1. 平滑扩容
Motivation
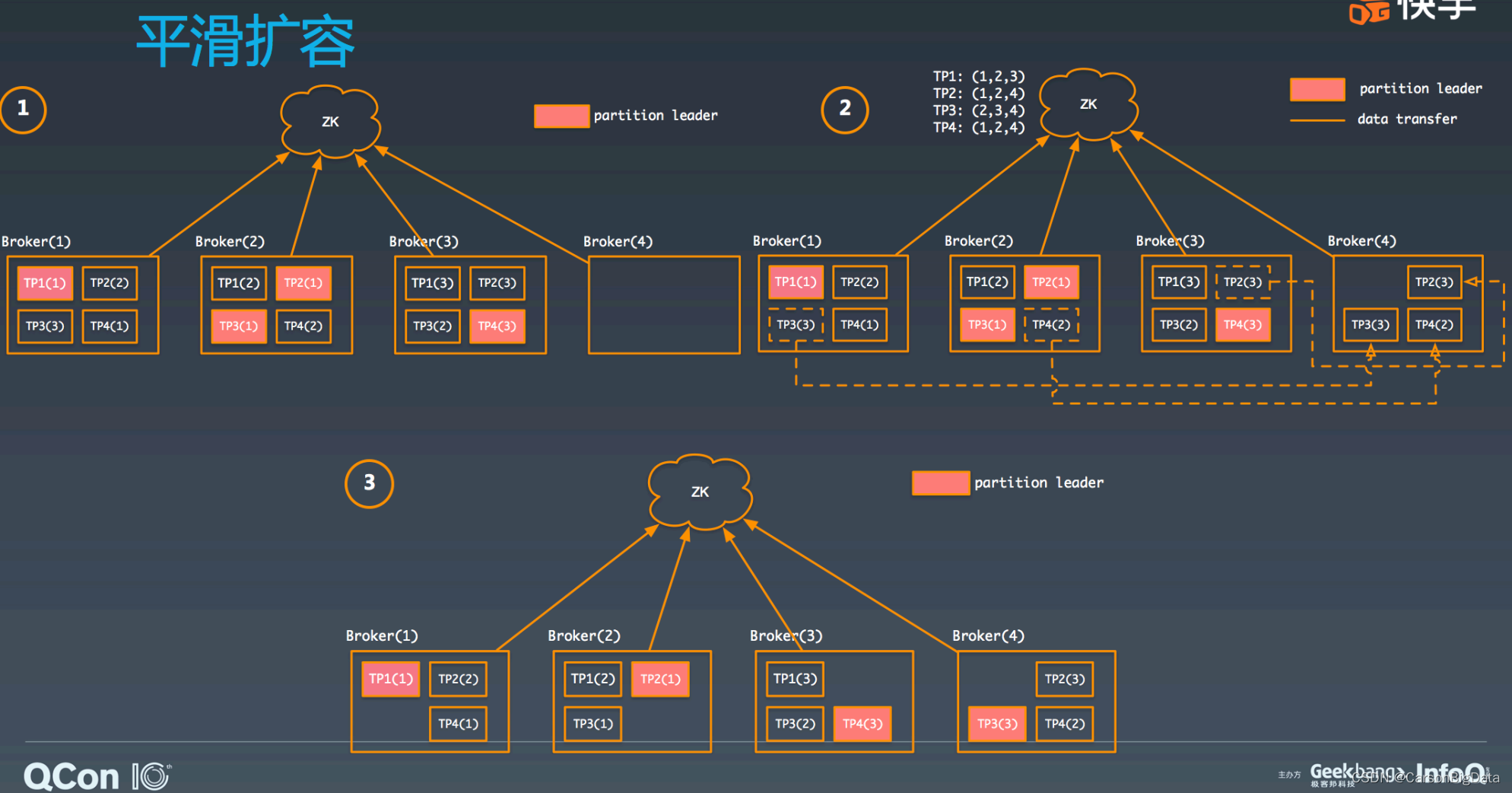
kafka扩容⼀台新机器的流程
假如集群有 3 个 broker,⼀共有 4 个 TP,每个 3 副本,均匀分布。现在要扩容⼀台机器,
新 broker 加⼊集群后需要通过⼯具进⾏ TP 的迁移。⼀共迁移 3 个 TP 的副本到新 broker
上。等迁移结束之后,会重新进⾏ leader balance,最终的 TP 分布如图所示:
从微观的⻆度看,TP 从⼀台 broker 迁移到另⼀个 broker 的流程是怎么样的呢?咱们来看 下 TP3 第三个副本,从 broker1 迁移到 broker4 的过程,如下图所示,broker4 作为 TP3 的 follower,从 broker1 上最早的 offffset 进⾏获取数据,直到赶上最新的 offffset 为⽌,新副 本被放⼊ ISR 中,并移除 broker1 上的副本,迁移过程完毕。
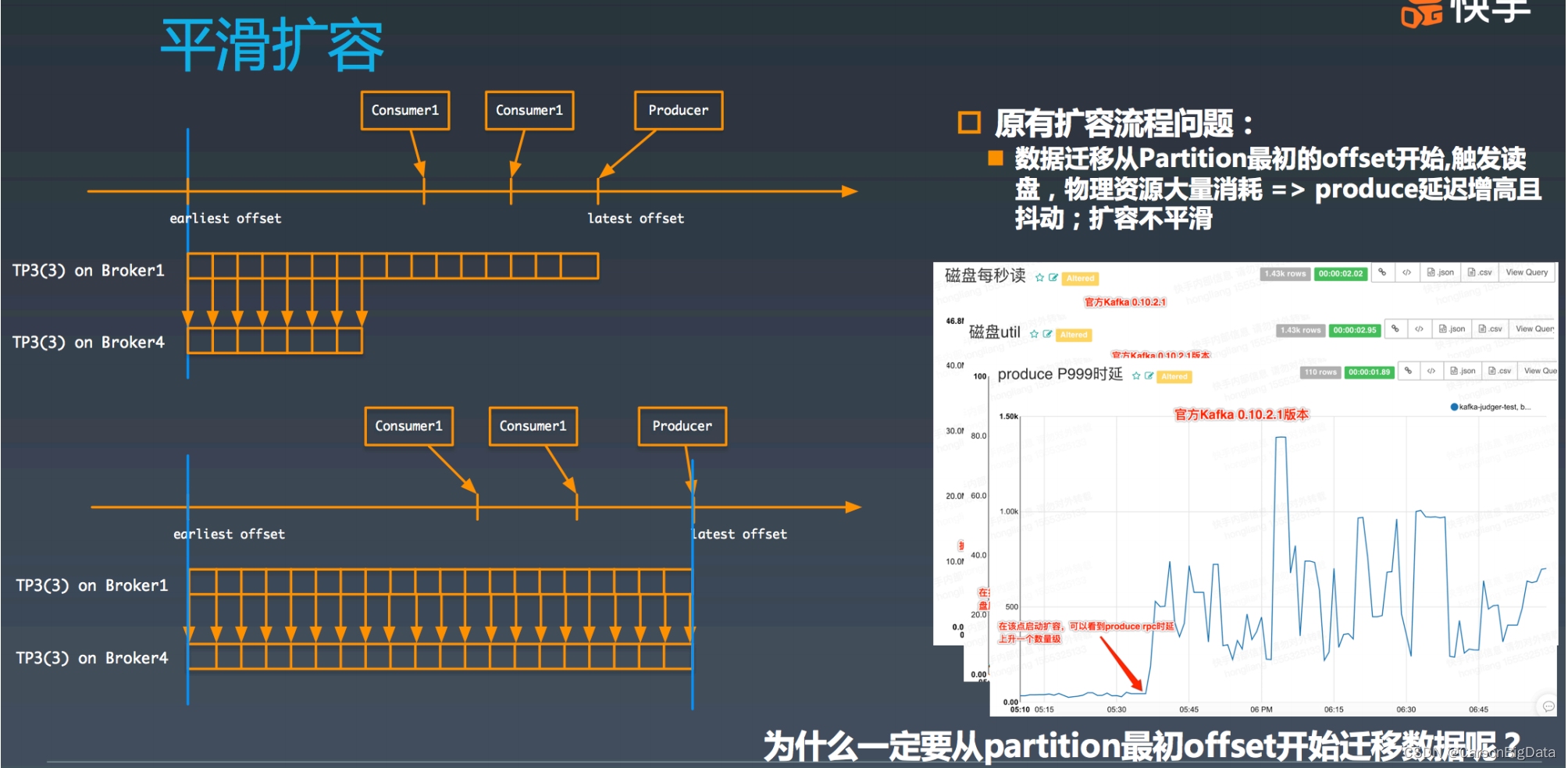
但在现有的扩容流程中存有如下问题:数据迁移从 TP3 的最初的 offset 开始拷⻉数据,这 会导致⼤量读磁盘,消耗⼤量的 I/O 资源,导致磁盘繁忙,从⽽造成 produce 操作延迟增 ⻓,产⽣抖动。所以整体迁移流程不够平滑。我们看下实际的监控到的数据。从中可以看到 数据迁移中, broker1 上磁盘读量增⼤,磁盘 util 持续打满,produce 的 P999 的延迟陡增,极其不稳定。
