







 超级会员免费看
超级会员免费看
 权重衰退是防止过拟合的常用方法,通过限制权重的L2范数来控制模型复杂度。本文介绍了权重衰退的概念、L2正则化的数学原理,以及在PyTorch中如何实现。同时,探讨了权重衰退与L1正则化在产生稀疏性方面的区别,并提供了拉格朗日约束求极值的背景知识。
权重衰退是防止过拟合的常用方法,通过限制权重的L2范数来控制模型复杂度。本文介绍了权重衰退的概念、L2正则化的数学原理,以及在PyTorch中如何实现。同时,探讨了权重衰退与L1正则化在产生稀疏性方面的区别,并提供了拉格朗日约束求极值的背景知识。
文章目录
1. 权重衰退
https://www.bilibili.com/video/BV1UK4y1o7dy?p=1

Weight decay,是最常见的一种用于处理过拟合的方法。
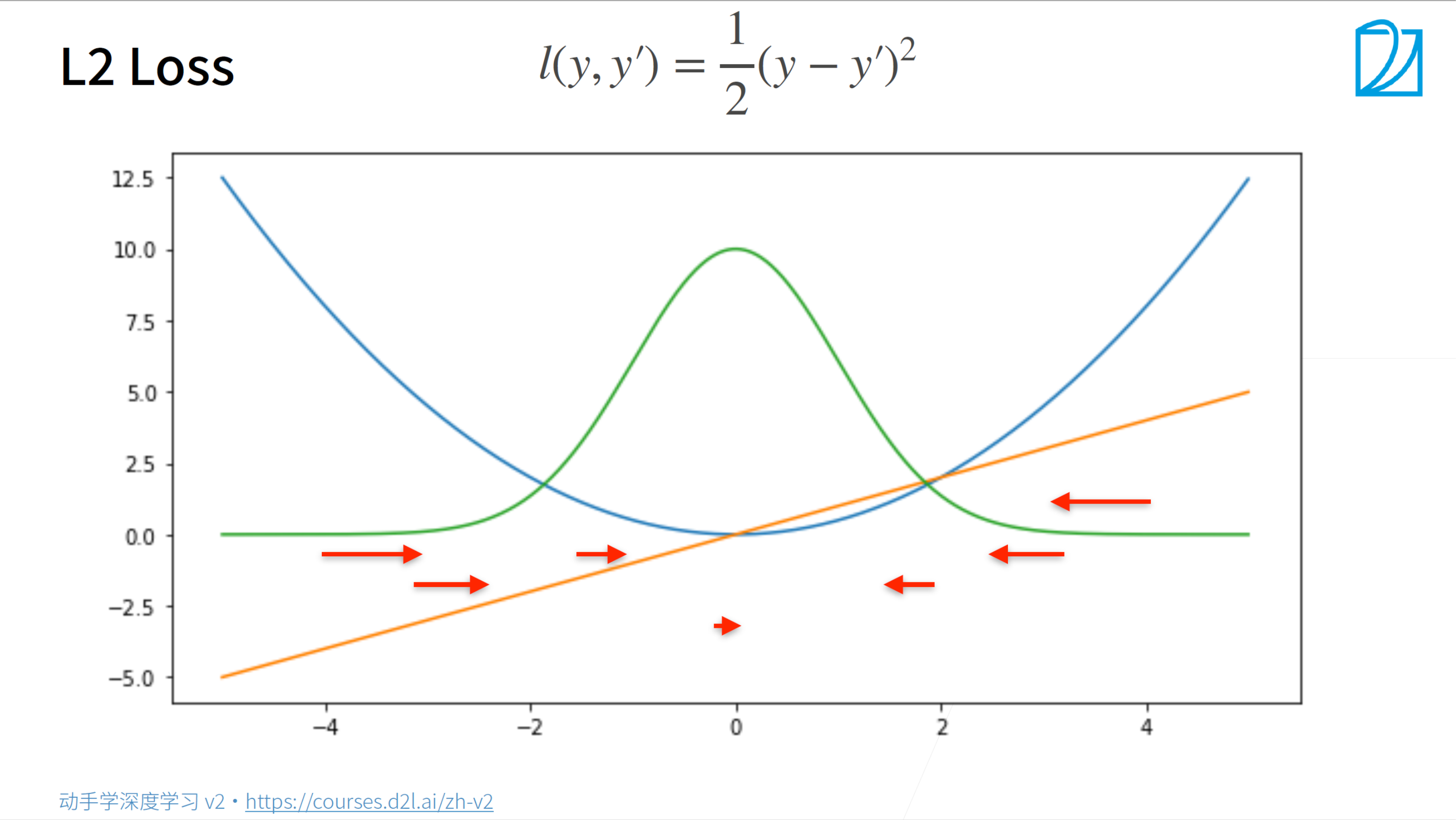
下图右边的小图,解释一下
- 对于红色的这些样本点,如果不去限制模型的参数,那么它可以随意延展,有可能就会变成蓝色线的那样
- 而限制参数大小后,就是绿色线那样。学出来的结果会比较平滑,变化差异不会那么大,只学比较简单的模型

之前说过控制模型容量的方法,
- 减少模型参数
- 缩小参数范围
- 其中
weight decay就是一种通过限制参数值的选择范围来控制模型容量的方法。 - 一般都是模型太大,数据容量太小,导致过拟合,所以一般都是防止过拟合。
