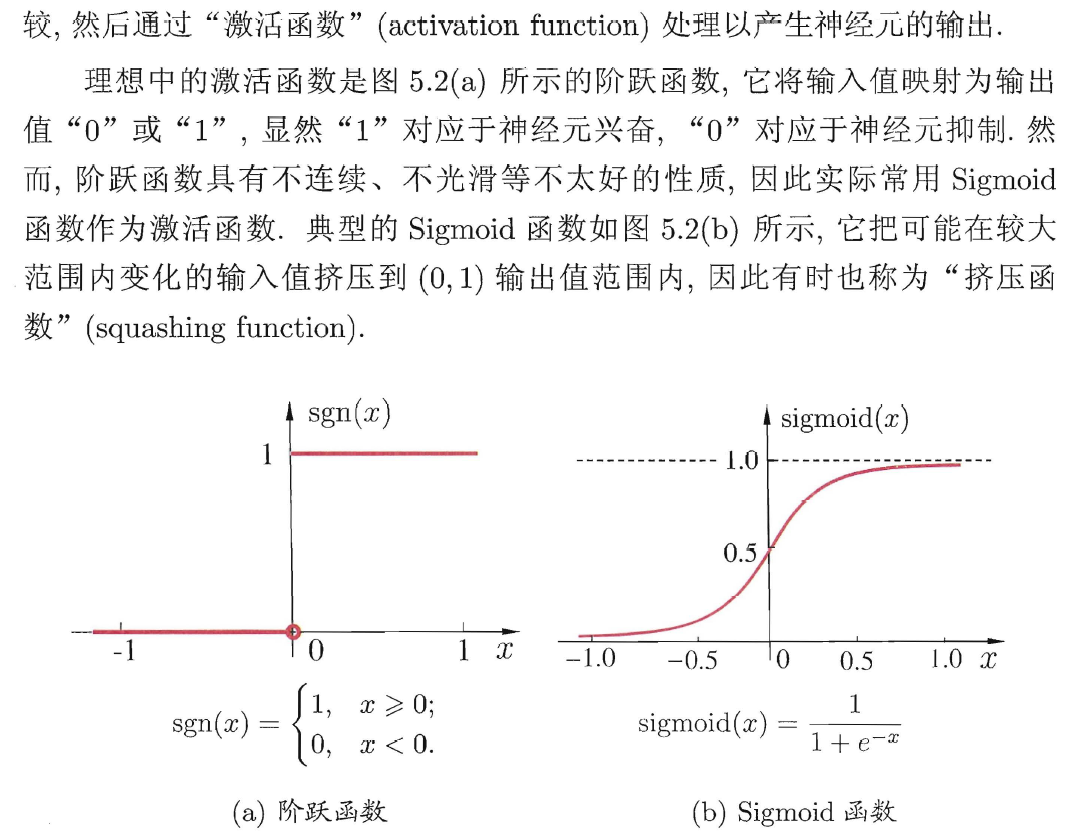
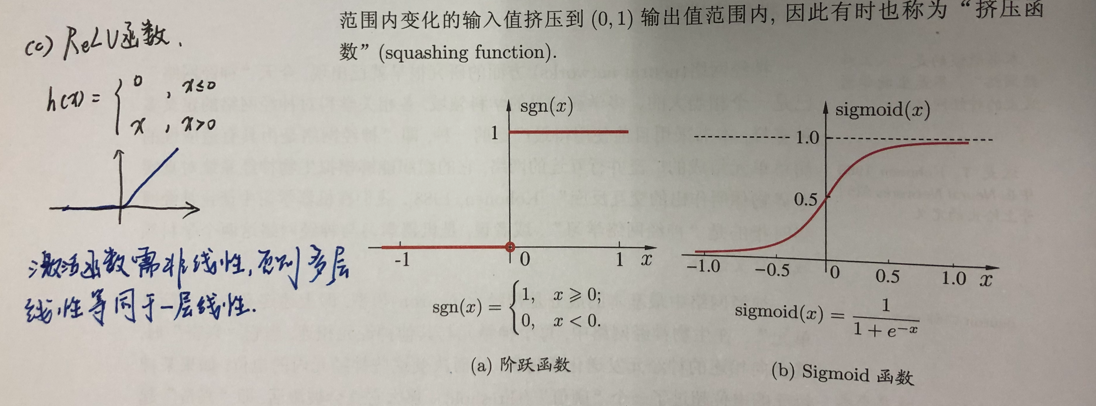
三种常见的激活函数:sgn, sigmoid, ReLU