改进⽅案
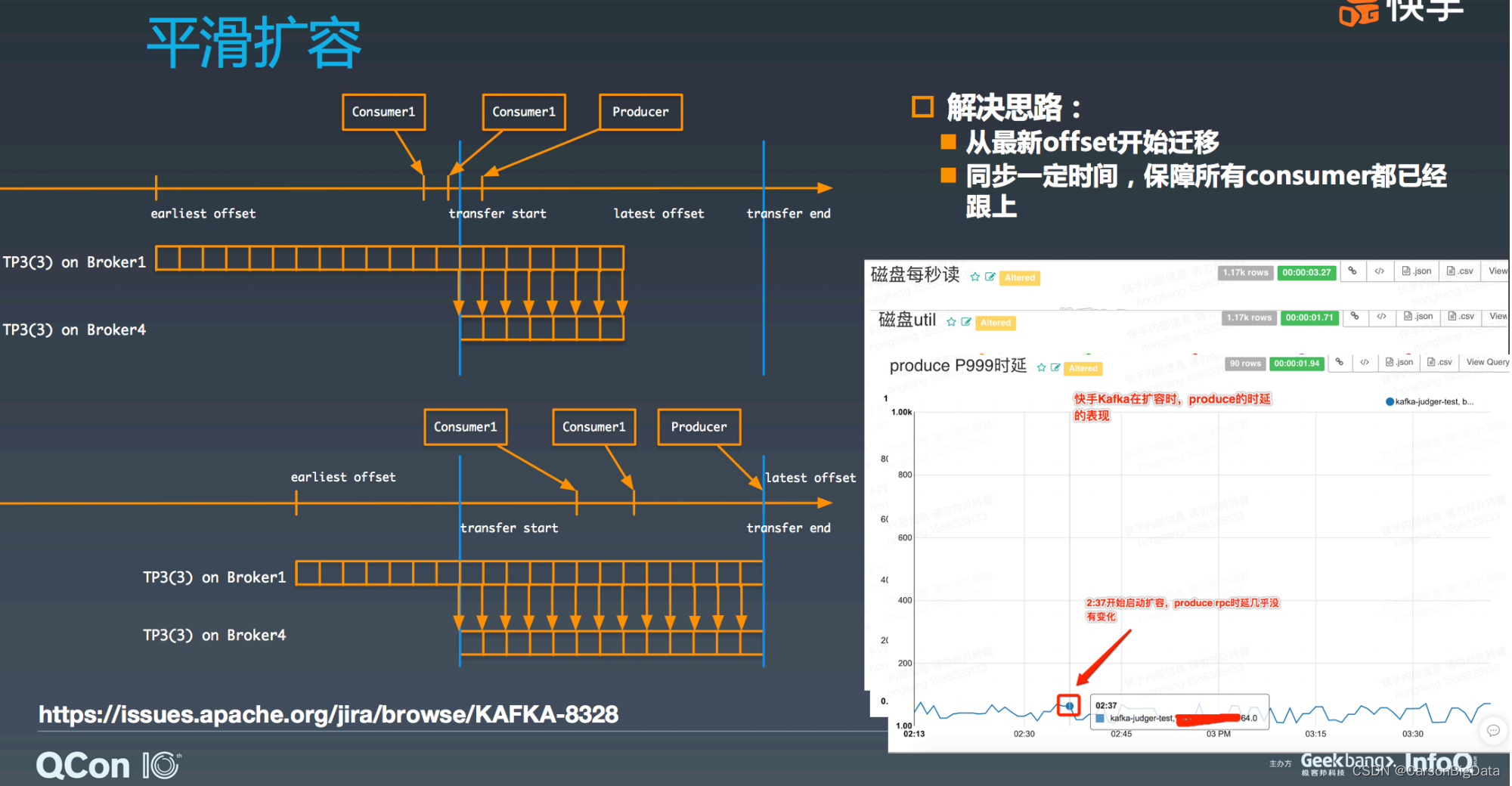
在迁移 TP 时,直接从 partition 最新的 offset 开始数据迁移,但是要同步保持⼀段时间,
主要是确保所有 consumer 都已经跟得上了。如图所示,再来看这个 TP3 的第三个副本从
broker1 迁移到 broker4 的过程。这次 broker4 直接从 broker1 最新的 offset 开始迁移,即
transfer start 这条竖线。此时,因为 consumer1 还没能跟得上,所以整个迁移过程需要保
持⼀段时间,直到 transfer end 这个点。这个时候,可以将 TP3 的新副本放到 ISR 中,同
时去掉 broker1 上的副本,迁移过程完毕。从这次的迁移过程中看,因为都是读最近的数
据,不会出现读⼤量磁盘数据的问题,仅仅多了⼀个副本的流量,基本对系统⽆影响。此
时,我们再来看下磁盘读量、磁盘 util、以及 produce 的延迟,从图中可知基本没有任何变
化。整体过程⾮常平滑,可以说通过这种⽅式很优雅地解决了 Kafka 平滑扩容问题,我们之
前也有在晚⾼峰期间做扩容的情况,但是从 Kafka 整体服务质量上看,对业务没有任何影
响。这个功能有⼀个 patch 可⽤: https://issues.apache.org/jira/browse/KAFKA-8328
这个⽅案存在的问题
1. 快⼿的这个patch是针对kafka 0.10.2.0版本,其他版本不⽀持,如果我们引⼊的话,需要针对⽣产环境上的版本进⾏代码修改
