







 这篇博客详细介绍了线性回归的基本概念,包括梯度下降法(批量与随机)和正规方程,以及局部权重线性回归作为缓解过拟合的方法。通过CS229课程内容,探讨了损失函数J的含义,并解释了为何选择线性回归模型和均方差作为误差函数。
这篇博客详细介绍了线性回归的基本概念,包括梯度下降法(批量与随机)和正规方程,以及局部权重线性回归作为缓解过拟合的方法。通过CS229课程内容,探讨了损失函数J的含义,并解释了为何选择线性回归模型和均方差作为误差函数。
注:该笔记主要以我自己的个人理解为主,部分基础知识会有省略,有些地方会有补充,小标题不完全按照课程pdf的顺序。笔记仅作参考,还是建议大家以课程pdf为主。
最后我会附上带有书签的课程pdf(2017年秋季课程),及problem set答案。如果有疑问,欢迎大家留言或私信讨论。
另,第一章虽然是介绍,但内容非常多,我会分为3篇博客来发。
目录
三. 局部权重线性回归(locally weighted linear regression)
零·基础知识
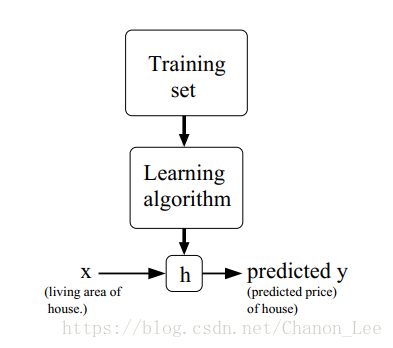
(图源自CS 229课程pdf)
统计学习方法的大致过程如上所示,训练集(Training set)通过算法训练(Learning algorithm)得到假说h(hypothesis)。在测试集中,输入x得到预测值y。我们的目标是在拥有训练集和测试集的情况下,求得假说h,使得h能准确预测y|x。
这些问题往往可以分为两大类,回归问题和分类问题。
一·线性回归
形如的问题被称为线性回归问题。x为n维向量,每一维对应不同的输入特征。如在住房价格预测问题中,x1是房屋面积,x2是房屋数量。在实际应用中,我们会在x之前加上一个1,即设
为1,使预测函数可以在平面上自由移动,不必非得通过原点。
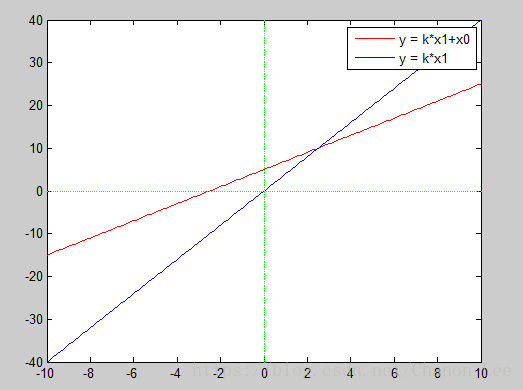
为了解y的预测值与实际值的差距,我们定义损失函数为:
损失函数(cost function)有时也叫风险函数,在不同的翻译中也有别的叫法,但一般都是以来表示,大家可以从这一点来判断。另外,损失函数也可以有别的计算方式,但用得最多的就是均方差的形式。本节中只使用该误差函数。
结合刚才介绍的假说h,我们的目标就是调整h的参数使损失函数J尽可能小(即预测值与实际值的差距尽可能小),由此得到假说h。
1. 梯度下降基本算法
输入:训练集
输出:参数θ
1.令θ=0;
2.计算
3.令
,若达到迭代次数,或
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









