






1、经验误差与过拟合
(1)error rates错误率: E=a/m
(2)accuracy正确率= 1-E
(3)
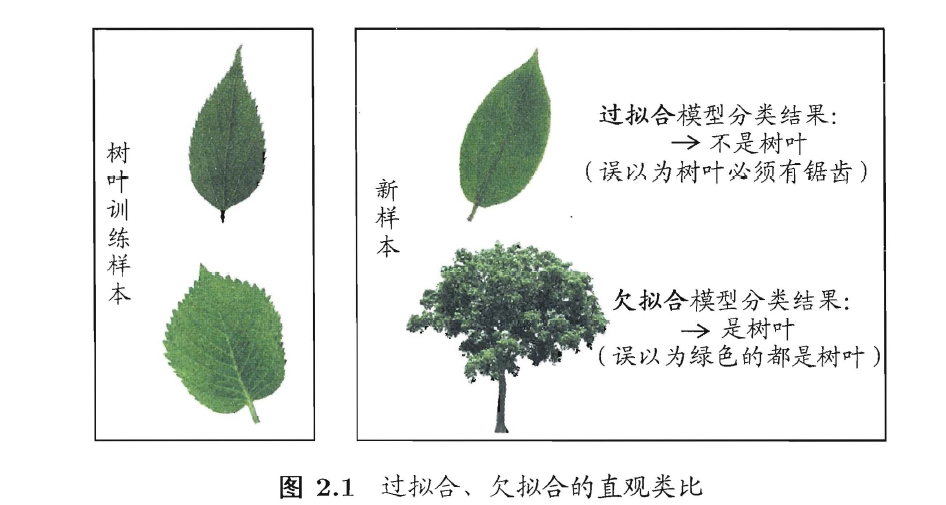
(4)Overfitting and underfitting
2、评估方法
(1)泛化能力:测试集
(2)Split dataset:
留出法:
from sklearn.model_selection import cross_val_score, train_test_split
testing_classes) = train_test_split(all_features, all_classes, train_size=0.75, random_state=1)
#random_state=1, 表示多次split的train和test一致K-fold cross validation:
https://blog.youkuaiyun.com/Checkmate9949/article/details/119785123第三点
自助法Bootstrap:

改变了初始数据集的分布,带来估计偏差。因此当数据集足够时,留出法和交叉验证法更加常用。
(3)Validation set 验证集:为了调参,防止前视偏差。
3、性能度量performance measure
(1)Mean squared error均方误差
对于数据分布D和概率密度函数p(.)