2. 设计的缺陷:
a)replica直接从最新的produce offset进⾏复制,⽆法保证kafka⼀致性语义(所有的副本数据完全⼀致),最新的replica缺失now - retention_ms这段时间的数据,如果consumer想要通过⾃定义offset来消费历史数据,可能会抛异常(当这个replica变成leader时);
b)replica从最新的produce offset进⾏同步,加⼊ISR的时机为 所有consumer offset全部⼤于起始同步offset,如果某个consumer group在此期间停⽌了消费测试⽤的group id),则会导致这个replica⼀直⽆法加⼊ISR
3. 这个patch只能在jdk 7 & scala 2.10编译通过,测试通过,在jdk 8 & scala 2.11环境下,测试⽆法通过
4. 社区的意⻅
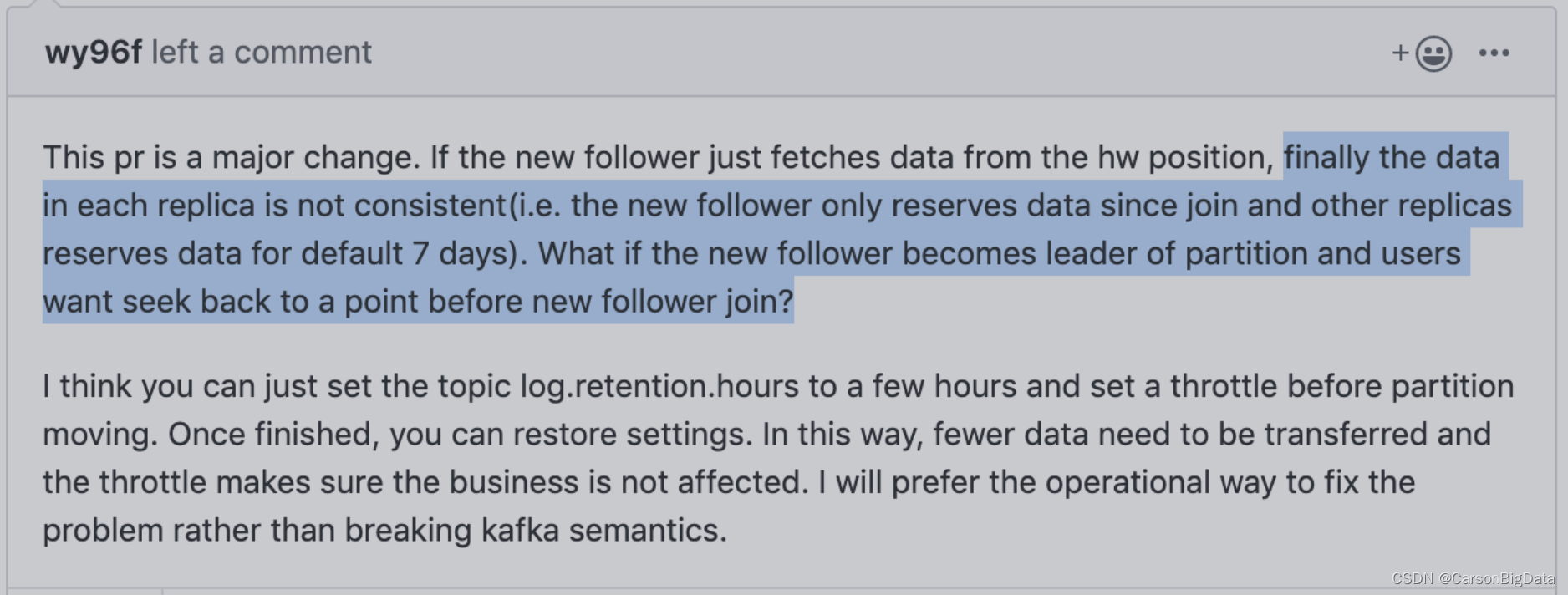
5. 快⼿针对这个改进提了⼀个KIP,但是这个KIP已经被删掉了,没有找到他们当时对这个improvement的讨论
6. 这个patch kafka社区没有approve
2. Kafka RPC 队列隔离
Motivation
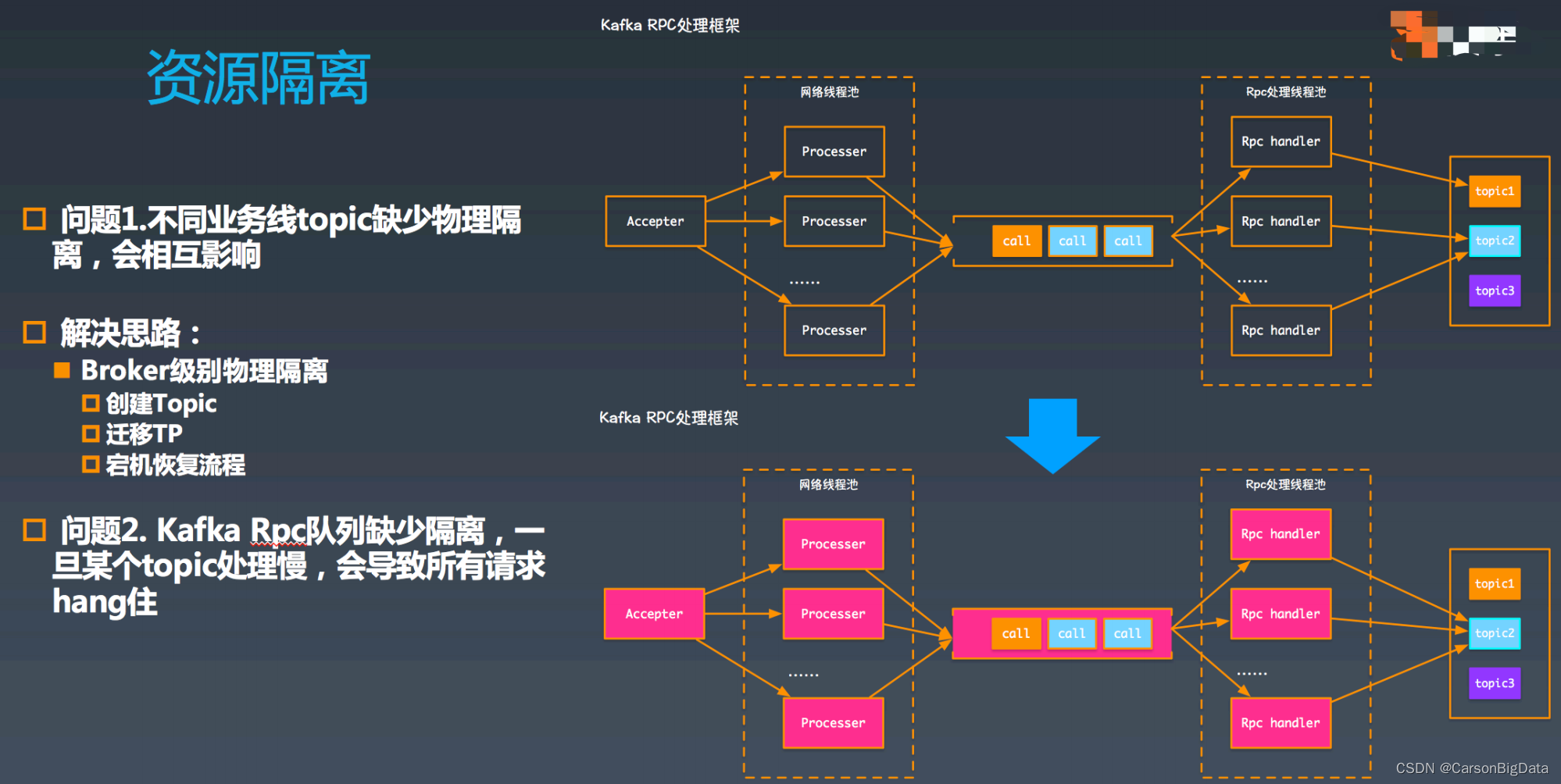
如图所示,Kafka RPC 框架中,⾸先由 accepter 从⽹络中接受连接,每收到⼀个连接,都
