



算法主要思想:
多模态学习是一个长期以来备受关注的重要且具有挑战性的问题,其核心目标在于弥合异构模态之间的表示差距,如视觉信息与语言信息之间的差异。针对现有方法通常仅关注多模态匹配或多模态分类单一任务的局限性,作者提出了一种统一的图文匹配与分类联合学习网络MMC-Net。
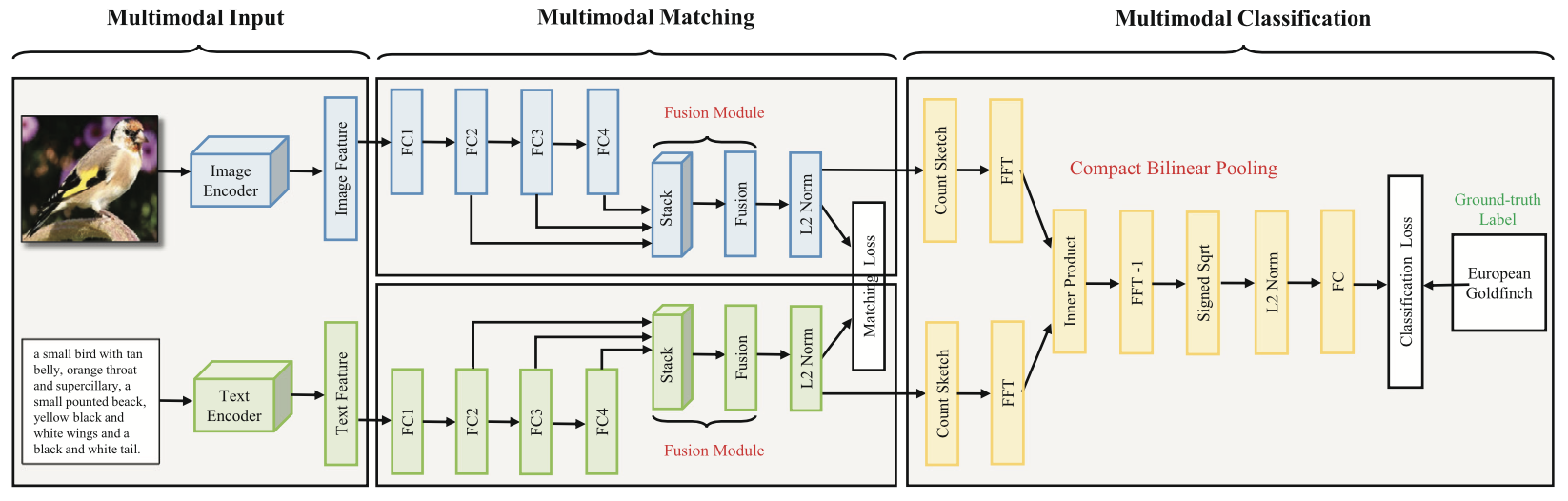
MMC-Net主要由三个核心模块组成:多模态输入、多模态匹配和多模态分类。对于输入的图像及其对应文本描述,本项目首先利用预训练的特征编码器分别提取视觉特征和文本特征。随后,在多模态匹配模块中,图像和文本分支各自包含四层全连接层,用于将原始特征映射至共享的潜在语义空间。该模块以最小化图文匹配损失为目标,旨在使匹配的图文对在潜在空间中距离更近,从而增强模态间的对齐效果。
在此基础上,多模态分类模块进一步利用图像与文本的嵌入特征,通过紧凑型双线性池化(Compact Bilinear Pooling)生成高阶且具有判别力的多模态表示向量。该表示随后用于计算与预定义标签之间的分类损失,实现对目标类别的精确预测。
通过将多模态匹配与分类任务在统一框架中联合优化,MMC-Net不仅提升了表示学习的有效性,还增强了模型对复杂语义关系的建模能力。
MM-Net
多模态输入:
MMC-Net 以视觉特征和文本特征作为输入,因此首先需要从原始数据中提取图像及其对应文本的特征表示。在图像特征提取方面,作者采用了在 ImageNet 数据集上预训练的 ResNet-152 卷积神经网络作为图像编码器,并将其改造为全卷积网络结构,以提取更为丰富的区域级视觉特征。在预处理过程中,输入图像的较短边被缩放至 512 像素,另一边按照原始比例进行等比缩放。在经过 ResNet-152 的最后一个最大池化层后,提取出一个 2048 维的图像特征向量,作为该图像在多模态网络中的视觉表示。与传统的 VGG 特征(维度为 4096)相比,ResNet-152 不仅在判别能力上更具优势,同时也有效降低了特征维度,提升了计算效率。
