






Rossmann Store Sales项目全解析(含修正报错+详细注释+简洁代码)
https://www.kaggle.com/competitions/rossmann-store-sales/
一、项目背景及解决问题的方案
1. 项目背景
Rossmann Store Sales是Kaggle平台经典的结构化数据回归预测项目,Rossmann作为欧洲领先的药品零售连锁企业,拥有数千家线下门店,其运营团队面临核心痛点:无法准确预判各门店未来数周的日销售额。
准确的销售额预测能够直接支撑企业的精细化运营:
- 优化库存管理,避免畅销商品缺货或滞销商品积压;
- 合理安排员工排班,降低人力成本;
- 制定精准的促销策略,提升门店收益;
- 规划现金流,保障企业资金链稳定。
项目提供3个核心数据集(均为CSV格式):
train.csv:训练集,包含各门店历史日销售数据,字段涵盖门店ID、日期、销售额(Sales,目标变量)、顾客数、营业状态、促销状态、节假日标识等;store.csv:门店属性集,包含门店ID、门店类型、商品组合、促销活动详情、竞争门店距离、竞争门店开业时间等;test.csv:测试集,结构与train.csv一致,缺失Sales字段,需通过模型预测填充后提交至Kaggle平台进行评分。
项目核心难点:
- 销售额分布呈强偏态(大量零值对应门店停业,部分高销售额形成极值);
- 数据存在缺失值(如竞争门店距离、促销相关字段);
- 影响因素复杂且相互作用(门店属性、促销活动、节假日、时间趋势等);
- 评估指标特殊(采用RMSPE均方根百分比误差,对相对误差更敏感,更贴合企业实际业务诉求)。
2. 完整解决方案
采用**“数据探索(EDA)→ 数据预处理 → 特征工程 → 模型训练与调优 → 评估与预测”**的端到端闭环流程,具体步骤如下:
- 数据探索(EDA,当前阶段):加载各类数据集、查看数据基本结构(行/列、字段类型)、分析目标变量(
Sales)分布特征、探索关键字段(如Open营业状态)与目标变量的关联性、初步识别缺失值和异常值; - 数据预处理:填充门店属性中的缺失值(如用均值/中位数填充数值型缺失值、用众数填充类别型缺失值)、过滤异常数据(如营业状态为1但销售额为0的异常样本)、日期格式转换(将字符串日期转为
datetime类型)、类别特征初步编码(为后续建模做准备); - 特征工程:衍生核心特征,包括时间特征(年、月、日、星期几、是否周末、是否月末)、门店特征(竞争强度、促销持续时长、门店类型与商品组合的交叉特征)、聚合特征(门店历史7日/30日平均销售额、节假日前后销售额波动);
- 模型训练与调优:选用XGBoost算法(对结构化数据拟合能力强、内置正则化机制抗过拟合、支持缺失值自动处理,是Kaggle竞赛夺冠常用模型)、采用K折交叉验证避免过拟合、通过贝叶斯优化调优超参数(如学习率、树深度、叶子节点数);
- 评估与预测:以RMSPE为核心评估指标,将模型对数变换的预测结果还原为原始销售额空间、整理预测结果为Kaggle要求的提交格式(
Id+Sales)、提交并查看最终评分。
二、项目涉及库及算法的作用与常见用法
1. 核心数据处理库
| 库名 | 核心作用 | 本项目常见用法 |
|---|---|---|
pandas | 结构化数据的读取、清洗、探索、转换、聚合 | pd.read_csv()(读取CSV文件)、df.head()(查看数据前N行)、df['col'].value_counts()(统计字段频次分布)、df[['col1','col2']](筛选指定列) |
numpy | 高性能数值计算、多维数组操作、向量化运算 | np.zeros()(创建指定形状全零数组)、np.sqrt()(求平方根)、np.exp()(指数运算还原对数变换数据)、np.mean()(求平均值)、布尔索引筛选数据 |
2. 日期/文件操作辅助库
| 库名 | 核心作用 | 常见用法 |
|---|---|---|
datetime | 日期字符串转换、日期属性提取、日期运算 | datetime.strptime()(字符串转datetime对象)、dt_obj.year/month(提取年月日)、dt_obj.weekday()(提取星期几) |
csv | 底层CSV文件读写(灵活性高于pandas,备用) | csv.reader()(逐行读取CSV文件)、csv.writer()(逐行写入CSV文件) |
os | 操作系统交互(文件路径处理、文件夹管理) | os.path.join()(拼接跨平台文件路径)、os.path.exists()(判断文件/文件夹是否存在)、os.makedirs()(创建文件夹) |
3. 可视化库:matplotlib
- 核心作用:通过绘制直方图、折线图、散点图等,将数据分布和变量关系可视化,直观辅助EDA分析,避免纯数字分析的局限性;
- 本项目常见用法:
