







本文将详细介绍 Go 语言中 map 的数据结构及其核心操作,包括构造、读取、插入和删除的流程。本文内容基于 Go 运行时源码,帮助你深入理解 Go map 的内部实现。
数据结构
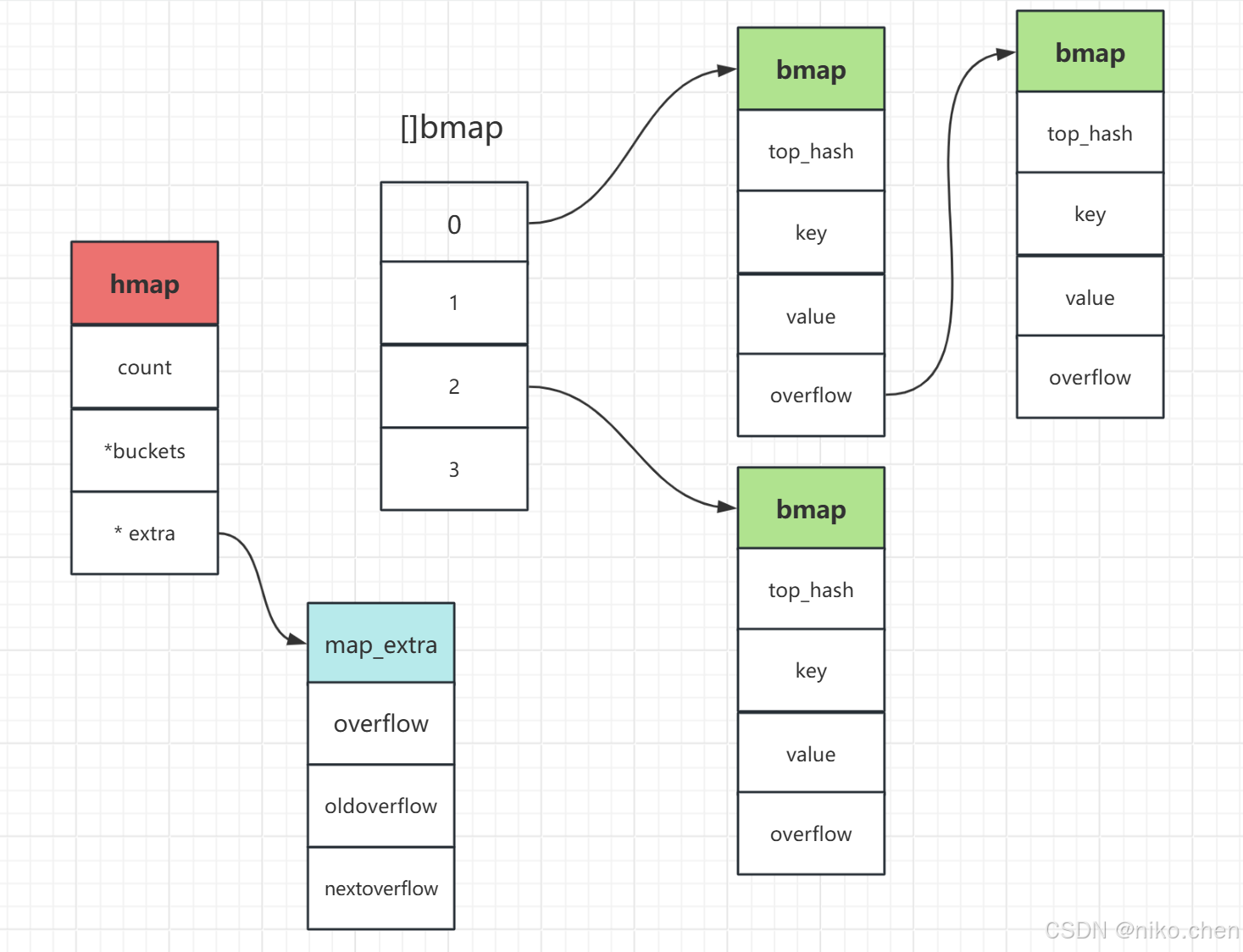
hmap
Go map 的头部结构定义如下:
// A header for a Go map.