会交给⼀个⽹络处理线程(processer)处理,processor 在读取⽹络中的数据并将请求简单
解析处理后,放到 call 队列中,RPC 线程会从 call 队列中获取请求,然后进⾏ RPC 处理。
此时,假如 topic2 的写⼊出现延迟,例如是由于磁盘繁忙导致,则会最终将 RPC 线程池打
满,进⽽阻塞 call 队列,进⽽打满⽹络线程池,这样发到这个 broker 的所有请求都没法处
理了。
改进⽅案
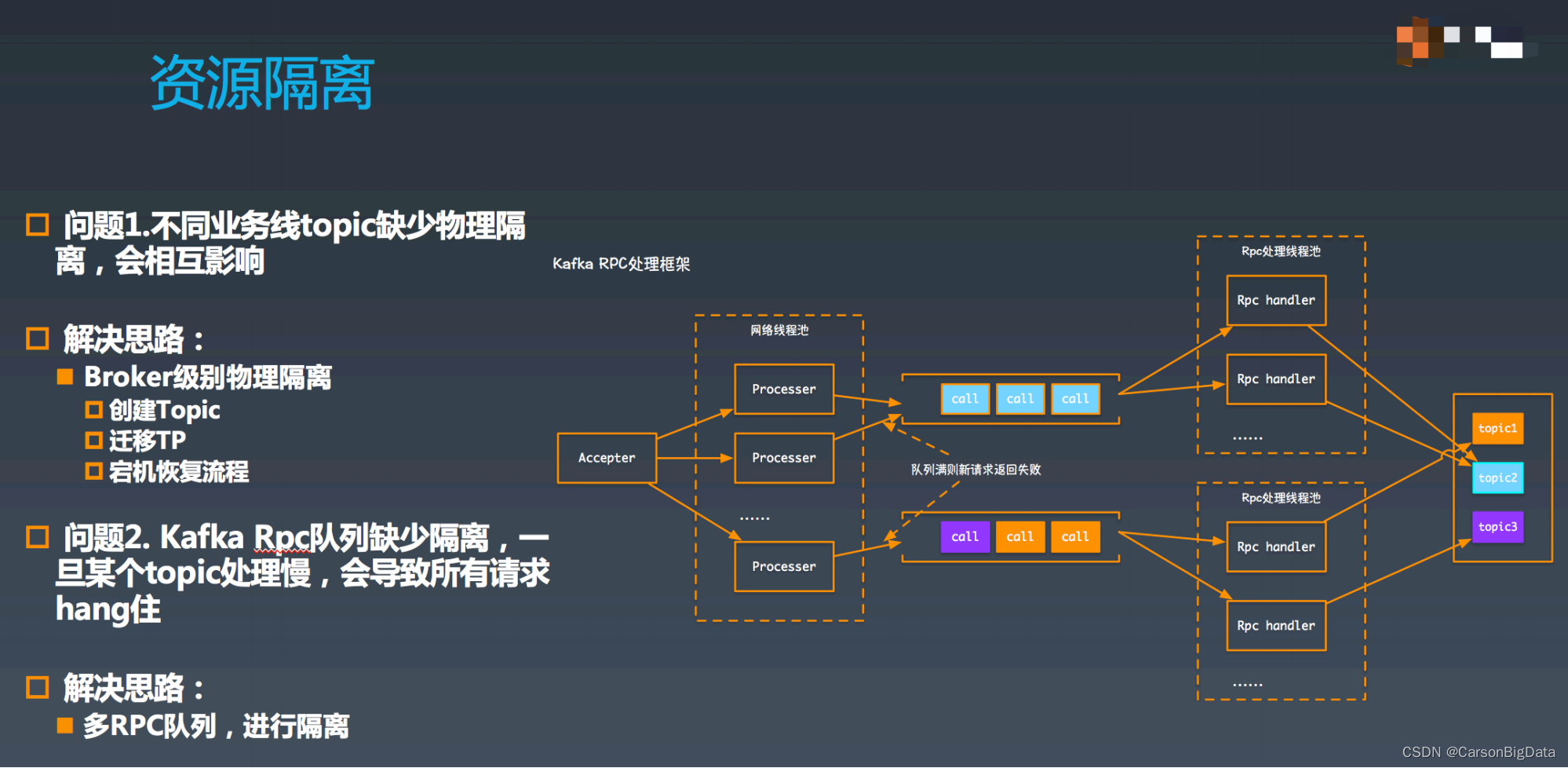
解决这个问题的思路也⽐较直接,需要按照控制流、数据流分离,且数据流要能够按照
topic 做隔离。⾸先将 call 队列按照拆解成多个,并且为每个 call 队列都分配⼀个线程池。
在 call 队列的配置上,⼀个队列单独处理 controller 请求的队列(隔离控制流),其余多个
队列按照 topic 做 hash 的分散开(数据流之间隔离)。如果⼀个 topic 出现问题,则只会
阻塞其中的⼀个 RPC 处理线程池,以及 call 队列。这⾥还有⼀个需要注意的是 processor
在将请求放⼊ call 队列中,如果发现队列已满,则需要将请求⽴即失败掉(否则还是会被阻
塞)。这样就保障了阻塞⼀条链路,其他的处理链路是畅通的。
3. Cache改造
Motivation
我们都知道,Kafka 之所以有如此⾼的性能,主要依赖于 page cache,producer 的写操
作,broker 会将数据写⼊到 page cache 中,随后 consumer 发起读操作,如果短时间内
