




概述
用户的数据一般都是存储在数据库中,也就是硬盘上,但硬盘的读写速度是计算机里最慢的硬件了。当用户请求都访问数据库,访问量一上来,数据库很容易就崩溃了,所以为了避免用户直接访问数据库,会用redis作为缓存层。
redis作为内存数据库,内存的读写速度比硬盘高出好几个数量级,大大提高了系统性能。
但引入了缓存层就会有缓存异常的三个问题:缓存穿透、缓存击穿和缓存雪崩。
缓存穿透
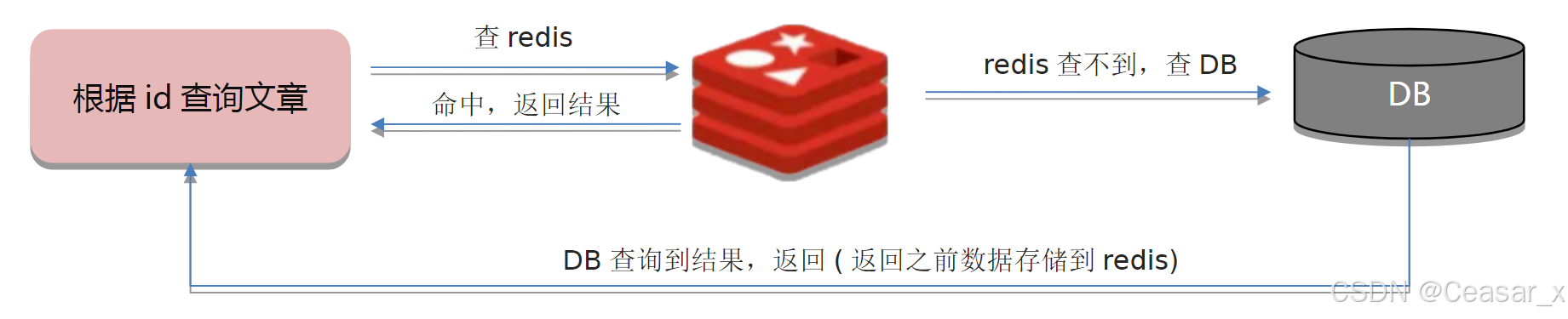
当用户访问一个不存在的数据时,导致请求在访问缓存的时候发现缓存缺失,再去访问数据库时,发现数据库中也没有该数据,数据库没办法写入缓存来服务后续请求。当大量这样的请求到来时,数据库压力骤增,这就是缓存穿透。
常见场景:
业务误操作,缓存和数据库中的数据都被误删掉了,或者有攻击者伪造了大量请求,请求某个不存在的数据(比如查询Id=0 或者Id=负数)。就会造成:
- 缓存里没有对应的数据,所以查询会落到数据库上。
- 数据库也没有数据,所以没有办法回写缓存,下次同样的请求还是会落到数据库上。
解决方法:
1.返回特殊值(如NULL):
在缓存未命中且数据库中也不存在时,往缓存中写入一个特殊值,当下一次请求过来时看到这个特殊值就没有必要继续查询数据库了。但如果攻击者每次使用不同的Key来访问时,就会造成回写大量特殊值,造成redis内存浪费,进而引起另一个问题,也就是redis内存不足,可能会导致执行内存淘汰时把其它有用的数据淘汰掉。
优点:简单。
缺点:浪费内存。
2.布隆过滤器
布隆过滤器是一个快速判断元素是否存在的结构,它可以在很小的内存占用下,快速判断一个元素是否在一个集合中。当一个访问过来时先进行判断是否存在,若不存在则直接返回,避免对数据库的查询。
优点:内存占用较少,没有多余 key
缺点:实现复杂,存在误判

3.限流策略
当有大量恶意请求访问不存在的数据时,在 API入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
布隆过滤器
布隆过滤器由初始值都为0的位图数组和N个哈希函数两部分组成。在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
- 存储数据: id 为 1 的数据,通过多个 hash 函数获取 hash 值,根据 hash 计算数组对应位置改为 1