假设我们要优化的还是 min l ( w , b ) \min l(\textbf{w},b) minl(w,b),其中权重是w,偏置是b,
- 但是在优化过程中,加入一个限制,subject to(限制),简单来说,就是让w的L2 norm(L2范数)小于一个值。
- 即 使得 w这个向量中每个值的平方和的平方根 小于一个特定的值。
- 为了减小模型容量,防止过拟合,需要将 w \textbf{w} w缩放到一个特定范围中,
- 关于L2范数,
可以查看:机器学习中的范数规则化之(一)L0、L1与L2范数
另外,还会涉及到岭回归ridge以及类似的lasso回归,可以继续参考:
正则化是什么?以及Ridge和 Lasso回归的区别
图文解释LASSO和Ridge回归的区别 - 一般不对b进行限制,对于一次函数来说,移动b就是上下移动,数学上来说,对b进行限制作用不大,自己也可以试验看看。
- θ \theta θ越小,防止过拟合的能力就越强,因为模型的权重参数w的范围就越小。
- 但是直接优化上面的公式会比较复杂,所以通常会采取下面的形式

使用L2范数作为硬性限制不好优化,不常用,更常用的是上面这种——使用均方范数作为柔性限制。
有疑问的可以去看 3 拉格朗日约束求极值 扩展(就是高数的知识)这里的描述也有些不准确
- 对于每个 θ \theta θ来说,都可以找到一个 λ \lambda λ使得之前的目标函数等价于上式