plt.hist(arr, bins=n):绘制直方图,arr为待可视化数组,bins为数据区间数量;plt.subplot(rows, cols, index):创建子图布局,实现多张图表同屏展示;plt.title()/plt.xlabel()/plt.ylabel():设置图表标题和坐标轴标签;plt.tight_layout():自动调整子图间距,避免标题、标签重叠;plt.show():显示绘制完成的图表。
4. 建模与数据预处理库
| 库/模块 | 核心作用 | 常见用法 |
|---|---|---|
xgboost | 极端梯度提升树,构建高精度回归/分类模型 | xgb.DMatrix()(转换数据为XGBoost专用格式)、xgb.train()(训练模型)、xgb.predict()(模型预测)、自定义评估函数适配 |
sklearn.preprocessing.StandardScaler | 数值特征标准化(转换为均值0、方差1) | scaler.fit_transform(X_train)(训练集拟合并标准化)、scaler.transform(X_test)(测试集复用标准化规则) |
sklearn.preprocessing.LabelEncoder | 无序类别特征编码(字符串/标签转为连续整数) | le.fit_transform(df['category_col'])(拟合并转换类别特征)、le.inverse_transform()(还原编码结果) |
sklearn.model_selection | 数据划分、交叉验证、模型评估 | train_test_split()(划分训练/测试集)、cross_val_score()(K折交叉验证)、GridSearchCV(网格搜索调参) |
5. 辅助工具库
| 库名 | 核心作用 | 本项目常见用法 |
|---|---|---|
warnings | 控制程序运行过程中的警告信息输出 | warnings.filterwarnings("ignore")(忽略所有无关警告,避免输出混乱影响分析) |
scipy | 科学计算补充(统计分析、优化算法、插值) | 暂未深入使用,后续可用于缺失值插值、统计检验(如正态性检验) |
itertools | 迭代器工具库,生成各类迭代器 | 暂未使用,后续可用于特征组合(如门店类型与促销状态的交叉组合) |
operator | 运算符工具库,简化排序、比较等操作 | 暂未使用,后续可用于模型结果排序、特征重要性排序 |
6. 核心算法与评估指标
- 核心算法:XGBoost(极端梯度提升树)
优势:基于梯度提升决策树(GBDT)优化,自动捕捉非线性特征关系、内置L1/L2正则化机制防过拟合、支持缺失值自动处理、训练速度快且可并行化、对异常值不敏感,非常适合结构化数据的回归预测任务,是Kaggle竞赛中结构化数据项目的"标配"算法。 - 核心评估指标:RMSPE(均方根百分比误差)
计算公式:RMSPE=1n∑i=1n(yi−y^iyi)2RMSPE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(\frac{y_i - \hat{y}_i}{y_i})^2}RMSPE=n1∑i=1n(yiyi−y^i)2(yiy_iyi为真实销售额,y^i\hat{y}_iy^i为预测销售额)
适用场景:针对存在零值和极值的销售额预测任务,惩罚相对误差而非绝对误差,避免大销售额门店的绝对误差掩盖小销售额门店的相对误差,更贴合企业实际业务的评估诉求。
三、详细注释版代码(修正报错+中文说明+适配代码薄弱者)
# ====================================== 导入所需库(修正matplotlib报错) ======================================
# pandas:结构化数据处理核心库,用于读取、探索、清洗数据
import pandas as pd
# datetime:用于处理日期时间数据,提取年、月、日等属性
import datetime
# csv:底层CSV文件读写工具(本项目主要用pandas.read_csv,此库为备用)
import csv
# numpy:高性能数值计算库,支持数组操作、向量化运算
import numpy as np
# os:操作系统交互库,用于处理文件路径、文件夹管理
import os
# scipy:科学计算补充库,提供统计分析、优化算法等功能
import scipy as sp
# xgboost:极端梯度提升树库,用于构建高精度回归预测模型
import xgboost as xgb
# itertools:迭代器工具库,用于生成特征组合、循环迭代(本项目暂未使用)
import itertools
# operator:运算符工具库,用于排序、比较等操作(本项目暂未使用)
import operator
# warnings:警告信息控制库,用于忽略无关警告,避免输出混乱
import warnings