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2,
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组(bmap),大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
// 指向老桶数组,扩容时用
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // 溢出桶
}
bmap
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
- 每个桶(bmap)存储最多 8 个键值对。经过哈希计算后,具有相同哈希高 8 位(称为 tophash)的键会被分配到同一桶中。桶内会根据 key 对应的哈希高 8 位选择存储槽位。
mapextra
mapextra 用于管理桶数组中使用的溢出桶,结构如下:
type mapextra struct {
overflow *[]*bmap // 供桶数组 buckets 使用的溢出桶;
oldoverflow *[]*bmap // 扩容流程中,供老桶数组 oldBuckets 使用的溢出桶;
nextOverflow *bmap // 下一个可用的溢出桶.
}
- 一图胜千言
构造方法
在创建 map 时,会根据预估的大小(hint)计算所需桶的数量,并预先分配桶数组与溢出桶(若需要)。
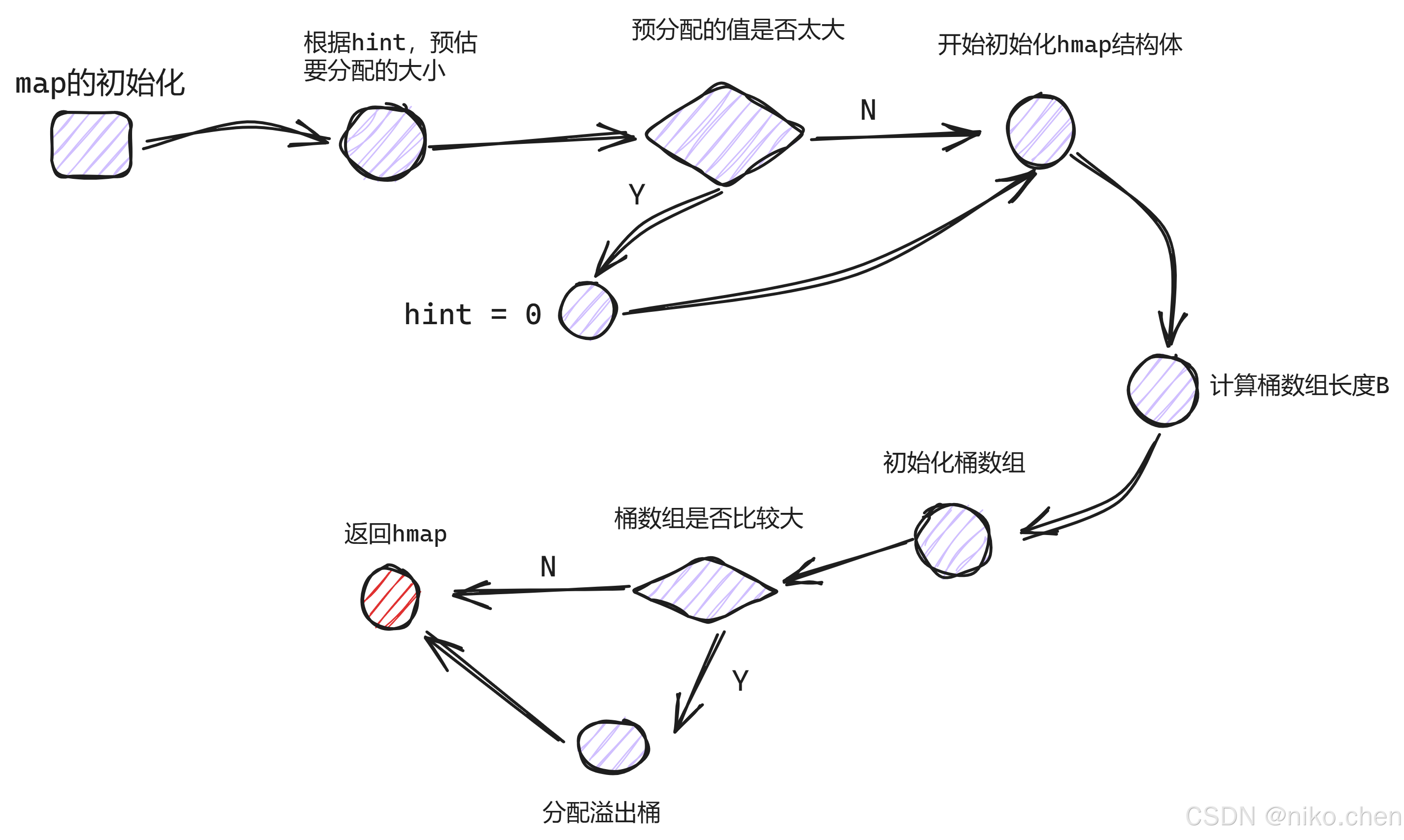
func makemap(t *maptype, hint int, h *hmap) *hmap {
/*
hint: 拟分配的map的大小;
在分配前,会提前对拟分配的内存大小进行判断,倘若超限,会将 hint 置为零;
*/
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
// 计算hash因子
h.hash0 = fastrand()
B := uint8(0)
// 计算B的大小
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
// 初始化桶数组
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果map容量过大
if nextOverflow != nil {
// 申请一批溢出桶
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
map的读流程
在读取操作时,首先判断 map 是否为空;接着通过传入的 key 计算哈希值,根据哈希值定位到对应的桶;如果 map 正处于扩容状态,还需要判断该桶是否已完成从旧 map 向新 map 的迁移。
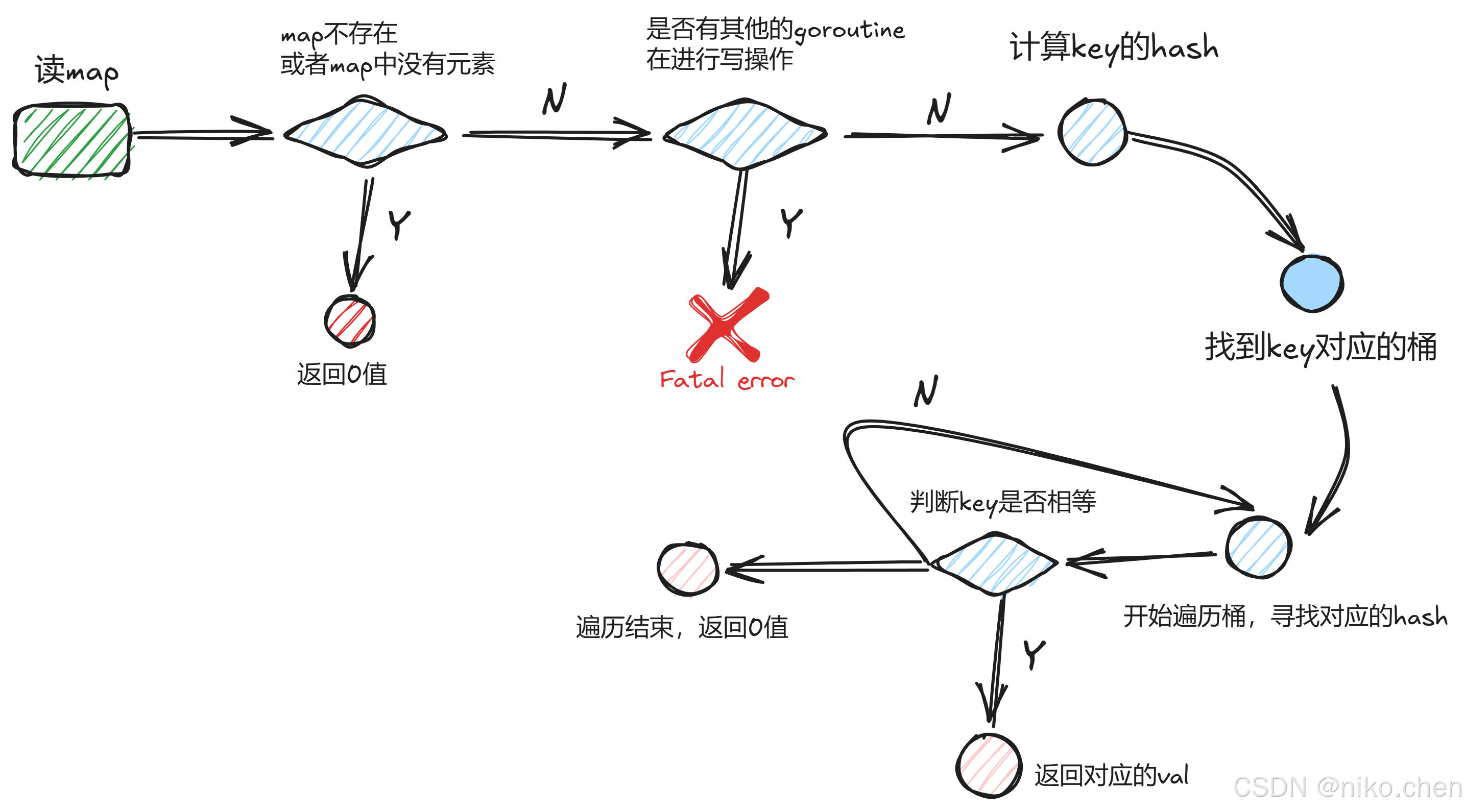