- 其中,后面的那一项 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2}||w||^2 2λ∣∣w∣∣2,一般被称为惩罚项,penalty
- 超参数
λ
\lambda
λ控制了正则项的重要程度
- 当 λ \lambda λ为0的时候,不起作用
- λ \lambda λ接近无穷大,则为了让整体越小,w就要无限接近于0
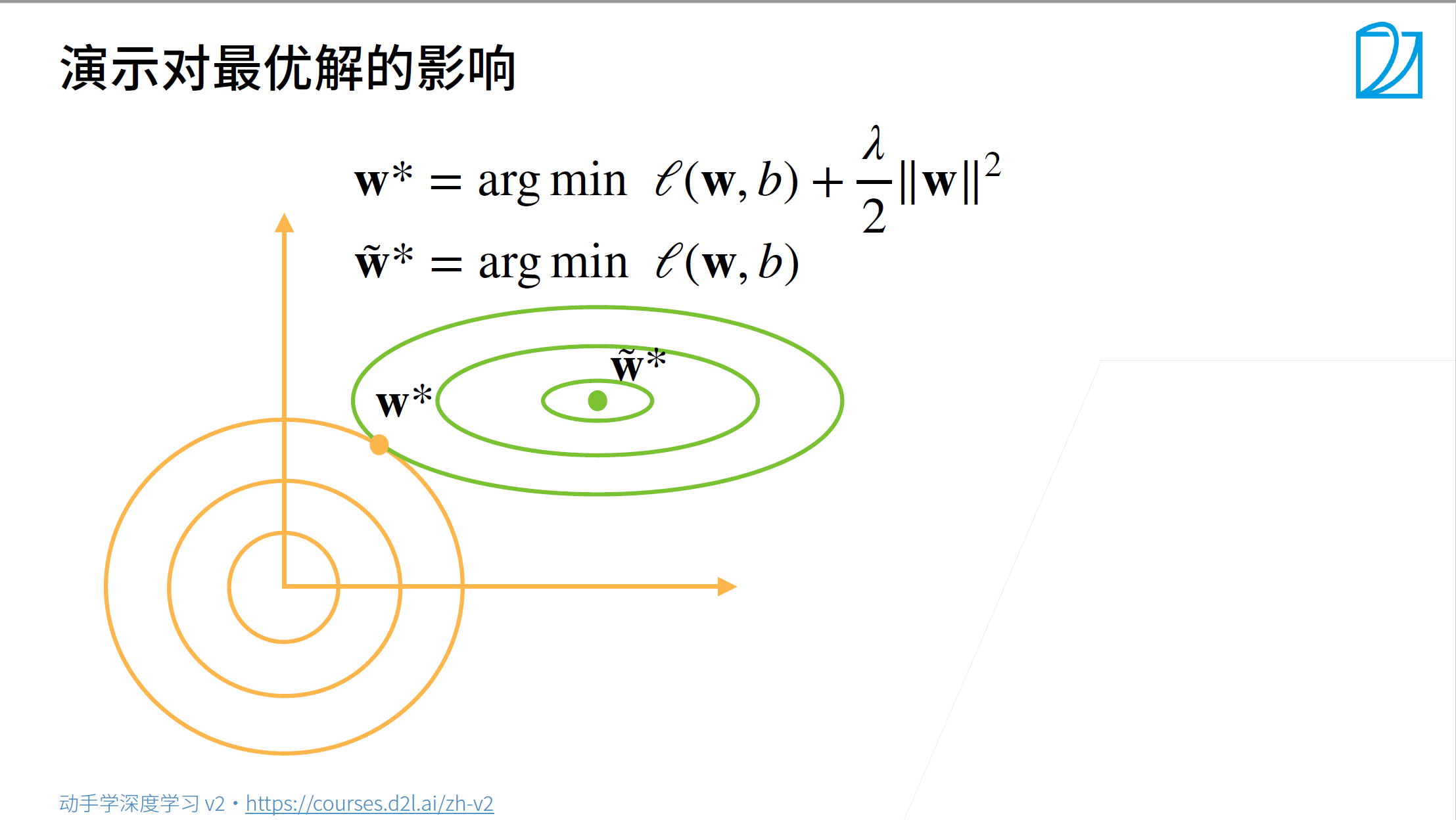
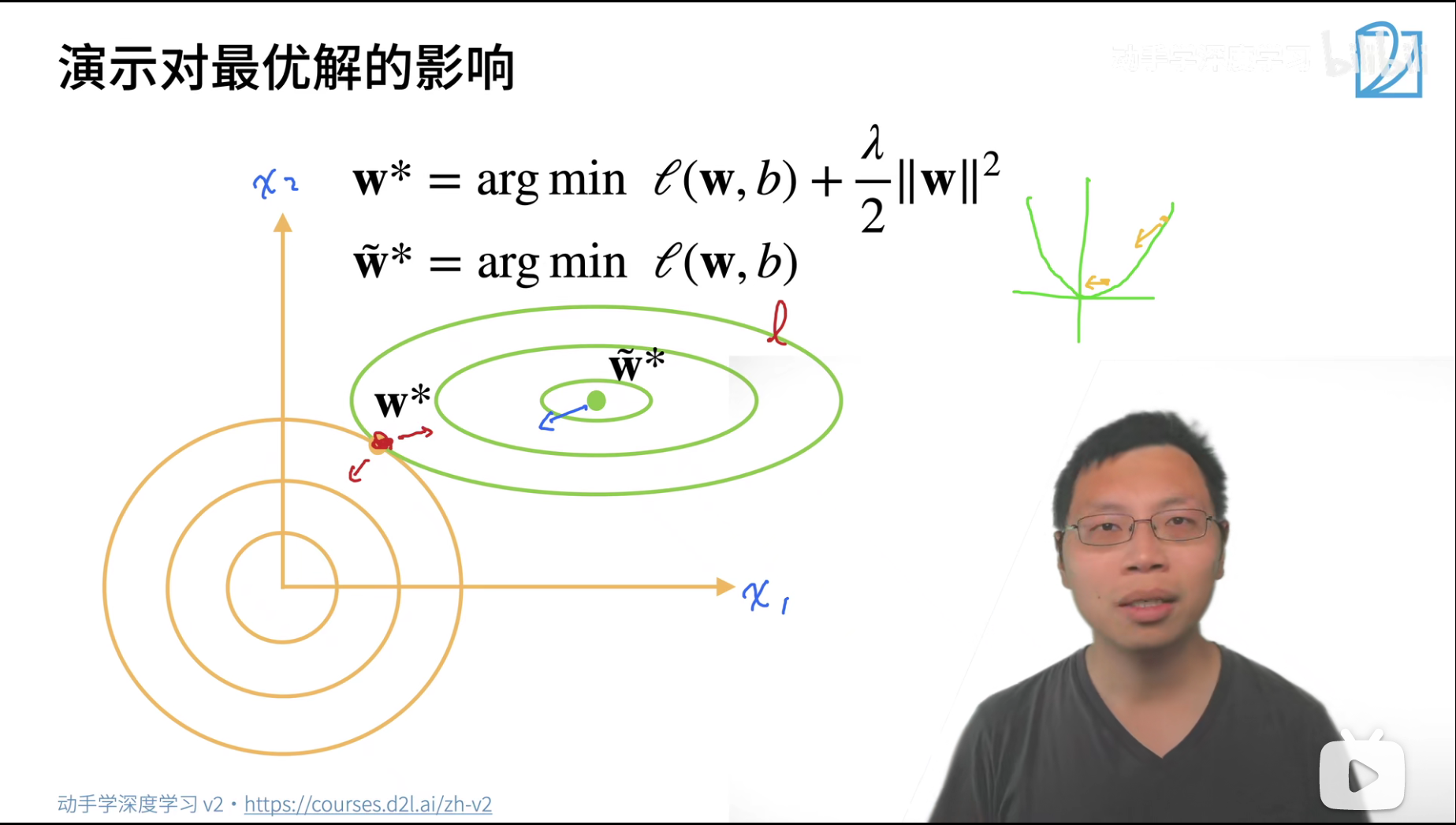
- 绿色线对应的是硬性限制的优化过程,其中最中间的绿色点,对应硬性限制的最优解。
- 假设 l = w x + b l=wx+b l=wx+b,但是这里要优化的是 w w w,所以观察 w w w的变化,在平面坐标系中,w权重就包含两个值,分别对应x轴和y轴。
- 所以可以认为这里关于w的方程其实类似一个二次方程,有点像椭圆方程,只是此时x轴和y轴表示的是 w 1 w_1 w1和 w 2 w_2 w2这两个权重值,而不是不同样本的x和y
- 黄色线对应的是惩罚项,其中右上角的黄色点,对应的是加入了惩罚项的整体的最优解w,并不是惩罚项部分的最优解
- 这部分可以结合 L2扩展 这个部分看
椭圆的标准方程

圆的标准方程
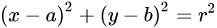