page cache 仍然有效,则 broker 直接从内存返回数据,这样,整体性能吞吐⾮常⾼。
但是由于 page cache 是操作系统层⾯的缓存,难于控制,有些时候,会受到污染,从⽽导
致 Kafka 整体性能的下降。我们来看 2 个例⼦:
第⼀个 case:consumer 的 lag 读会对 page cache 产⽣污染。
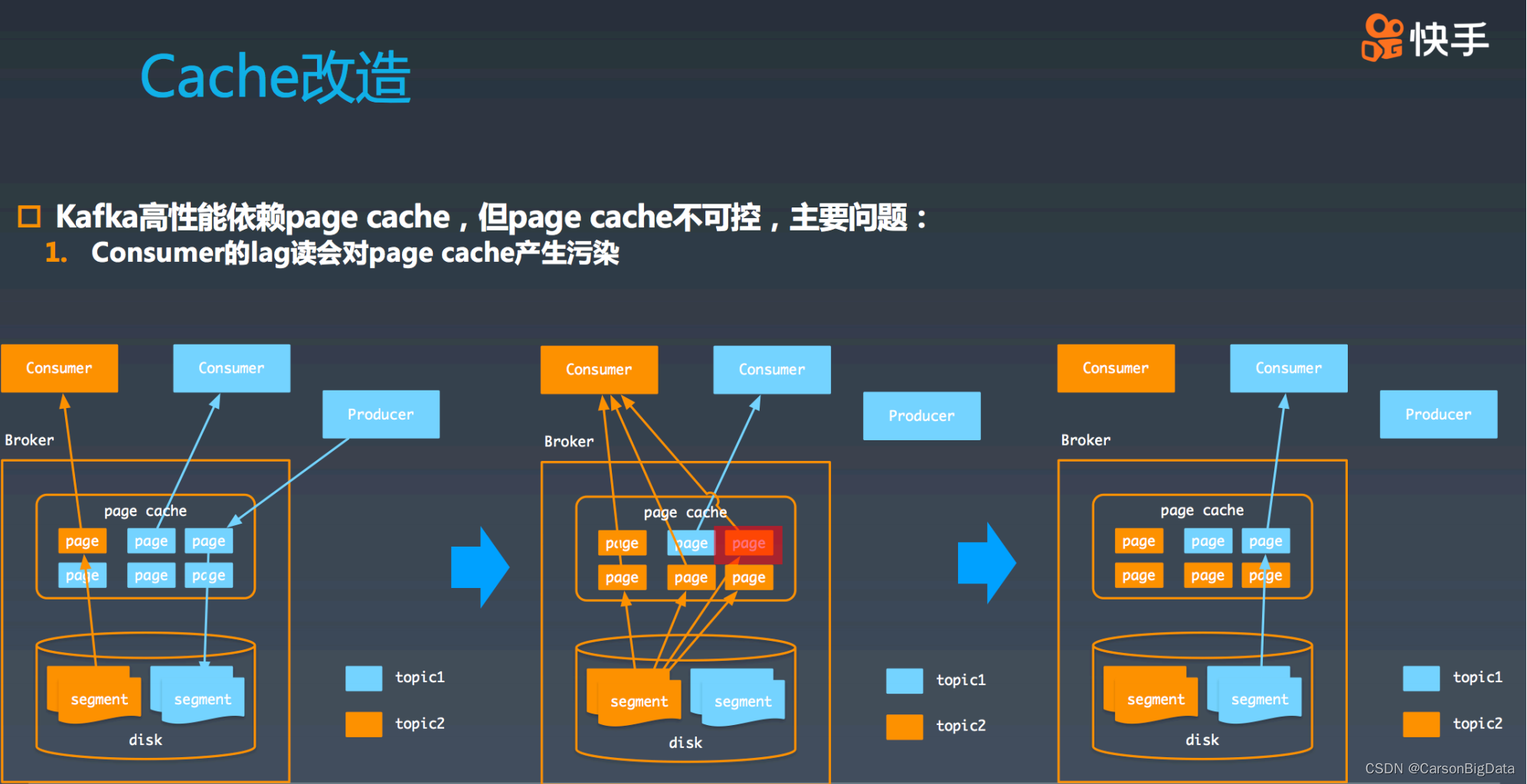
如图所示,假如有 2 个 consumer,1 个 producer。其中,蓝⾊ producer 在⽣产数据,蓝
⾊ consumer 正在消费数据,但是他们之间有⼀定的 lag,导致分别访问的是不同的 page
cache 中的 page。如果⼀个橙⾊ consumer 从 topic partition 最初的 offffset 开始消费数据
的话,会触发⼤量读盘并填充 page cache。其中的 5 个蓝⾊ topic 的 page 数据都被橙⾊
topic 的数据填充了。另外⼀⽅⾯,刚刚蓝⾊ producer ⽣产的数据,也已经被冲掉了。此
时,如果蓝⾊ consumer 读取到了蓝⾊ producer 刚刚⽣产的数据,它不得不再次将刚刚写
⼊的数据从磁盘读取到 page cache 中。综上所述,⼤ lag 的 consumer 会造成 cache 污
染。在极端情况下,会造成整体的吞吐下降。
第⼆个 case:follower 也会造成 page cache 的污染。