二、感知机Perceptron与多层网络
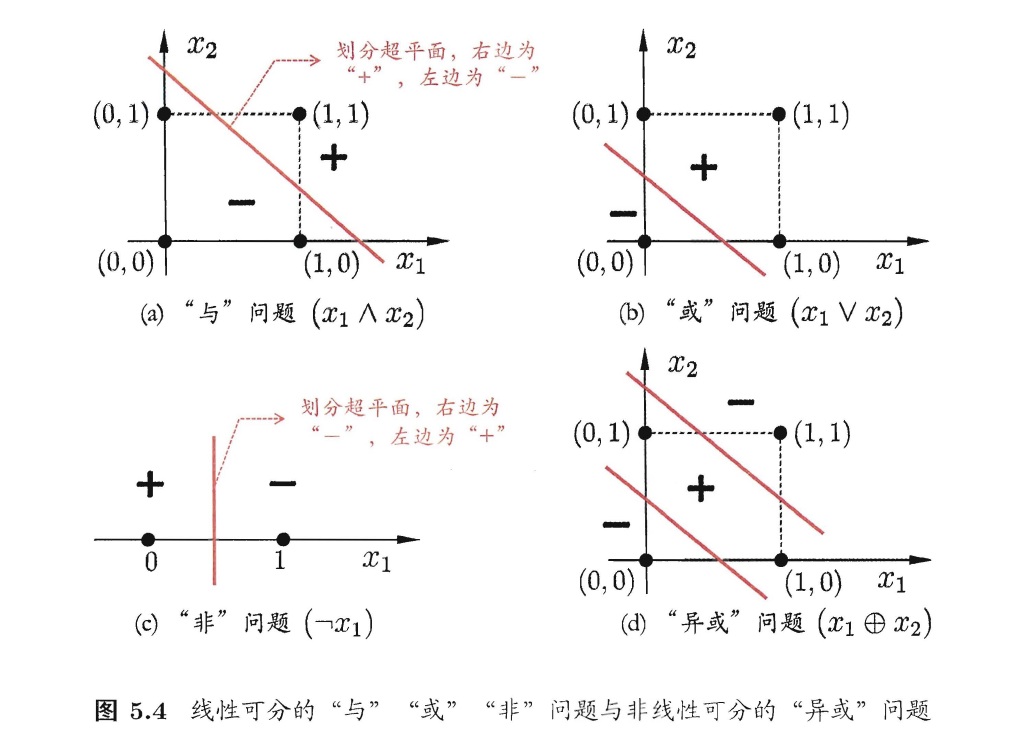
1、与(And),或(Or),与非(Not And),异或(Xor)

