



 文章解释了自注意力机制在Transformer模型中的核心作用,通过单词嵌入、QKV操作和softmax归一化计算单词间的关系,模拟人脑处理句子的方式实现精准翻译。
文章解释了自注意力机制在Transformer模型中的核心作用,通过单词嵌入、QKV操作和softmax归一化计算单词间的关系,模拟人脑处理句子的方式实现精准翻译。
自注意力机制的计算与理解
理解transformer,核心就是理解自注意力机制。例如,在我们输入一段文本 I saw a saw,根据人脑的认知,意思是我看到了一个锯子。但是机器真能准确的翻译畜第二个saw是锯子吗,人脑是通过判断句子之间的相关性得出结论的,而自注意力机制同样如此,通过判断句子中单词的相关性来做出精准翻译。那究竟是如何计算这个相关性呢?
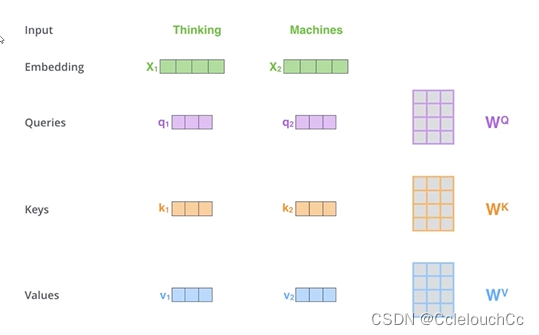
这里就涉及到了三个矩阵Q K V,如下图所示,假设我们输入了两个单词Thinking和Machines,我们想要计算这两个单词之间的相关性,
(1)将两个单词通过embedding(编码)成向量形式,目的是让计算机能够识别,因为计算机是识别不了文字的,只有将文字转成向量形式才能识别。
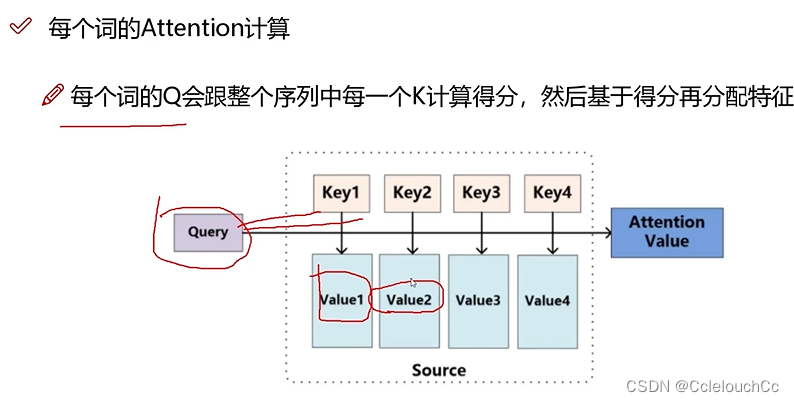
(2)Q和K说通俗点其实就是查询键与被查询键,例如,我想要查询(q)Thinking和被查询(k)Machines的关系大不大(如果大的话就要重点关照了,不大就可以不重点关照),所以查询关系=q1与k2的内积。之后将内积出来的分数通过softmax归一化,这样就能直观地通过概率来观测单词之间的关系了。(注意:查询Thinking和Machines的关系和查询Machines和Thinking的关系是不一样的,因为他们的前后位置关系不一样,前者是q1与k2的内积,后者是q2与k1的内积)
(3)假设现在我们通过Q与K的内积并经过softmax之后,得出了Thinking本身和自己的相关性(q1k1)为0.8,受Machines影响的相关性(q1k2)为0.2,那么最后翻译出Thinking的意思=0.8V1+0.2V2,(V就是与K对应的value值,即实际的特征信息,在这个例子里就是Thinking具体翻译的意思),通过这样的方式,我们就能模拟人脑思考句子的方式,进行输出。


















 3806
3806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









