



一.前言 – 什么是NextChat?
NextChat 是一款开源的 AI 聊天机器人部署工具,支持跨平台(Windows/macOS/Linux)使用,并兼容主流大模型(如 GPT-3/4、Gemini、Claude3 等)。
其核心功能包括:
- 多模型支持:一键接入 OpenAI、Gemini 等 API,提供丰富的对话与任务处理能力。
- 预制角色:内置多种“面具”(角色模板),支持个性化对话场景(如简历优化、心理咨询)。
- 轻量化设计:客户端体积仅 5MB,响应式 UI 支持深色模式与 PWA,交互流畅。
- 灵活部署:可通过 Vercel 一键部署到云端,或本地安装使用,绑定自定义域名后可全球访问。
- 隐私安全:数据本地化存储,适配复杂网络环境,确保使用稳定性。 适合个人或企业低成本搭建专属 AI 助手,实现高效人机交互与任务自动化。
示例图
二.准备
在本篇文章中,我们会介绍本地部署的方式,因此你需要一台服务器
在这里,你可以前往雨云来购买服务器
如图所示,你可以根据图中指示来购买服务器
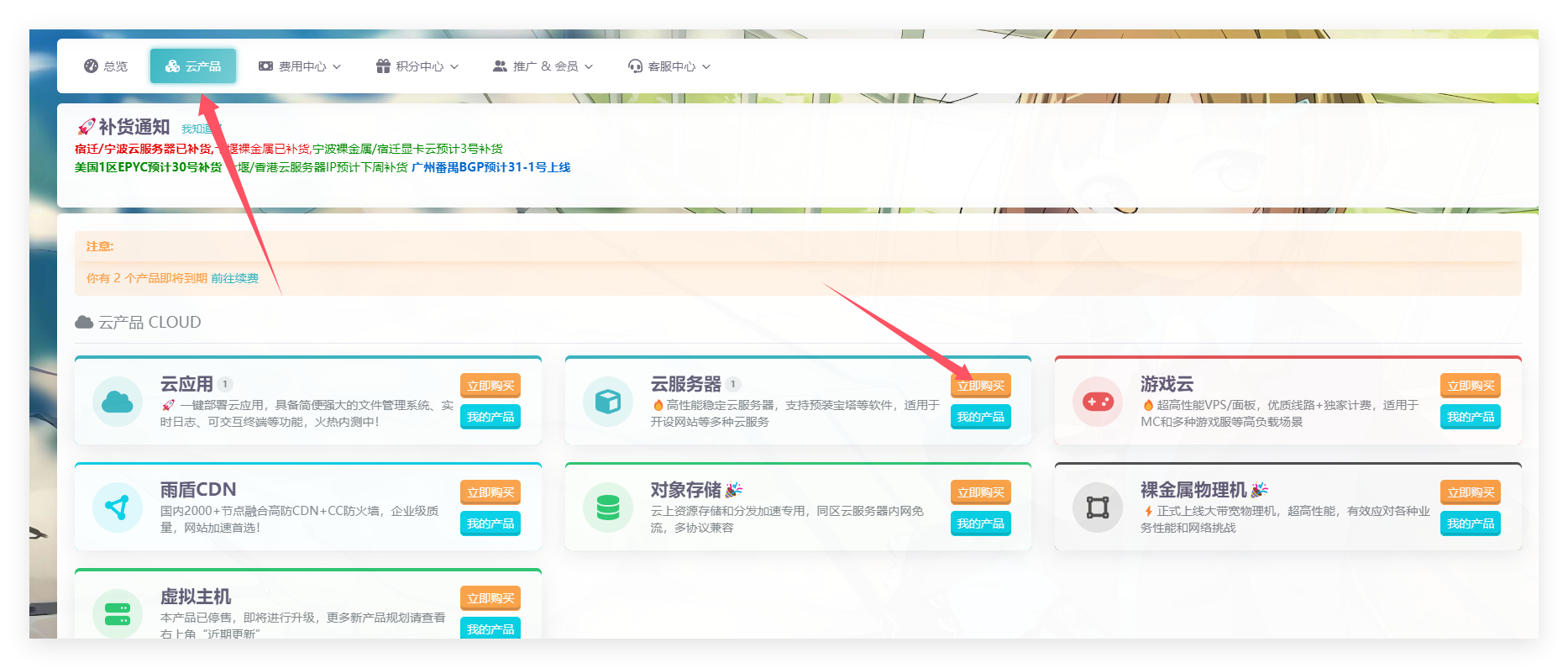
你可以看购买指南 | 雨云百科来选配合适于你的配置及区域
此外:
你需要准备一个用于AI对话的API密钥,如siliconflow的API
三.开始
1.连接服务器
以Debian11为例
在服务器信息页,复制服务器信息
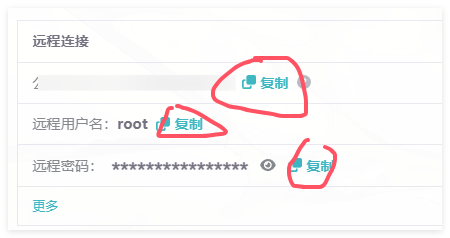
选择一个适合于你的SSH连接工具,这里以Xterminal为例
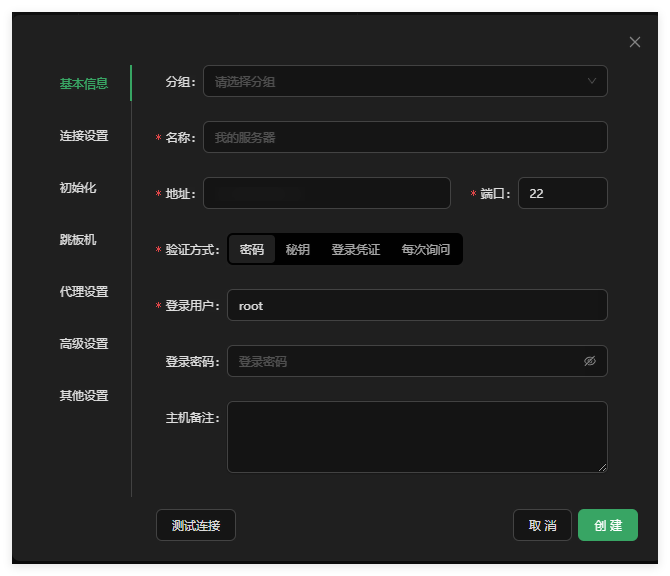