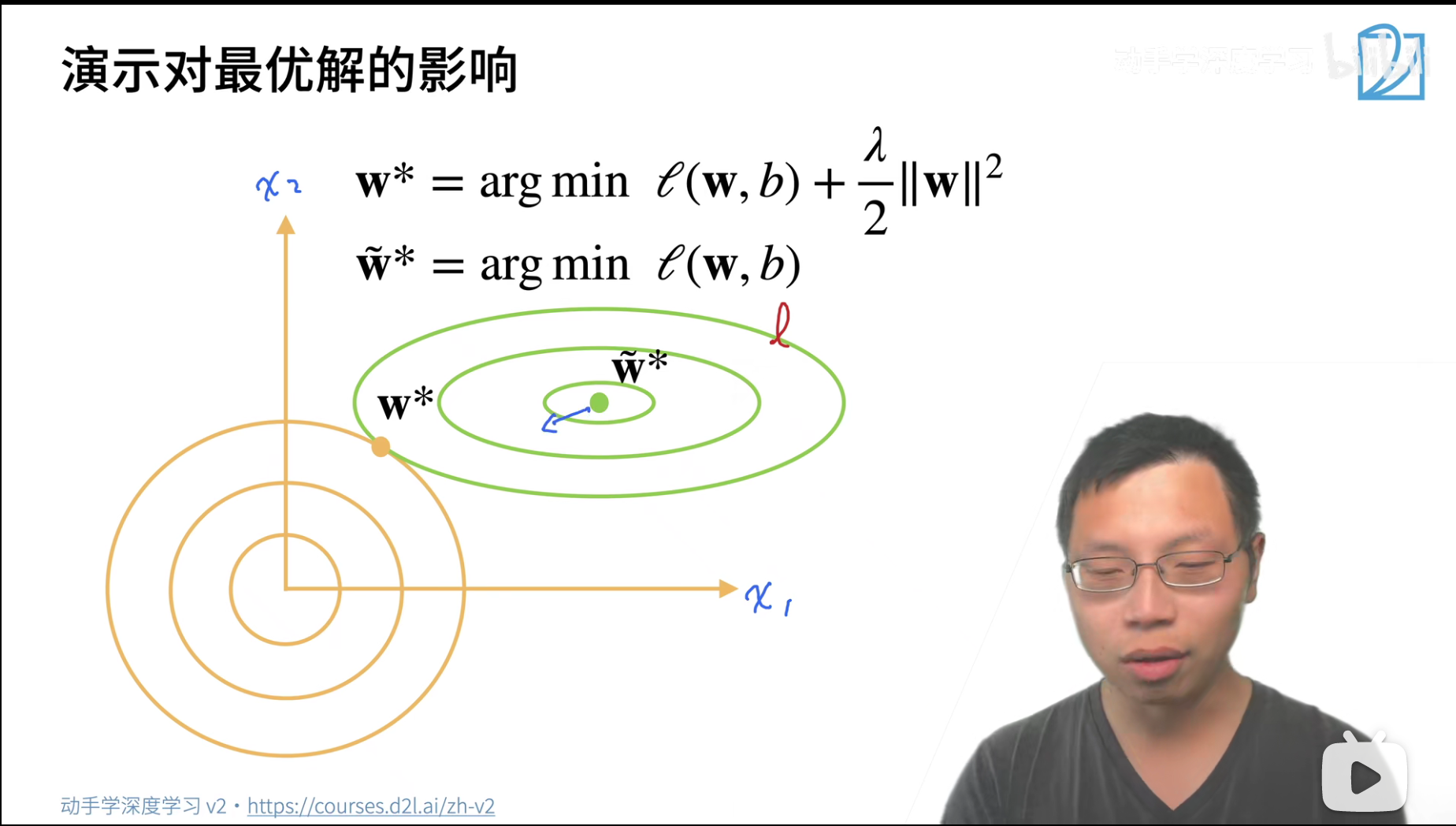
- 不难看出,对于绿色的w的最优值,如果应用到软性限制中去,不能成为后者的最优,过于大了。
- 如果让绿色点沿着前往黄色点的方向走,则 m i n l ( w , b ) min l(w,b) minl(w,b)这一项会变大,因为不是最优解了,那么对应的,则惩罚项 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2}||w||^2 2λ∣∣w∣∣2会变小,因为接近 w ∗ w^* w∗了,整体应该表现为变小。
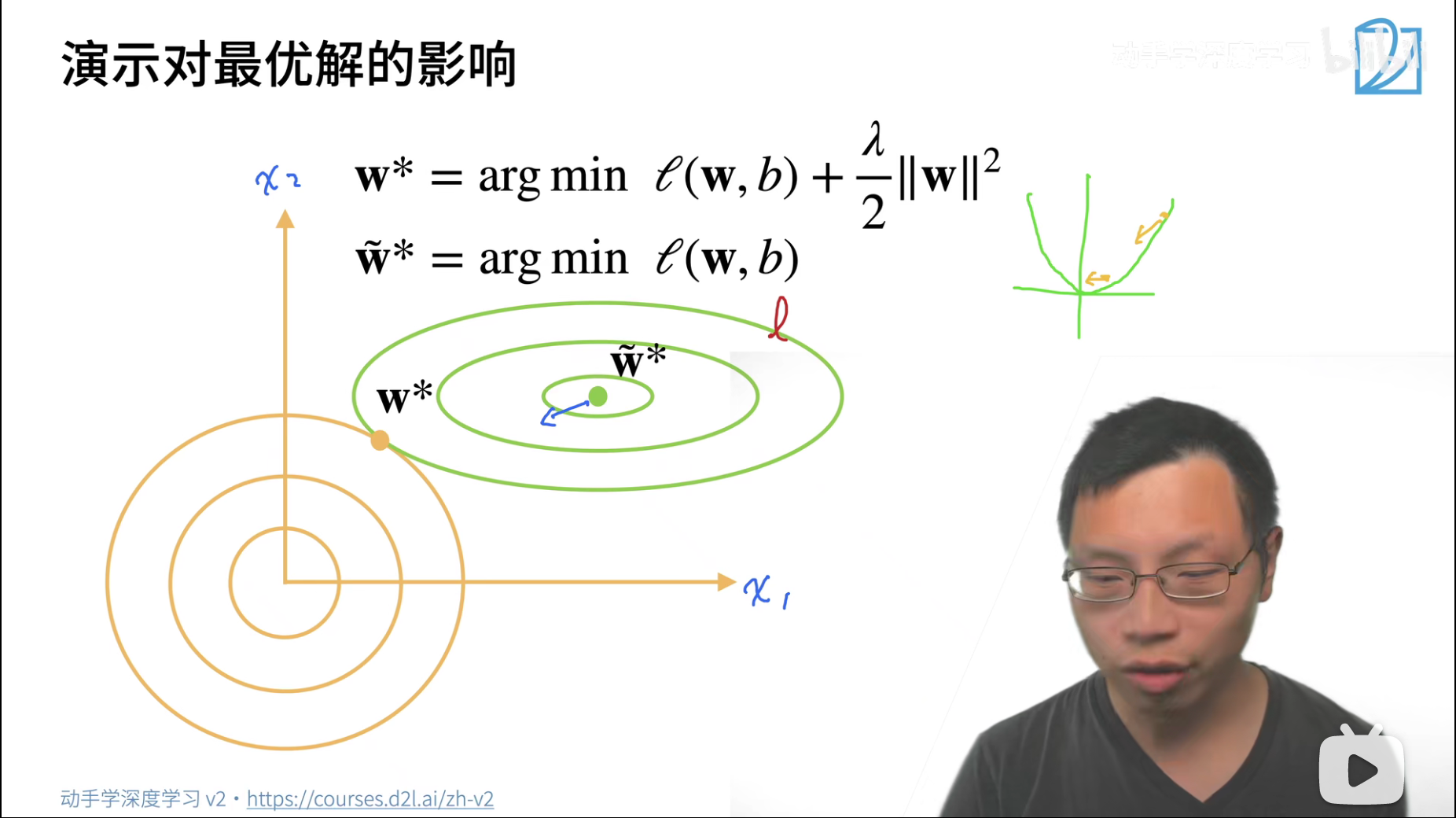
之前说过l2损失,
- L2损失靠近原点的时候,梯度变化比较小,所以向下拉的力度小,
- 远离原点的时候,梯度变化比较大,所以向下拉的力度大
这里也是一样的,对于绿色点来说
- penalty惩罚项对绿色点的拉力/影响力会比
l
l
l损失项本身要大
- 假设,绿色点可能最后走到了黄色点,黄色点是一个对
l
l
l和惩罚项的平衡点,
- 在这个点左下继续走,则可能惩罚项减少很多,但是不足以平衡 l l l增加的东西
- 而如果没到这个黄色点,还在黄色点右上方,则可能 l l l减少的部分不足以平衡惩罚项增加的部分
- 所以整体上来说,惩罚项penalty的引入,使得最优解向原点偏移了。