# 从matplotlib.pyplot导入subplot,用于创建子图布局
from matplotlib.pyplot import subplot
# 忽略所有运行时警告(如数据类型转换、缺失值提示等),避免输出混乱
warnings.filterwarnings("ignore")
# sklearn.preprocessing:数据预处理模块
from sklearn.preprocessing import StandardScaler, LabelEncoder # 分别用于数值特征标准化、类别特征编码
from sklearn.base import TransformerMixin # 自定义数据转换器的基类(本项目暂未使用)
from sklearn import model_selection # 模型选择与交叉验证模块,后续用于数据划分和模型评估
# matplotlib:数据可视化库,修正报错:导入pyplot子模块(而非matplotlib主模块)
# 理由:matplotlib主模块无hist()等可视化函数,可视化功能均封装在pyplot子模块中
from matplotlib import pylab as plt
import matplotlib.pyplot as pltt # 修正:实际导入的是matplotlib.pyplot,具备hist()等功能
# ====================================== 配置matplotlib中文显示(解决中文方框问题) ======================================
# 配置plt的中文显示,使用黑体字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体,解决中文显示为方框的问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号"-"显示为方框的问题
# 配置pltt的中文显示,与plt保持一致
pltt.rcParams['font.sans-serif'] = ['SimHei']
pltt.rcParams['axes.unicode_minus'] = False
# ====================================== 定义全局变量 ======================================
# plot:是否开启数据可视化(True=开启,False=关闭,关闭后不绘制直方图)
plot = True
# goal:目标变量名称,本项目需预测的核心指标是门店销售额(Sales)
goal = 'Sales'
# myid:测试集提交时的唯一标识列名称,Kaggle要求提交结果包含Id和对应的Sales预测值
myid = 'Id'
# ====================================== 定义自定义评估指标相关函数(核心:RMSPE) ======================================
def ToWeight(y):
"""
函数功能:为计算RMSPE构建权重数组,对非零销售额样本赋予权重,避免零值分母报错
参数说明:
y:numpy数组,输入的真实销售额数据(一维或多维数组均可)
返回值:
w:numpy数组,与y形状完全一致的权重数组,零值样本权重为0,非零值样本权重为1/(y^2)
核心逻辑:
1. RMSPE计算中涉及(真实值-预测值)/真实值的平方,若真实值y=0会出现除以零错误
2. 因此将零值样本的权重设为0,使其不参与后续的加权平均值计算,规避报错
3. 非零值样本权重设为1/(y^2),符合RMSPE的计算公式要求
"""
# 创建与输入数组y形状一致的全零数组,数据类型指定为浮点型(确保后续除法运算精度)
w = np.zeros(y.shape, dtype=float)
# 生成布尔索引数组,筛选出y中所有非零值的位置(True表示非零,False表示零值)
ind = y != 0
# 对非零值样本赋予权重:1除以(y的平方),赋值到权重数组w对应的位置
w[ind] = 1. / (y[ind] ** 2)
# 返回构建完成的权重数组
return w
def rmspe(yhat, y):
"""
函数功能:计算均方根百分比误差(RMSPE),评估模型预测效果(适用于普通numpy数组输入)
参数说明:
yhat:numpy数组,模型输出的预测销售额数据
y:numpy数组,真实的门店销售额数据(与yhat形状需完全一致)
返回值:
rmspe:浮点型数值,计算得到的RMSPE评估指标值,值越小说明模型预测精度越高
核心逻辑:
1. 调用ToWeight()函数获取权重数组,规避零值分母报错
2. 计算真实值与预测值的差值,然后求平方(消除正负误差抵消的问题)
3. 将差值平方与对应权重相乘,实现加权计算(突出非零值样本的相对误差)