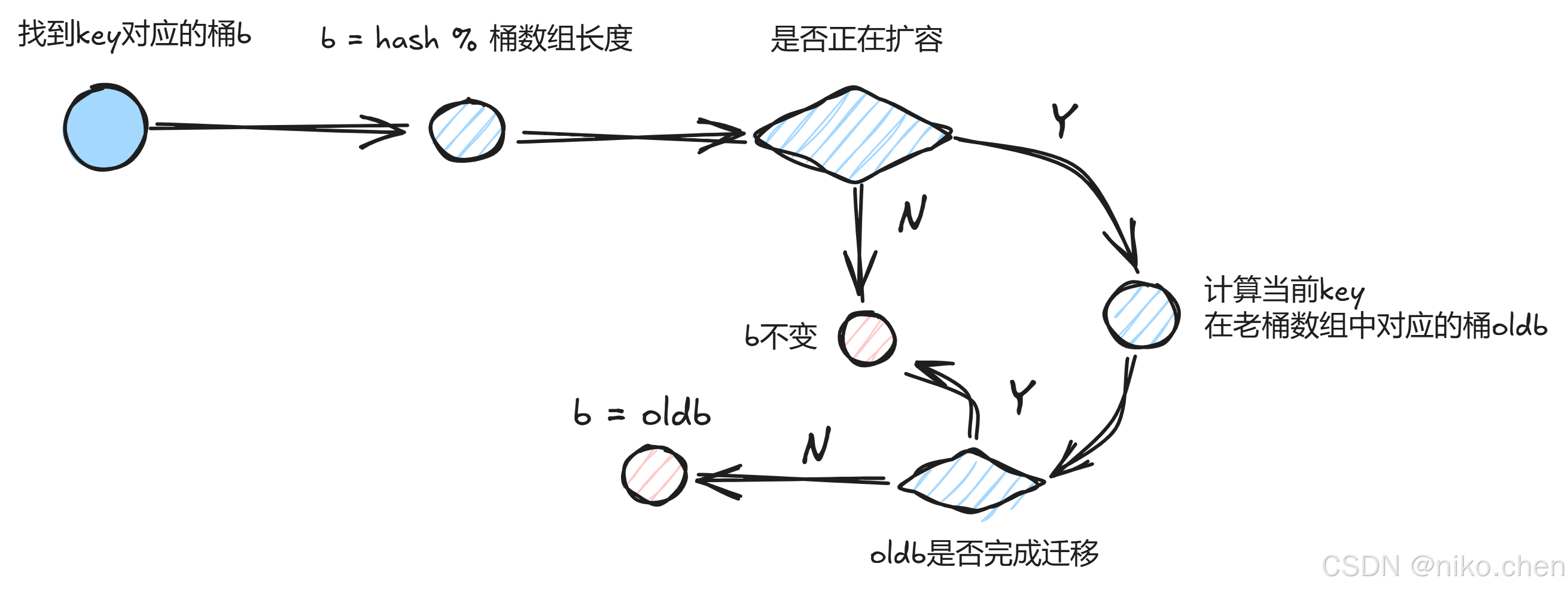
- 如何找到key对应的桶呢?比较重要的地方就是:如果此时map正在扩容,还需要判断这个key所在的桶是否完成了从“旧map”到“新map”的迁移。(有关map扩容的相关细节,我会专门写一篇博客介绍)
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 如果map为空 或者 map中没有元素
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// 如果当前有其他goroutine正在对map进行写操作
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
// 在桶数组中,找到对应的桶
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如果map正在扩容,就要判断:{key,val}所在的桶,是否完成了迁移(通过hmap中的nevacuate)
if c := h.oldbuckets; c != nil {
// 如果是增量扩容,老桶数组的长度是新桶数组长度的一半
if !h.sameSizeGrow() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