- 查询数据:使用相同 hash 函数获取 hash 值,判断对应位置是否都为 1
但布隆过滤器由于是基于哈希函数实现査找的,高效査找的同时存在哈希冲突的可能性,比如数据x和数据y 可能都落相同位置上,存在误判的情况。所以,查询布降过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
缓存击穿
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
解决方案
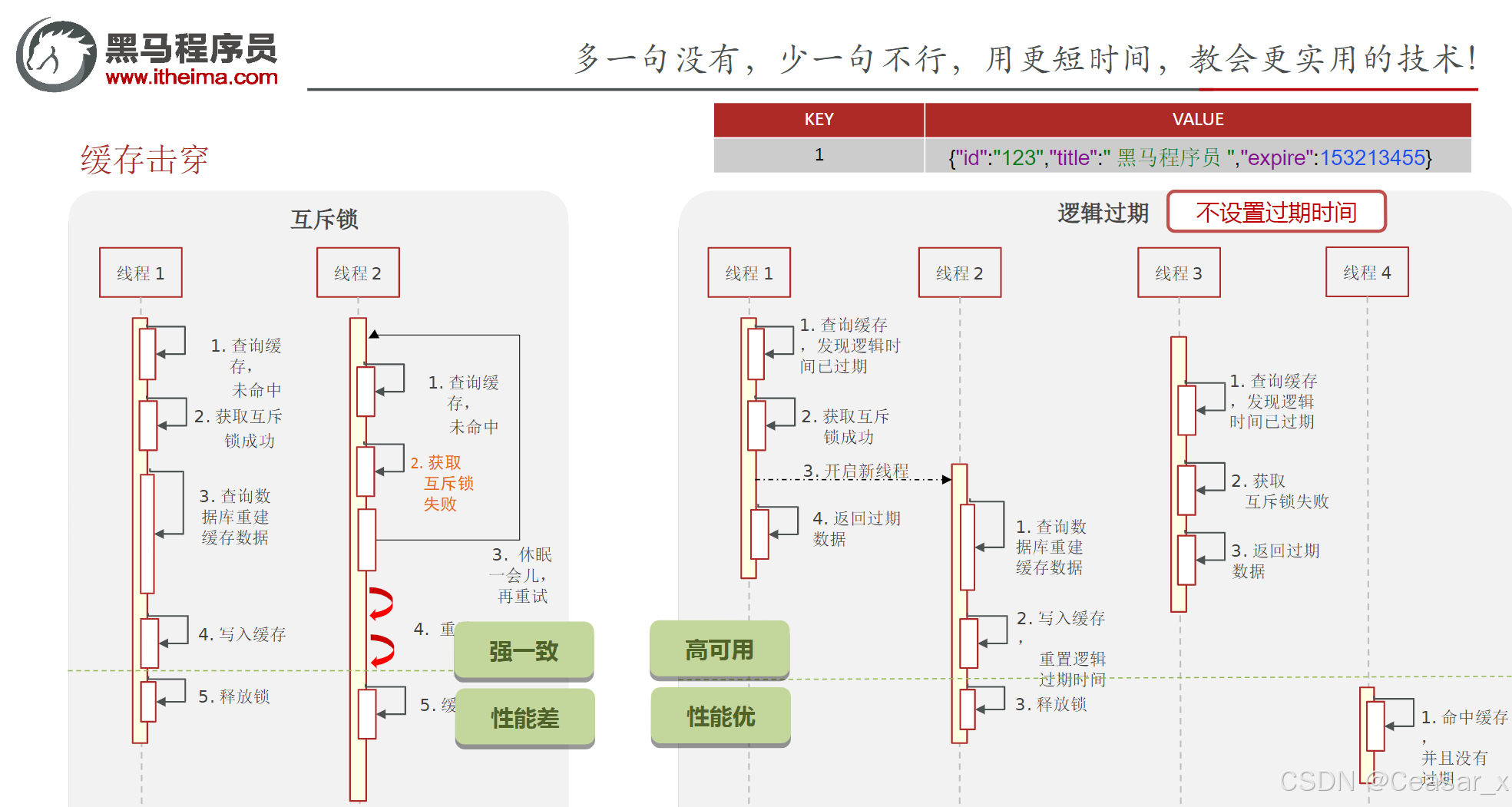
- 互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行load db的操作并回设缓存,否则重试get缓存的方法。
- 逻辑过期:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间当查询的时候,从redis取出数据后判断时间是否过期,如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新的。
当然两种方案各有利弊:
- 如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题
- 如果选择key的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
缓存雪崩
缓存雪崩一般有两个常见场景:当大量缓存数据在同一时间过期(失效)或者Redis 故障宕机时。
如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
解决方案
大量数据同时过期的解决方法:
- 给不同的 Key 的 过期时间添加随机值。
- 互斥锁。
- 数据预热
redis故障宕机的解决方法:
- 利用 Redis 集群提高服务的可用性:通过主从节点的方式构建 Redis 缓存高可靠集群,如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
- 给业务添加多级缓存。
- 给缓存业务添加降级限流策略。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