填入你的服务器信息,连接服务器
2. 安装Docker
如果你的服务器位于中国大陆,那么请配置镜像加速,这里不做推荐
在终端中输入
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
来安装Docker
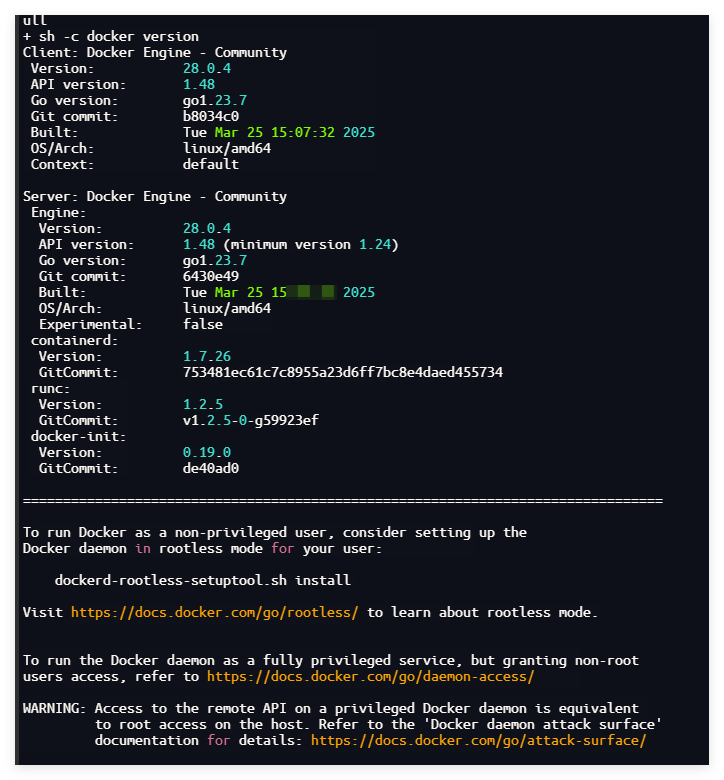
输出以上信息时,说明Docker已经安装完毕
3.安装NextChat
在终端中输入命令
docker pull yidadaa/chatgpt-next-web
拉取NextChat镜像
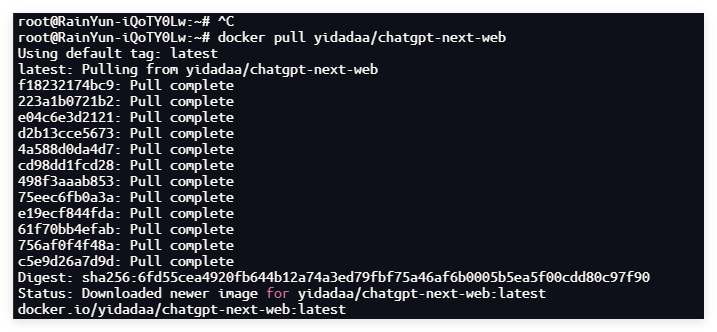
这样子就说明拉取好了
创建容器:
docker run -d -p 3000:3000 \