(2)错误率与精度
(3) 查准率、查全率
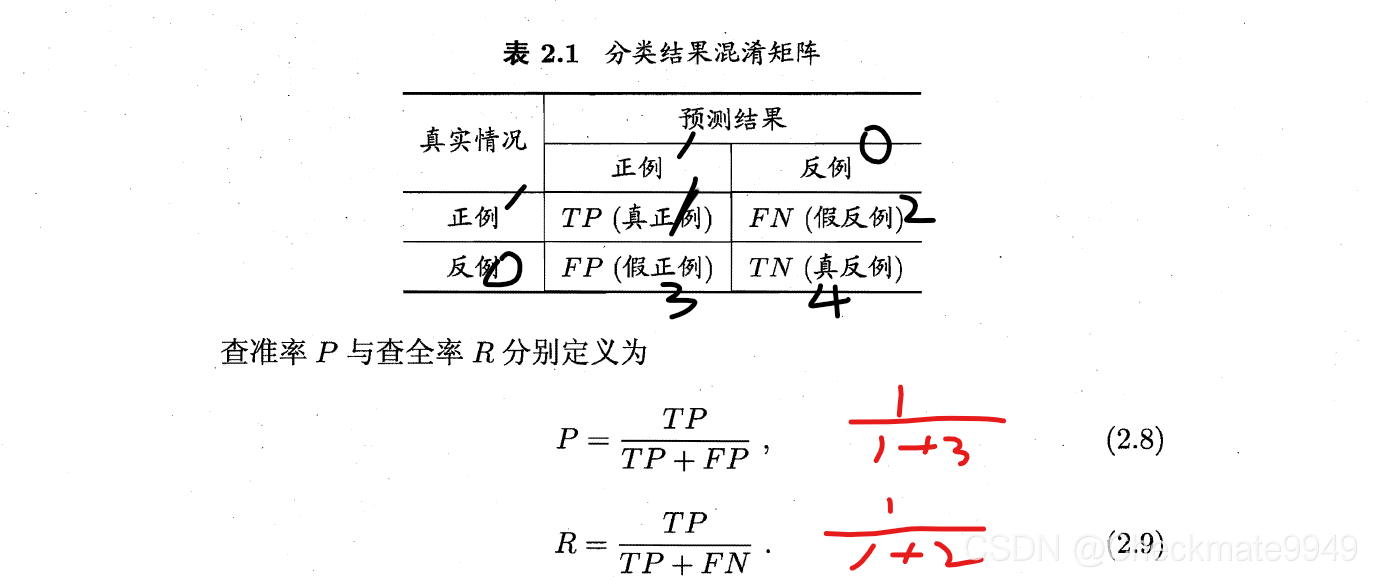
1)混淆矩阵
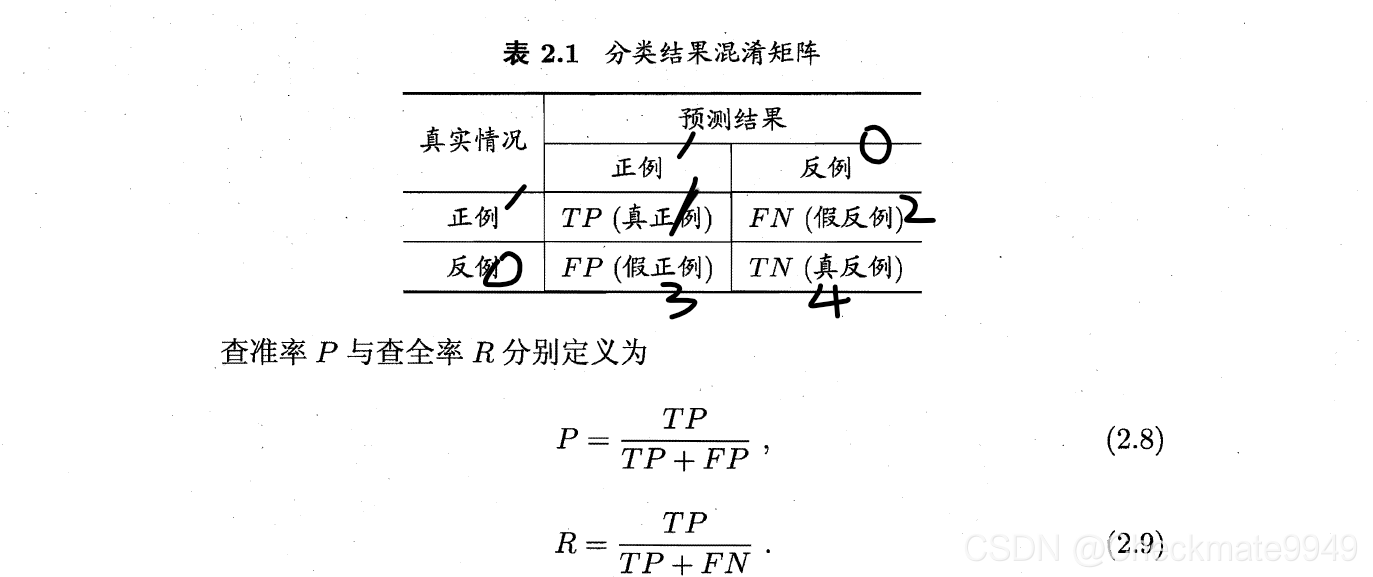
P: 我预测为真的,有多少对的?
R:真的中有多少被预测到的?
2)假阳性:acc失效
(4)P-R曲线:P与R反向变动
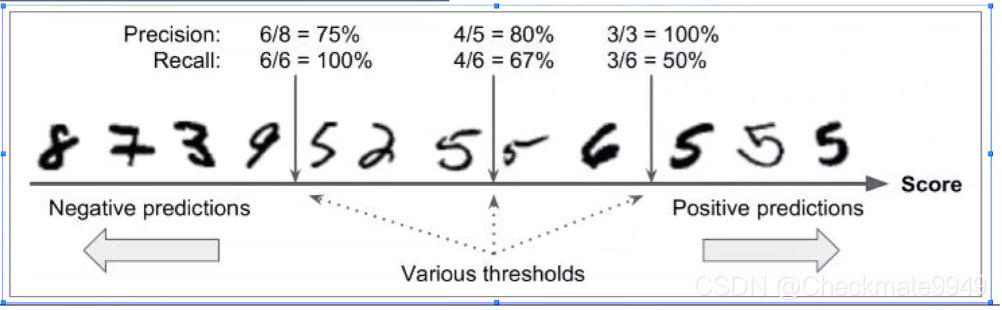
Threshold阈值愈高,标准越高:P高,而R低;阈值越低:P低,而R高
Threshold右边表示预测为5的
(5)综合考虑P与R
1)Break-Even Point: 即P=R时取值
2)F1:P和R的调和平均
(1/P + 1/R) = (TP+TP+FN+FP)/TP,再取倒数体现了TP所占的比例,使P与R的取值更合理。
3)F_beta加权调和平均数:
beta>1,查全率R影响更大;beta<1,查准率P影响更大。
(6)n个二分类实现的多分类问题
1)先分别计算混淆矩阵,再求均值
(P1,R1),(P2,R2),...,(Pn, Rn)
macro_P:
macro_R:
marco_F:
2)先平均,再计算

















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