2、多层网络构建“异或”门
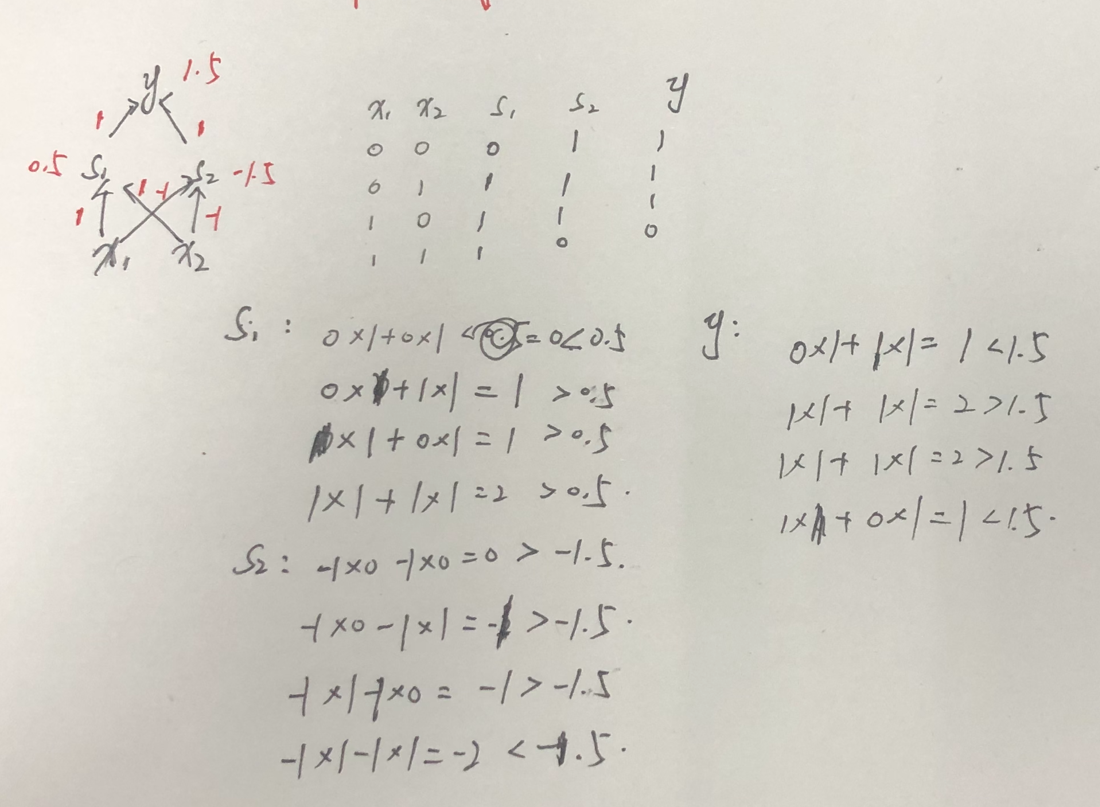
3、将阈值纳入权重

三、误差逆传播算法(error BackPropagation)
1、一个简单的单隐层网络
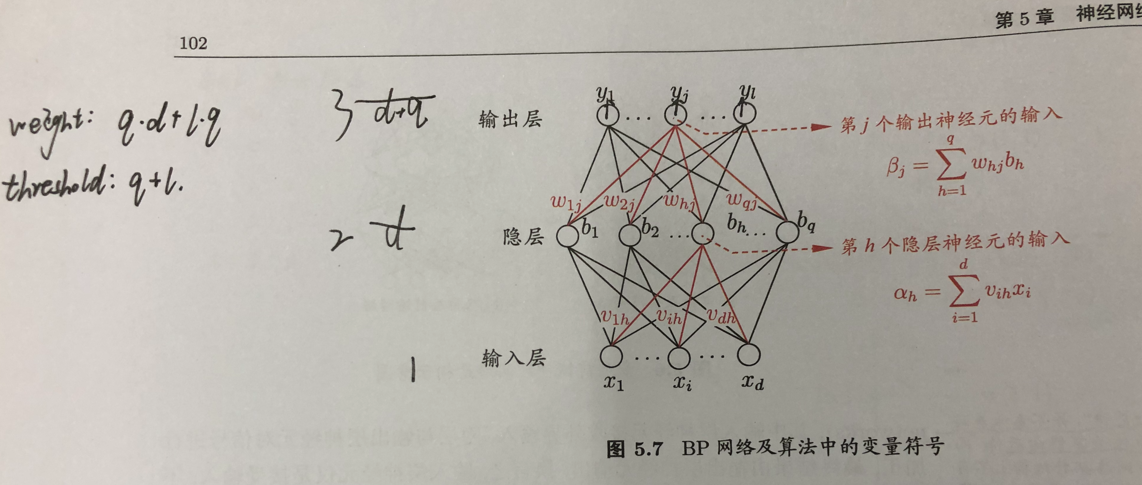
(1)每层每个nodes都有输入以及输出,这个需要谨记;
(2)假设每个神经元都使用sigmoid函数;
(3)输出层的输出可以写为:
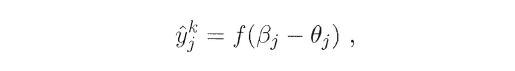
输出层的输入为beta,f即为sigmoid函数,theta为阈值;
(4)得到均方误差:
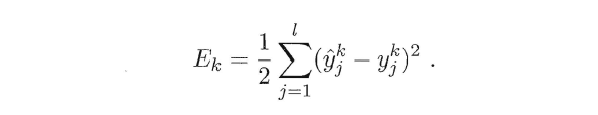
(5)此时该误差为神经网络参数的函数,参数包括(q*d+l*q)个权重以及(q+l)个阈值。调整参数使误差最小:

(6)参数推导

(7)BP流程

2、标准BP算法和累积BP算法
标准BP:针对单个样例;
累积BP:读取整个训练集后才对参数进行更新。
3、两种策略以控制overfitting
(1) early stopping:训练集误差降低但验证集误差升高时停止训练

(2)regularization正则化
https://www.youtube.com/watch?v=KvtGD37Rm5I

四、全局最小与局部最小
1、概念:

2、跳出局部最小:
(1)以多组不同参数值初始化多个神经网络,取其中误差最小的解作为最终参数;
(2)模拟退火(repeated heating and cooling strengthens the blade);
接受次优解
(3)随机梯度下降法:即便陷入局部极小点,其梯度仍不为0(标准梯度下降法为0)。
五、其他常见的神经网络
1、RBF网络 Radial Basis Function
(1)隐层神经元激活函数为“径向基函数”:学习速度快;克服局部最小问题。