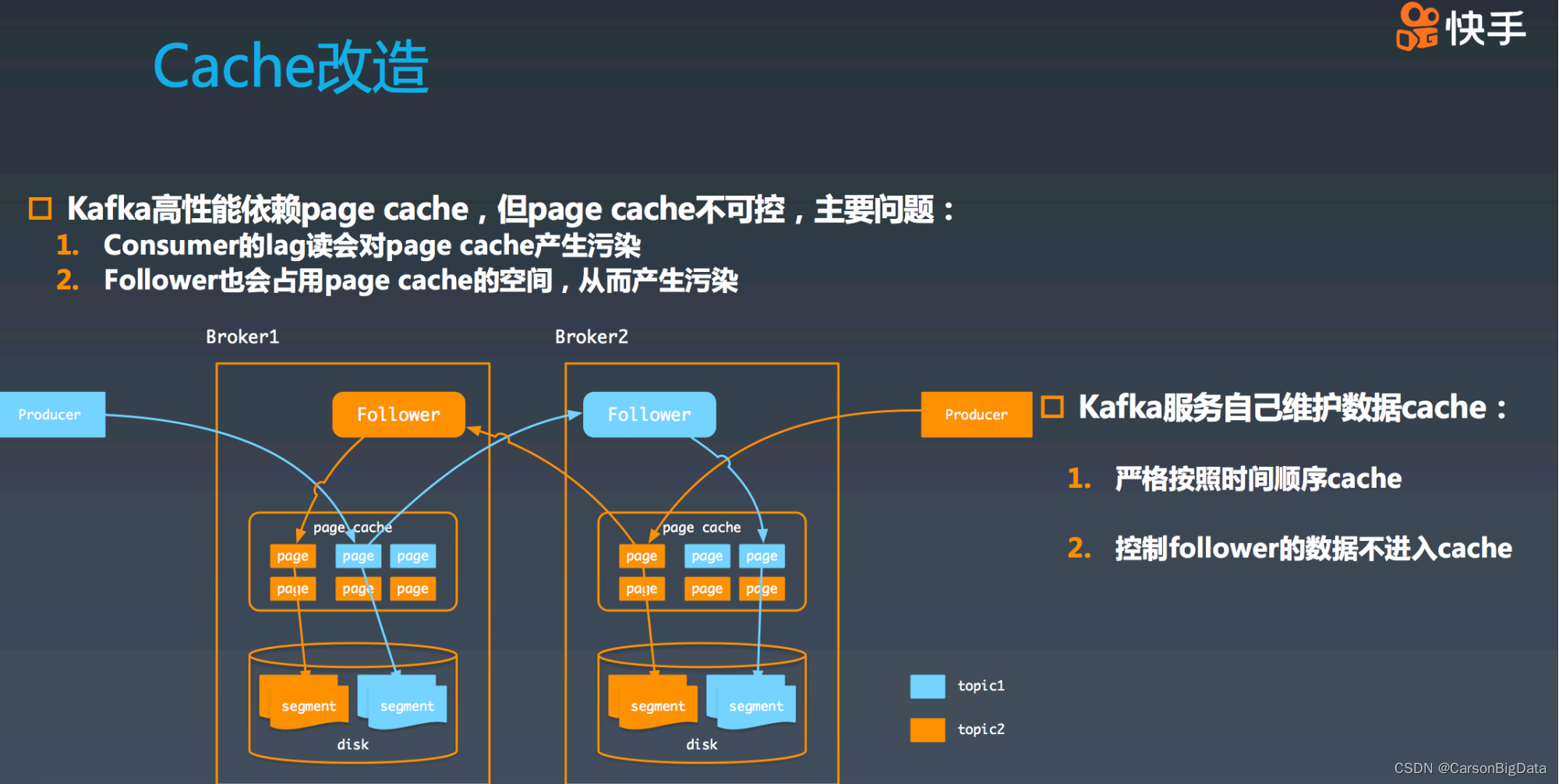
在图中 broker1 机器内部,其中 page cache 中除了包括蓝⾊ producer 写⼊的数据之外,
还包括橙⾊ follower 写⼊的数据。但是橙⾊ follower 写⼊的数据,在正常的情况下,之后不
会再有访问,这相当于将不需要再被访问的数据放⼊了 cache,这是对 cache 的浪费并造
成了污染。所以,很容易想到 Kafka 是否可以⾃⼰维护 cache 呢?⾸先,严格按照时间的
顺序进⾏ cache,可以避免异常 consumer 的 lag 读造成的 cache 污染。其次,控制
follower 的数据不进⼊ cache,这样阻⽌了 follower 对 cache 的污染,可以进⼀步提升
cache 的容量。
改进⽅案
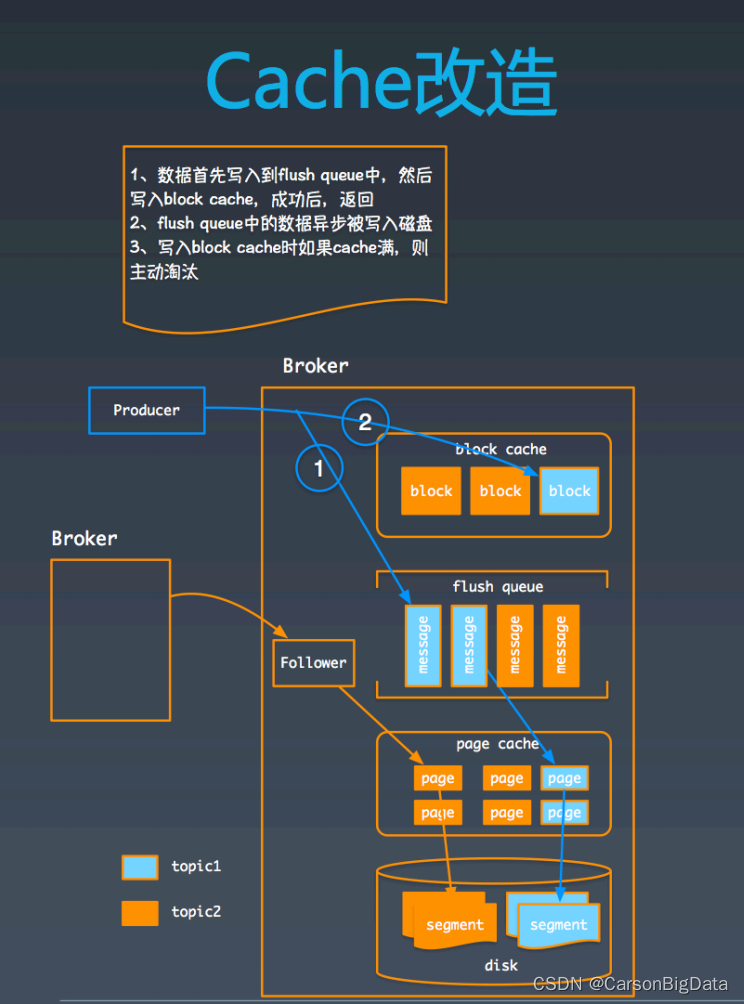
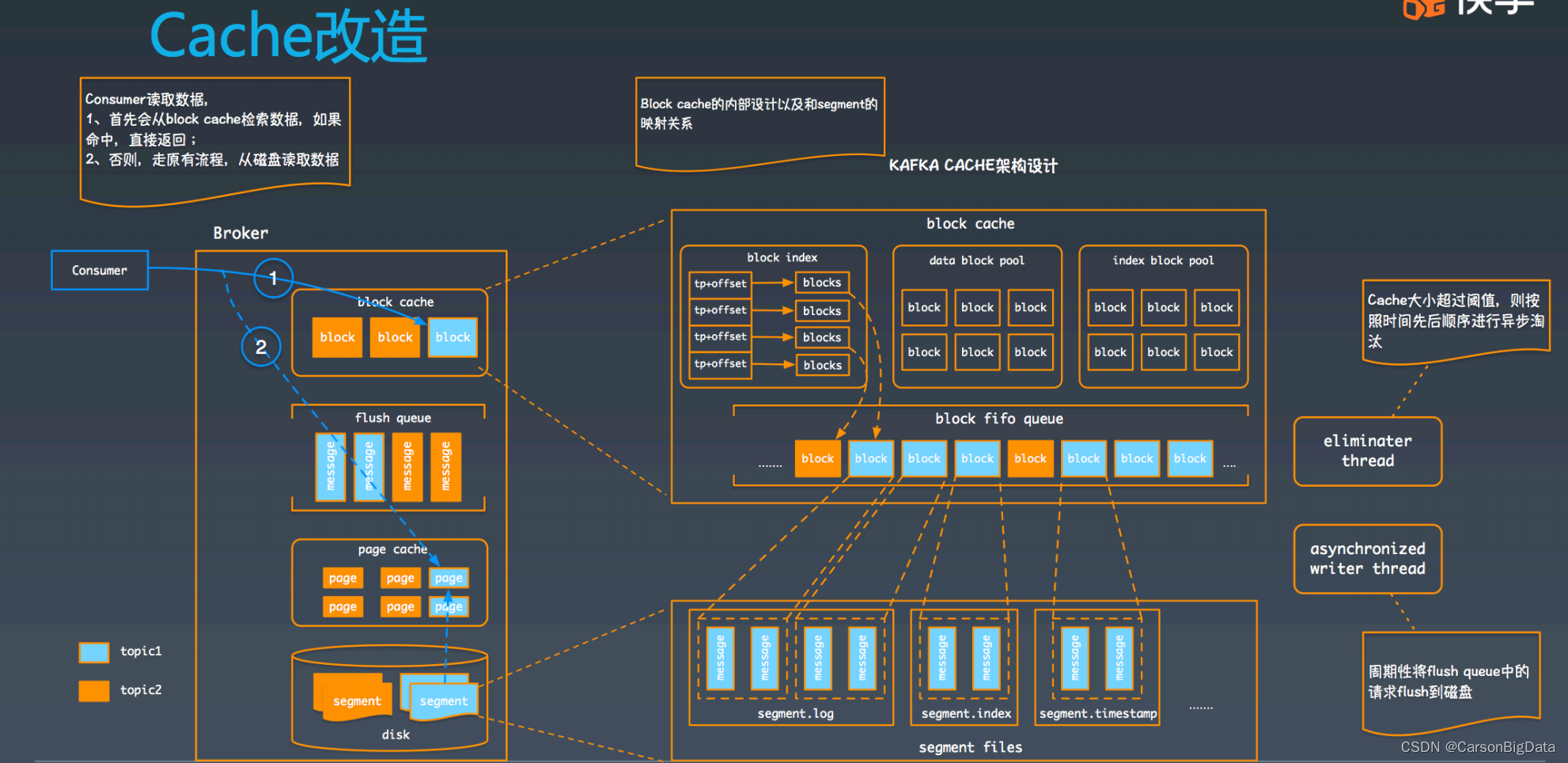
我们在 broker 中引⼊了两个对象:⼀个是 block cache;另⼀个是 flflush queue。Producer
的写⼊请求在 broker 端⾸先会被以原 message 的形式写⼊ flflush queue 中,之后再将数据
写⼊到 block cache 的⼀个 block 中,之后整个请求就结束了。在 flflush queue 中的数据会
由其他线程异步地写⼊到磁盘中(会经历 page cache 过程)。⽽ follower 的处理流程保持