岭回归或者叫权重衰退,weight decay。之所以称为权重衰退,是因为
- 上面化简后的公式,可以看到,w的更新过程中,由于加入了惩罚项,所以 w t w_t wt部分多了一个 n λ n\lambda nλ,和之前的区别就在于 w t w_t wt的系数前面多了一个 n λ n\lambda nλ。
- 相当于先把 w t w_t wt变小一点点,然后再让它走一点点。比之前的梯度更新多了一些偏移
- 总的来说,权重衰退是因为加入了惩罚项,所以在梯度更新时,当前的权重会基于自身有一个缩小(因为是乘法关系,所以是基于自身的缩放,是一种相对的缩小),然后再进行变化(是一个单纯的减法,是一种绝对的值的减少)。
- 注意:惩罚项中的拉格朗日算子前面还要乘上一个学习率,而学习率一般都是0.001这样,所以 λ \lambda λ可以视情况调的大一些
另外,注意
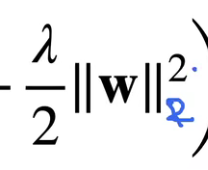
- 这里黑色的2是平方,
- 蓝色的2是省略的表示L2正则的那个2, ∣ ∣ W ∣ ∣ 2 || W ||_2 ∣∣W∣∣2 这个一般表示W的L2正则项。
- 所以上面的惩罚项其实使用的是L2正则的平方

2. L2扩展
以下内容为转载,来源:机器学习中的范数规则化之(一)L0、L1与L2范数
实际上,对于L1和L2规则化的代价函数来说,我们可以写成以下形式:
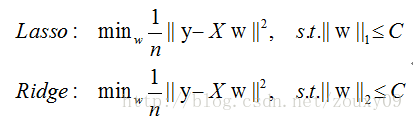
- 也就是说,我们将模型空间限制在w的一个L1-ball 中。
- 为了便于可视化,我们考虑两维的情况。
- 在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解(参考下面 拉格朗日约束求极值 扩展):
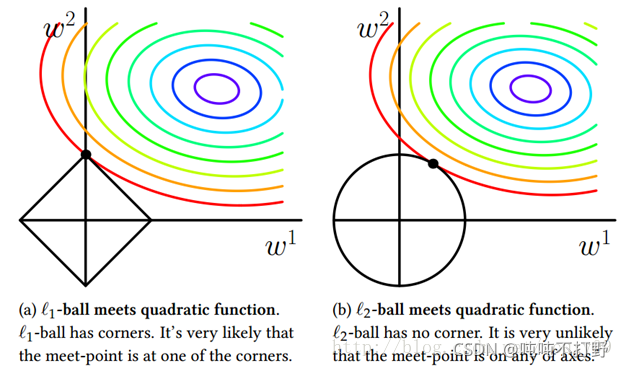
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
因此,一句话总结就是:
- L1会趋向于产生少量的特征,而其他的特征都是0,
- 而L2会选择更多的特征,这些特征都会接近于0。
- Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
3 拉格朗日约束求极值 扩展
复习高数
3.1 使用拉格朗日法求解条件极值
对于无约束条件的函数求极值,主要利用导数求解法。

所以上面我们面临的L2正则项,其实是对
min
l
(
w
,
b
)
\min l(w,b)
minl(w,b)这个求最值的方程,添加了一个限制,要求
∣
∣
w
∣
∣
2
<
θ
||w||^2<\theta
∣∣w∣∣2<θ。



看到这里,不难解释,为什么添加的惩罚项是
λ
2
∣
∣
w
∣
∣
2
\frac{\lambda}{2}||w||^2