4. 对加权后的结果求平均值,再开平方根,得到最终的RMSPE值
"""
# 调用ToWeight()函数,获取与真实销售额y对应的权重数组
w = ToWeight(y)
# 按RMSPE公式完成计算:加权差值平方的平均值开平方根
rmspe = np.sqrt(np.mean(w * (y - yhat) ** 2))
# 返回计算得到的RMSPE评估值
return rmspe
def rmspe_xg(yhat, y):
"""
函数功能:适配XGBoost模型的RMSPE计算函数(XGBoost自定义评估函数有固定输入格式要求)
参数说明:
yhat:numpy数组,XGBoost模型输出的预测值(已做对数变换,用于消除数据偏态)
y:XGBoost专用DMatrix格式的标签数据,无法直接使用,需先提取真实标签值
返回值:
"rmspe":字符串,评估指标名称(XGBoost要求自定义评估函数返回"指标名称+指标值"的元组)
rmspe:浮点型数值,将预测值和真实值还原为原始销售额空间后的RMSPE值
核心逻辑:
1. XGBoost模型中,标签数据需通过y.get_label()方法提取,转换为可计算的numpy数组
2. 建模时为消除销售额的强偏态,对目标变量做了对数变换(log(Sales+1)),此处需用np.exp()还原为原始销售额
3. 调用RMSPE的核心计算逻辑,得到符合业务评估要求的指标值,并按XGBoost要求格式返回
"""
# 从XGBoost的DMatrix格式数据中提取真实标签值,转换为numpy数组
y = y.get_label()
# 对数变换还原:将预测值和真实值从对数空间转换回原始销售额空间(exp(x)-1,对应建模时的log(x+1))
y = np.exp(y) - 1
yhat = np.exp(yhat) - 1
# 调用ToWeight()函数,获取权重数组,规避零值分母报错
w = ToWeight(y)
# 按RMSPE公式完成最终计算
rmspe = np.sqrt(np.mean(w * (y - yhat) ** 2))
# 按XGBoost要求的格式返回结果:(指标名称字符串,指标值)
return "rmspe", rmspe
# ====================================== 数据加载与初步探索(EDA核心步骤) ======================================
# 加载门店属性数据集:store.csv,包含门店类型、商品组合、促销信息、竞争门店等关键属性
store = pd.read_csv('./data/store.csv')
# 打印门店数据集前5行数据,直观查看数据结构、字段名称和数据格式(添加中文说明,便于理解)
print("===== 门店属性数据集(store.csv)前5行数据 =====")
print(store.head())
print("\n") # 打印空行,分隔不同输出结果,提升可读性
# 加载训练数据集:train.csv,包含各门店历史日销售额、营业状态、顾客数等核心训练数据
train_df = pd.read_csv('./data/train.csv')
# 打印训练数据集前5行数据,查看核心字段的分布和格式
print("===== 训练数据集(train.csv)前5行数据 =====")
print(train_df.head())
print("\n")
# 统计销售额(Sales)字段的各取值出现频次,分析销售额的分布特征(取前20条,避免输出过长)
print("===== 销售额(Sales)取值频次统计(前20条,展示核心分布) =====")
print(train_df['Sales'].value_counts().head(20))
print("\n")
# 统计营业状态(Open)字段的取值频次,0表示门店停业,1表示门店正常营业
print("===== 营业状态(Open)取值频次统计 =====")
print(train_df['Open'].value_counts())
print("\n")
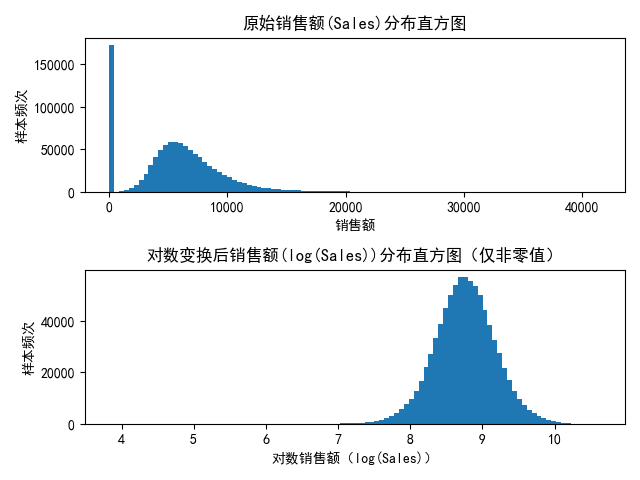
# ====================================== 数据可视化:分析销售额分布特征(修正报错后可正常运行) ======================================
# 判断是否开启可视化,若plot=True则绘制直方图
if plot:
# 创建2行1列的子图布局,实现两张直方图同屏展示,方便对比分析
# 参数说明:2=行数,1=列数,1=当前激活的子图索引(第1个子图)
plt.subplot(2, 1, 1)
# 绘制原始销售额(Sales)的直方图,bins=100表示将数据划分为100个区间,更细致展示分布
pltt.hist(train_df['Sales'], bins=100)