(2)隐藏层函数:径向基函数。基函数有多种选择,可以通过优化基函数以优化算法。
其中r为样本x与中心c的距离。![]()

(3)输入的距离越大,函数输出越趋近于0。因此只有中心附近可以被激活。

(4)两步法:

2、ART网络 Adaptive Resonance Theory
(1)属于竞争型学习,网络的输出神经元相互竞争,每一个时刻仅有一个竞争获胜的神经元被激活;
(2)竞争方式:

分类
(3)当识别阈值较高时,输入样本将被分成比较多、比较精细的模式类;如果识别阈值较低,则会产生比较少、比较粗略的模式类。
阈值高时,有更高的概率增设新神经元,形成比较多、精细的模式类。
(4)缓解了竞争性学习中的“可塑性-稳定性窘境”


3、SOM网络 Self-organizing Map自映射网络
(1)竞争型无监督神经网络:将高维输入数据映射到低维空间
(2)输出层获胜神经元
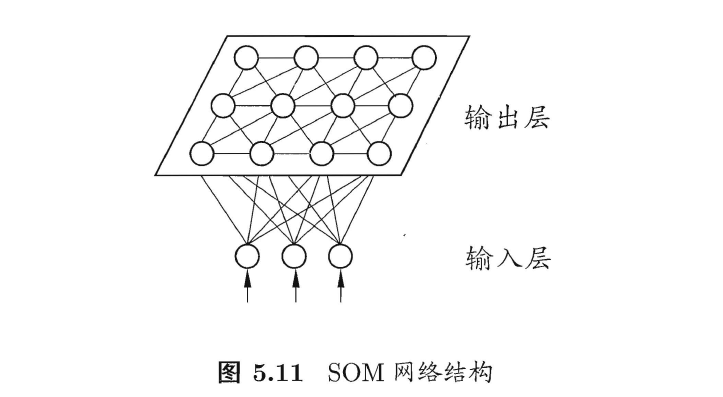 (3)训练过程:选出输出层的最佳匹配单元
(3)训练过程:选出输出层的最佳匹配单元

4、级联相关网络
(1)学习目标不止于连接权和阈值,还包含了网络结构(隐层层数,隐层神经元数量)
(2)两个主要成分:级联、相关
创建层级结构;最大化新神经元的输出与网络误差之间的相关性训练参数。
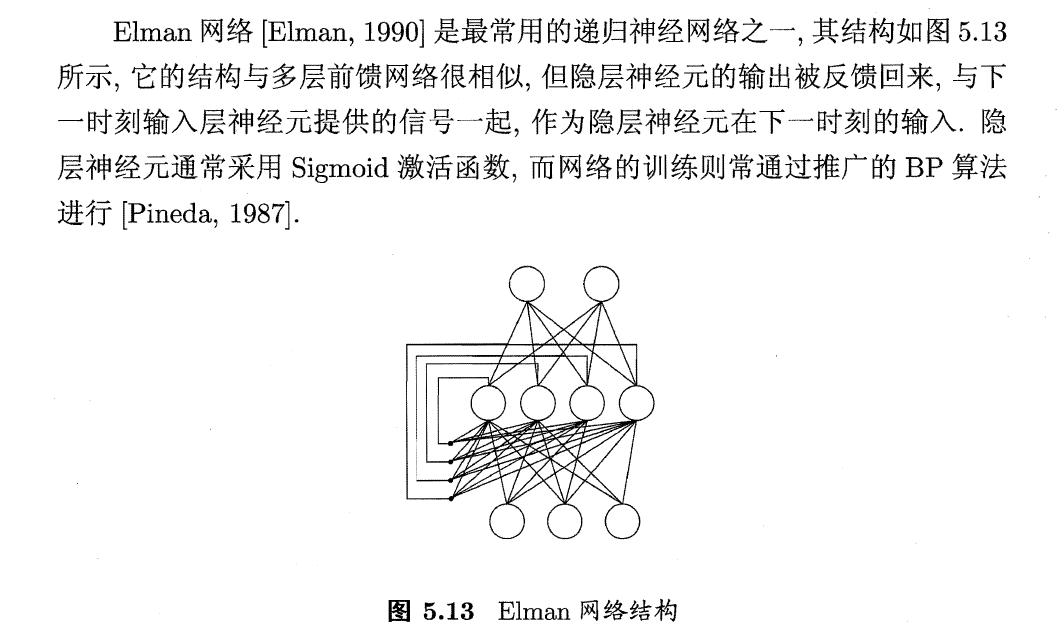
5、Elman网络(输入RNN网络)
(1)递归神经网络:RNN recurrent neural networks允许一些神经元的输出反馈回来作为输入信号