2λ∣∣w∣∣2,因为L2正则本身后面有个平方,所以添加拉格朗日乘数之后,还加了一个
1
/
2
1/2
1/2,这样后面求导就可以约掉常数项了。
参考:
- 百度文库:8-7条件极值与拉格朗日乘数法
- 如果无法阅读完整ppt,可以去这里
- 优快云博客:求约束条件下极值的拉格朗日乘子法
- 知乎:约束下的最优求解:拉格朗日乘数法和KKT条件
3.2 证明
高等数学同济大学第7版下册,


3.3 图像描述


- 从这里可以看出一个问题,对于最原始的曲面 z = f ( x , y ) = x 2 + y 2 z=f(x,y)=x^2+y^2 z=f(x,y)=x2+y2来说,如果以这个方程作为损失函数,求它的最小值,那么就是求这个曲面方程的最值。
- 肉眼看一下,都知道,最小值就是曲面的最下面,x和y都为0的时候最小。此时最小值只有一个点。
- 如果加上限制条件, x y = 1 xy=1 xy=1,再去求最值。则很明显,就是求这两个函数对应图像的所有交点的最值。
- 由于曲面(压扁)之后就是其等高线对应的同心圆,所以就变成下图这个样子。
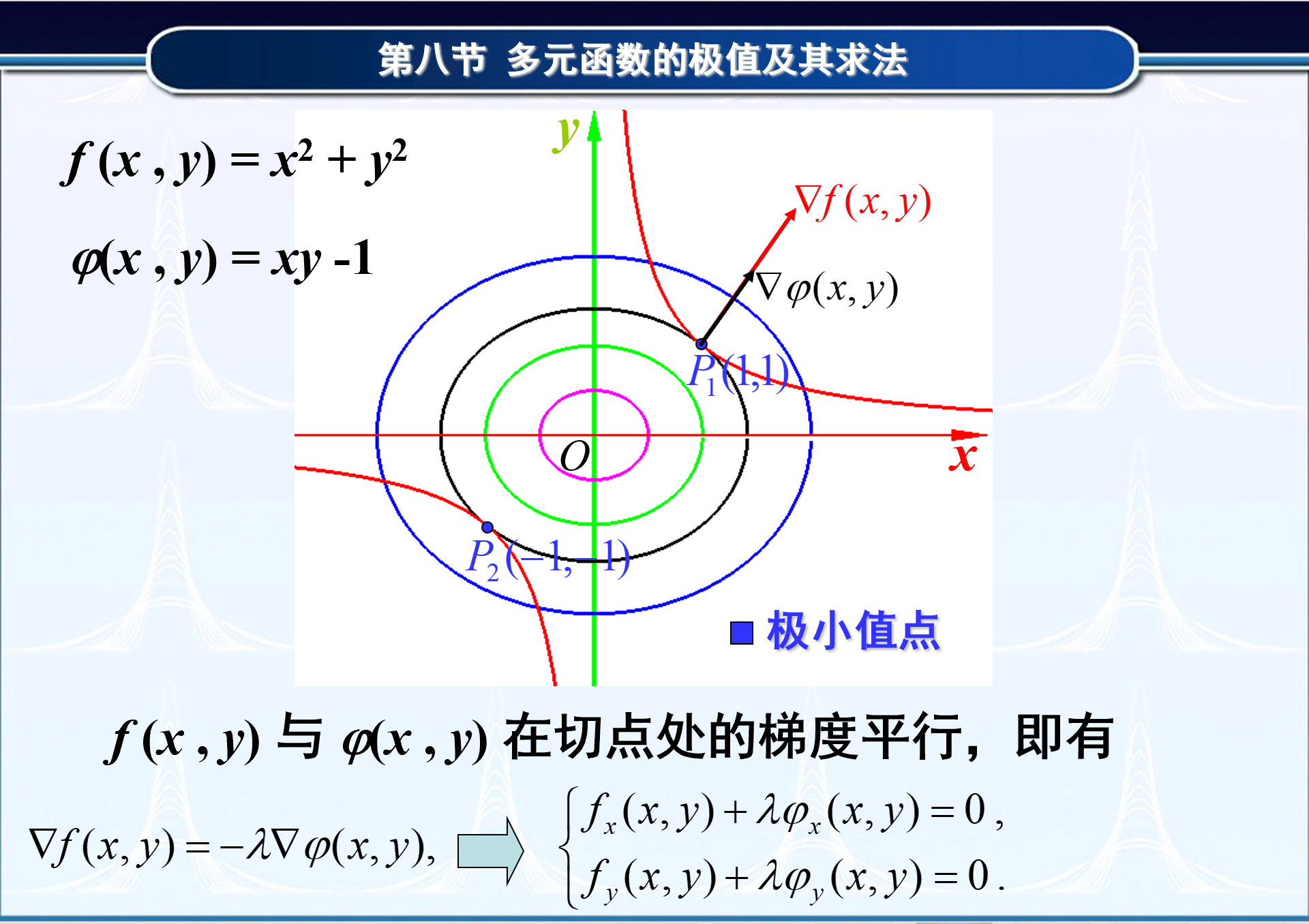
不难看出,添加限制条件之后,最值就有两个点。
- 所以李沐老师上面画同心圆和圆圈解释,为什么添加惩罚项之后最值向原点移动,其实没什么好解释的。。。
- 就是个简单的数学问题,数学公式变了而已,也不是什么拉力不拉力的。。。