# 设置第1个子图的标题,添加中文说明,便于理解图表含义
pltt.title("原始销售额(Sales)分布直方图")
# 设置第1个子图的x轴标签
pltt.xlabel("销售额")
# 设置第1个子图的y轴标签
pltt.ylabel("样本频次")
# 切换到2行1列布局中的第2个子图(索引为2)
plt.subplot(2, 1, 2)
# 绘制对数变换后销售额的直方图,仅筛选Sales>0的样本(避免log(0)出现无穷大报错)
# np.log():对非零销售额做对数变换,消除数据强偏态,使分布更接近正态分布
pltt.hist(np.log(train_df[train_df['Sales'] > 0]['Sales']), bins=100)
# 设置第2个子图的标题,添加中文说明,明确图表展示的是对数变换后的分布
pltt.title("对数变换后销售额(log(Sales))分布直方图(仅非零值)")
# 设置第2个子图的x轴标签
pltt.xlabel("对数销售额(log(Sales))")
# 设置第2个子图的y轴标签
pltt.ylabel("样本频次")
# 自动调整子图间距,避免标题、坐标轴标签相互重叠,提升图表可读性
pltt.tight_layout()
# 显示绘制完成的所有子图,弹出图表窗口
pltt.show()
# 打印销售额(Sales)与营业状态(Open)的对应数据(前10行),验证停业门店是否销售额为0
print("===== 销售额(Sales)与营业状态(Open)对应数据(前10行) =====")
print(train_df[['Sales', 'Open']].head(10))
print("\n")
# 加载测试数据集:test.csv,用于最终模型预测和Kaggle平台提交
test_df = pd.read_csv('./data/test.csv')
# 打印测试数据集前5行数据,查看测试集的字段结构和格式,确保与训练集一致
print("===== 测试数据集(test.csv)前5行数据 =====")
print(test_df.head())
四、简洁无注释版代码(仅保留核心代码,可直接运行)
import pandas as pd
import datetime
import csv
import numpy as np
import os
import scipy as sp
import xgboost as xgb
import itertools
import operator
import warnings
from matplotlib.pyplot import subplot
warnings.filterwarnings("ignore")
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.base import TransformerMixin
from sklearn import model_selection
from matplotlib import pylab as plt
import matplotlib.pyplot as pltt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
pltt.rcParams['font.sans-serif'] = ['SimHei']
pltt.rcParams['axes.unicode_minus'] = False
plot = True
goal = 'Sales'
myid = 'Id'
def ToWeight(y):
w = np.zeros(y.shape, dtype=float)
ind = y != 0
w[ind] = 1. / (y[ind] ** 2)
return w
def rmspe(yhat, y):
w = ToWeight(y)
rmspe = np.sqrt(np.mean(w * (y - yhat) ** 2))
return rmspe
def rmspe_xg(yhat, y):
y = y.get_label()
y = np.exp(y) - 1
yhat = np.exp(yhat) - 1
w = ToWeight(y)
rmspe = np.sqrt(np.mean(w * (y - yhat) ** 2))
return "rmspe", rmspe
store = pd.read_csv('./data/store.csv')
print("===== 门店属性数据集(store.csv)前5行数据 =====")
print(store.head())
print("\n")
train_df = pd.read_csv('./data/train.csv')
print("===== 训练数据集(train.csv)前5行数据 =====")