(2)Elman
6、Boltzmann机
(1)训练目标:最小化能量函数;
(2)向量s表示n个神经元状态,如(1,0,0,0,1,0,1);
(3)计算向量s对应的Boltzmann机能量;
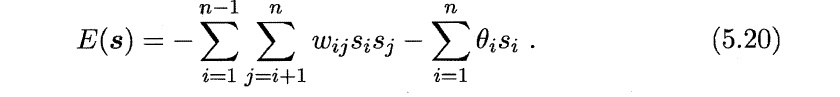
(4)训练过程:将每个训练样本视为一个状态向量,使其出现概率尽可能大

(5)受限Boltzmann
1)"对比散度" (Contrastive Divergence,简称CD)算法进行训练.
2)对每个训练样本u,根据(5.23)计算得隐层神经元状态概率分布,根据该概率分布采样得隐层状态向量h;根据(5.22)由h计算得u1,再根据u1及(5.23)计算得h1,循环往复。

(3)连接权更新公式为:
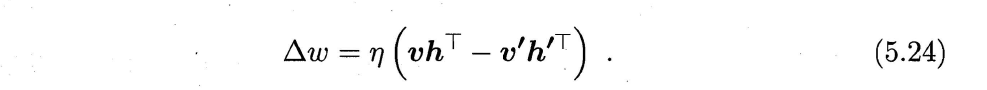
阈值类似获得。
六、深度学习
1、训练数据的大幅增加可以降低过拟合风险。
2、多隐层可以提升神经模型的表现;但多隐层神经网络难以直接用BP算法训练,因为误差在多隐层逆传播时难以收敛。
3、无监督逐层训练(unsupervised layer-wise training)是多隐层网络训练的有效手段:
(1)基本思想:预训练+微调
1)预训练(pre-training):将上一层隐结点的输出作为下一层隐结点的输入
2)微调(fine-tuning)
(2)可以视为:将大量参数分组,对每组找到局部最优;联合局部最优寻找全局最优。
4、权共享(weight sharing)
(1)让一组神经元使用相同的连接权,在卷积神经网络(CNN)起到较大作用;
(2)例子
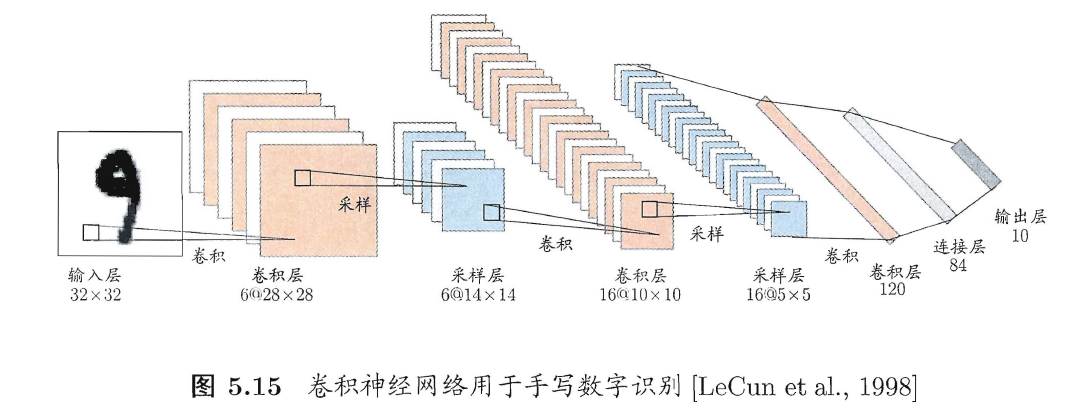
1)第一个卷积层:有6个特征(面),每个特征由28*28的神经元阵列表示,每个神经元从5*5的区域通过卷积滤波器提取局部特征;
2)第一个采样层(亦称汇合层pooling):基于局部相关性进行亚采样,减少数据量且保留有用信息(类似PCA)。第一个卷积层(28*28)2*2计算输出,得到28/2=14*14的采样层。
3)在上图训练中,每个平面的神经元都是用相同的连接权,减少了参数。
5、特征工程
(1)描述样本的特征通常由人类专家设计,这称为“特征工程”。
(2)人类专家设计出好特征并非易事,因此特征学习通过机器学习技术自身产生好的特征,向“全自动数据分析”迈进。


















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