这大概就是为什么网上的所有关于L2正则的都会画等高线的原因吧,都是看的稀里糊涂的,想不到原理竟然在高数里。。。
4. Q&A
实践中权重衰减值一般设置为多少会比较好?
-
一般L2正则设置 1 e − 2 , 1 e − 3 , 1 e − 4 1e^{-2}, 1e^{-3}, 1e^{-4} 1e−2,1e−3,1e−4,一般这三种值会比较常见,即0.01, 0.001还有0.0001。关于这里的数值表示,其实是python的科学计数法
-
L1范数相对来说能更好的降低无用的维度参数,降低复杂度
-
权重衰退效果会有一点点,但是不要特别寄希望于某个单一的手段,其实还有非常多别的控制模型复杂度的手段;如果模型非常复杂,权重衰退确实只会带来一点点效果。
为什么要把w往小的拉,如果W本身值比较大,那么权重衰退是不是会有反作用
- 这里要注意的是,最优值是数学上的,实际上不一定可以求到。
5. 更新
5.1 weight decay在代码中的具体表现形式
参照pytorch文档:SGD
下表是SGD梯度随机下降算法的描述(其实文档已经写得很清晰了):

其实使用的时候很简单,直接作为一个乘数乘在参数上。
关于完整的上面算法描述的解释,这里不做详细描述,写在另一个博客里:相关-39. SGD算法理解



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