print(train_df.head())
print("\n")
print("===== 销售额(Sales)取值频次统计(前20条,展示核心分布) =====")
print(train_df['Sales'].value_counts().head(20))
print("\n")
print("===== 营业状态(Open)取值频次统计 =====")
print(train_df['Open'].value_counts())
print("\n")
if plot:
plt.subplot(2, 1, 1)
pltt.hist(train_df['Sales'], bins=100)
pltt.title("原始销售额(Sales)分布直方图")
pltt.xlabel("销售额")
pltt.ylabel("样本频次")
plt.subplot(2, 1, 2)
pltt.hist(np.log(train_df[train_df['Sales'] > 0]['Sales']), bins=100)
pltt.title("对数变换后销售额(log(Sales))分布直方图(仅非零值)")
pltt.xlabel("对数销售额(log(Sales))")
pltt.ylabel("样本频次")
pltt.tight_layout()
pltt.show()
print("===== 销售额(Sales)与营业状态(Open)对应数据(前10行) =====")
print(train_df[['Sales', 'Open']].head(10))
print("\n")
test_df = pd.read_csv('./data/test.csv')
print("===== 测试数据集(test.csv)前5行数据 =====")
print(test_df.head())
运行结果
===== 门店属性数据集(store.csv)前5行数据 =====
Store StoreType ... Promo2SinceYear PromoInterval
0 1 c ... NaN NaN
1 2 a ... 2010.0 Jan,Apr,Jul,Oct
2 3 a ... 2011.0 Jan,Apr,Jul,Oct
3 4 c ... NaN NaN
4 5 a ... NaN NaN
[5 rows x 10 columns]
===== 训练数据集(train.csv)前5行数据 =====
Store DayOfWeek Date Sales ... Open Promo StateHoliday SchoolHoliday
0 1 5 2015-07-31 5263 ... 1 1 0 1
1 2 5 2015-07-31 6064 ... 1 1 0 1
2 3 5 2015-07-31 8314 ... 1 1 0 1
3 4 5 2015-07-31 13995 ... 1 1 0 1
4 5 5 2015-07-31 4822 ... 1 1 0 1
[5 rows x 9 columns]
===== 销售额(Sales)取值频次统计(前20条,展示核心分布) =====
Sales
0 172871
5674 215
5558 197
5483 196
6049 195
6214 195
5723 194
5449 192
5489 191
5140 191
5041 190
5931 188
6052 188
5665 188
5584 187
5824 187
5056 187
5200 187
5197 187
5697 185
Name: count, dtype: int64
===== 营业状态(Open)取值频次统计 =====
Open
1 844392
0 172817
Name: count, dtype: int64
===== 销售额(Sales)与营业状态(Open)对应数据(前10行) =====
Sales Open
0 5263 1
1 6064 1
2 8314 1
3 13995 1
4 4822 1
5 5651 1
6 15344 1
7 8492 1
8 8565 1
9 7185 1
===== 测试数据集(test.csv)前5行数据 =====
Id Store DayOfWeek Date Open Promo StateHoliday SchoolHoliday
0 1 1 4 2015-09-17 1.0 1 0 0
1 2 3 4 2015-09-17 1.0 1 0 0
2 3 7 4 2015-09-17 1.0 1 0 0
3 4 8 4 2015-09-17 1.0 1 0 0
4 5 9 4 2015-09-17 1.0 1 0 0
进程已结束,退出代码为 0

















 4058
4058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