yidadaa/chatgpt-next-web
解释:-p参数后的是 主机端口:容器端口
如图所示,即为创建成功

4.配置与使用
在浏览器中,输入 {你的服务器IP}:{端口} 来访问
如图所示,配置AI的API
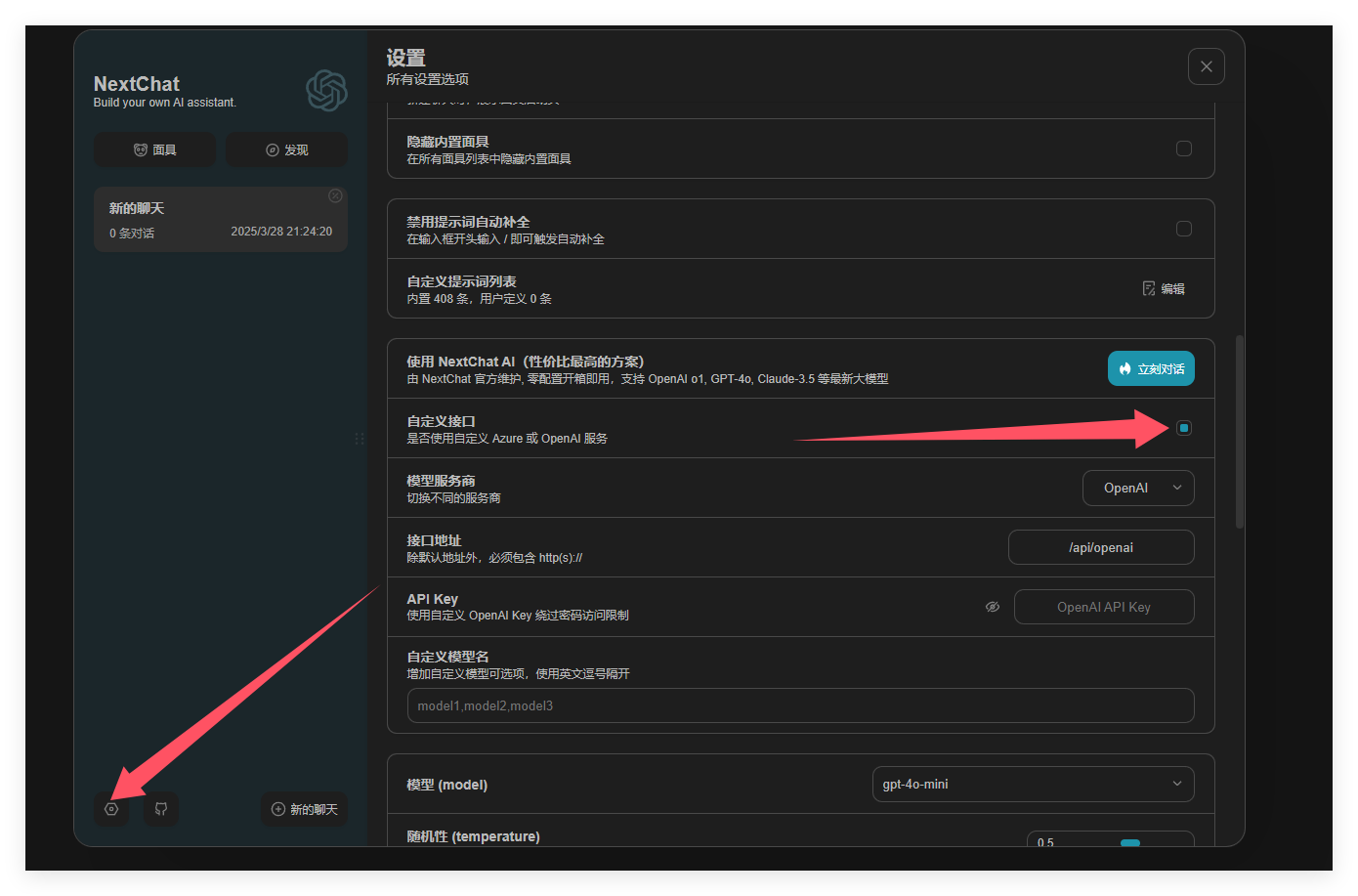
如果你使用siliconflow,那么你需要将模型服务商改为SiliconFIow,并填入你的API Key,之后创建新的聊天即可使用
如下图所示
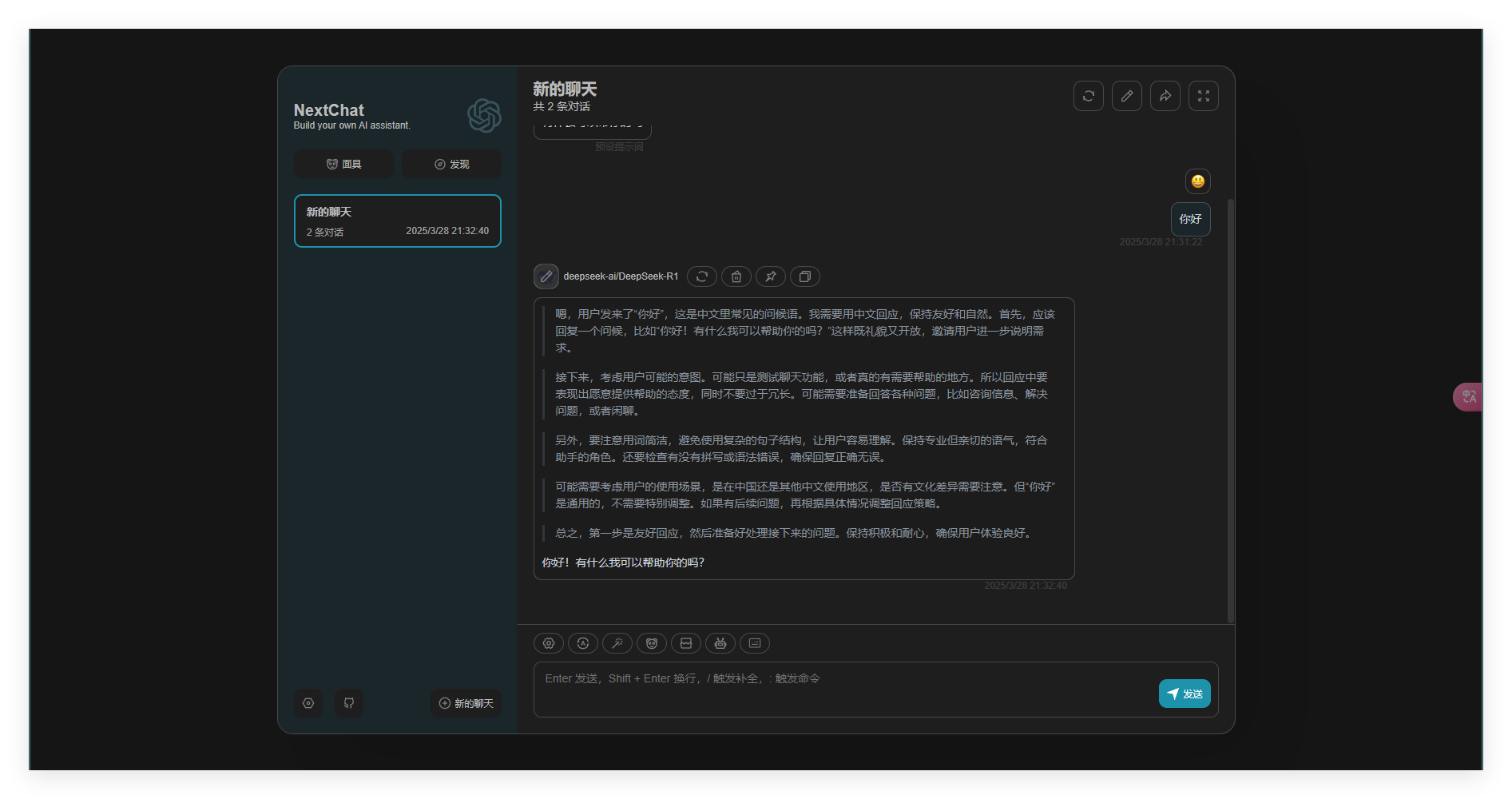
即为可正常使用


















 3116
3116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