和原来⼀致,从其他 broker 读到数据之后,直接把数据写到磁盘(也会经历 page
cache)。这种模式保证了 block cache 中的数据全都是 producer 产⽣的,不会被 follower
污染。
对于 consumer ⽽⾔,在 broker 接到消费请求后,⾸先会从 block cache 中检索数据,如
果命中,则直接返回。否则,则从磁盘读取数据。这样的读取模式保障了 consumer 的
cache miss 读并不会填充 block cache,从⽽避免了产⽣污染,即使有⼤ lag 的 consumer
读磁盘,也仍然保证 block cache 的稳定。
接下来,我们看下 block cache 的微观设计,整个 block cache 由 3 个部分组成:
第⼀部分:2 类 block pool,维护着空闲的 block 信息,之所以分成 2 类,主要是因
segment 数据以及 segment 的索引⼤⼩不同,统⼀划分会导致空间浪费;
第⼆部分:先进先出的 block 队列,⽤于维护 block ⽣产的时序关系,在触发淘汰时,会优
先淘汰时间上最早的 block;
第三部分:TP+offffset 到有效 blocks 的索引,⽤于快速定位⼀个 block。⼀个 block 可以看
做是 segment 的⼀部分。segment 数据以及 segment 索引和 block 的对应关系如图所示。
最后,还有两个额外的线程:
eliminater 线程,⽤于异步进⾏ block cache 淘汰,当然,如果 produce 请求处理时,发现