在文本特征提取方面,作者采用了简洁而高效的 word2vec 模型对图文描述进行编码。该模型将输入文本转化为一个 300 维的向量,通常被称为平均向量(Mean Vector)。该向量被用于表示文本模态中的语义特征,并作为 MMC-Net 中的文本输入进行后续的多模态学习与融合。
多模态匹配:
多模态匹配模块通过两组各包含四层全连接层的分支,分别对图像和文本特征进行变换,投影到一个判别性潜在空间中。考虑到模态之间的差异性,这两组分支参数未共享(分别用蓝色和绿色表示)。两支路中的全连接层通道数设置为 2048, 512, 512, 512。输入特征首先经过Batch Normalization(BN)归一化处理,其中FC1通过Dropout进行正则化,其余层则配合BN层,激活函数统一使用ReLU。
在深度神经网络中,多层特征融合已被广泛研究,可利用网络中不同层级的隐藏表示。受此启发,本项目设计了特征融合模块,以整合FC2、FC3和FC4层的表示。由于这三层的通道数一致,首先将它们进行堆叠形成尺寸为512*3的矩阵,再通过一个尺寸为1*1*3的卷积核进行操作融合。卷积操作共享三个通道方向上的权重,从而学习出每层的自适应权重。融合后的视觉特征和文本特征分别为:
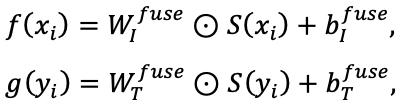
相比于简单的加和或内积操作,卷积融合能自适应不同层的特征重要性,并且相较于拼接操作,它不会显著增加特征维度,从而在提升性能的同时保证计算效率。
多模态匹配损失:
为度量匹配对之间的相似性,作者目采用了常见的余弦距离进行计算:
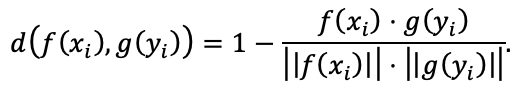
所有特征在计算前均进行L2归一化。为维持潜在空间内的相似性约束,作者设计了基于双向排序损失的匹配损失函数。为提高非匹配样本的代表性,在每个mini-batch中选取最不相似的K个负例。该损失旨在压缩匹配样本之间的距离,同时拉大非匹配样本之间的距离,从而提升匹配判别能力。具体公式如下所示:
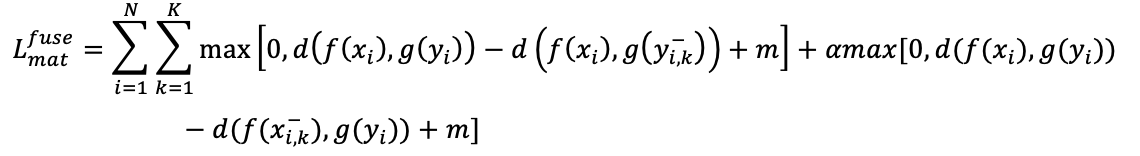
多模态分类:
多模态分类模块旨在融合视觉与文本的嵌入特征,并据此生成多模态表示,以预测目标类别。作者采用双线性池化模块,以有效融合匹配模块中学习到的视觉和文本嵌入特征。双线性池化旨在建模两个向量间元素的两两乘积关系,能够比传统的元素级加法或乘法操作提取出更具表达能力的特征。标准的双线性池化定义为:
![]()
本项目基于预定义集合进行处理,首先利用 Count Sketch 算法将向量进行线性投影,以保持其随机映射特性。随后,借助快速傅里叶变换对 Count Sketch 的结果执行卷积操作,并通过逆快速傅里叶变换生成最终的双线性特征向量。其中Count Sketch具有一下特性:
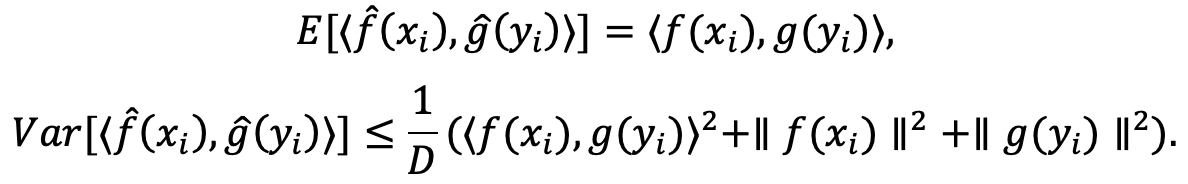
接下来,双线性特征向量将依次通过平方根层和 L2 归一化层进行处理,以增强特征的稳定性和表达能力。随后,本项目引入一个全连接层用于预测目标类别。假设数据集中预定义了 C 个类别标签,则第 j 类的概率可通过如下方式进行预测:
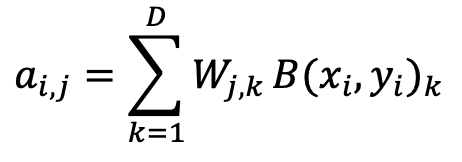
分类损失
分类模块的目标是最小化模型预测结果与给定真实标签之间的损失函数。然而,在实际应用中,不同图像可能存在单标签或多标签的标注形式。因此,本项目针对这两种不同任务情形,分别设计并采用了对应的损失函数。
对于单标签分类任务,通常应用于细粒度图像识别场景,每幅图像仅对应一个精确类别。为此,本项目采用标准的 Softmax 损失函数对分类模块进行训练,其定义如下:
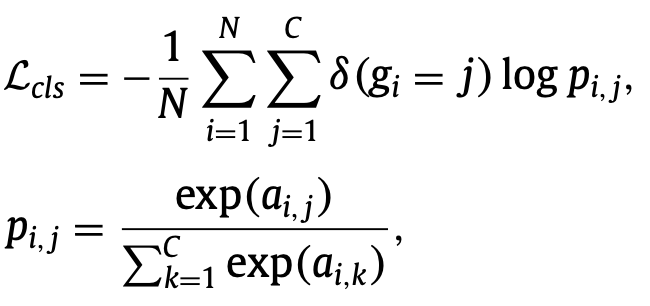
对于多标签分类任务,图像可能同时属于多个类别,因而提供了更丰富的语义信息。在这种情形下,本项目采用 Sigmoid 交叉熵损失函数进行训练,损失函数定义如下:
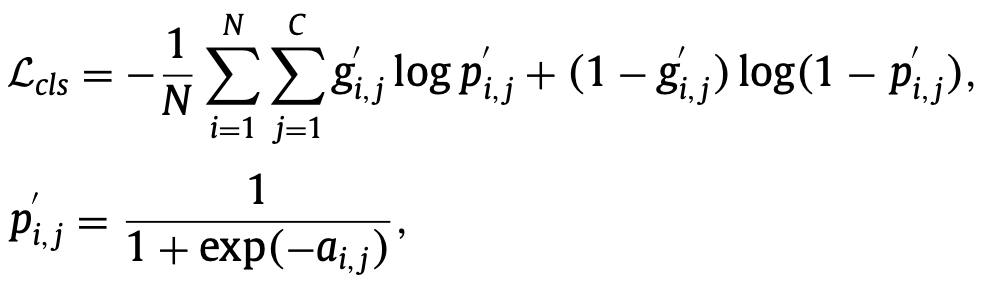

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