block cache 满也会同步进⾏ cache 淘汰的;
异步写线程,⽤于将 flflush queue 中的 message 异步写⼊到磁盘中。
这个就是 Kafka cache 的整体设计,可以看出,已经很好地解决了上述的两个对 cache 污
染的问题了。
性能测试
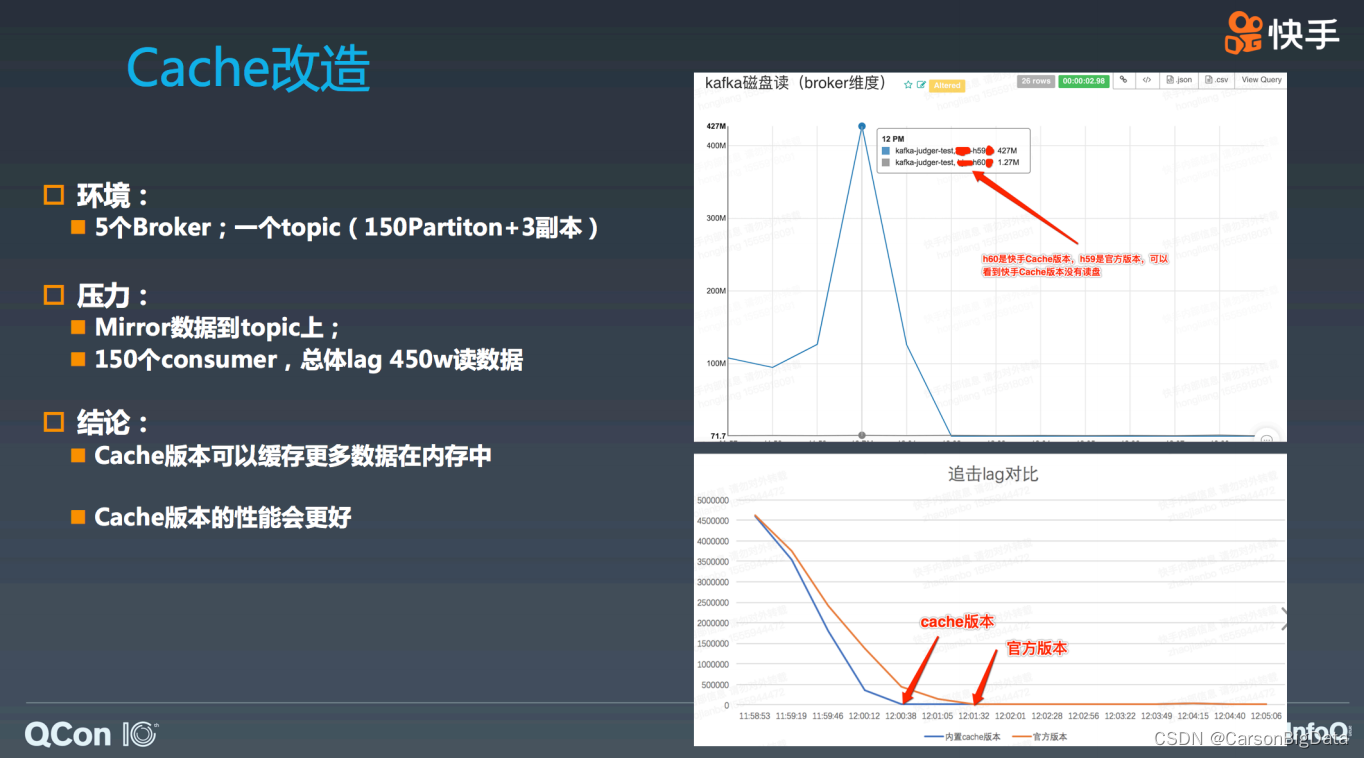
我们搭建了 5 个 broker 的集群,其中⼀个换成了 Kafka cache 的版本。并创建了⼀个 150
个 partition 的 topic,3 副本。所以算上副本,⼀共有 450 个 partition,每台机器上 90 台
TP。之后我们 Mirror 了⼀个线上的流量数据,并启动 150 个 consumer,以总体 lag 450w
条数据开始读。
从图中可以看出,原始版本在这种情况下会造成⼤量的磁盘读,⽽ Kafka cache 版本没有任
何磁盘读取操作,这说明 Kafka cache 版本可以 cache 更多的有效数据,这点是排除了
follower 造成的污染,经过精细化统计,发现 Kafka cache 有效空间刚好为原版本的 2 倍
(正好和同⼀台 broker 中 TP 为 leader 和 follower 的数量⽐⼀致)。从恢复的时间上看,
由于排除了读磁盘以及多个 consumer 之间读可能会 cache 产⽣的污染,Kafka cache 的版
本也⽐原有版本速度要快了 30%。
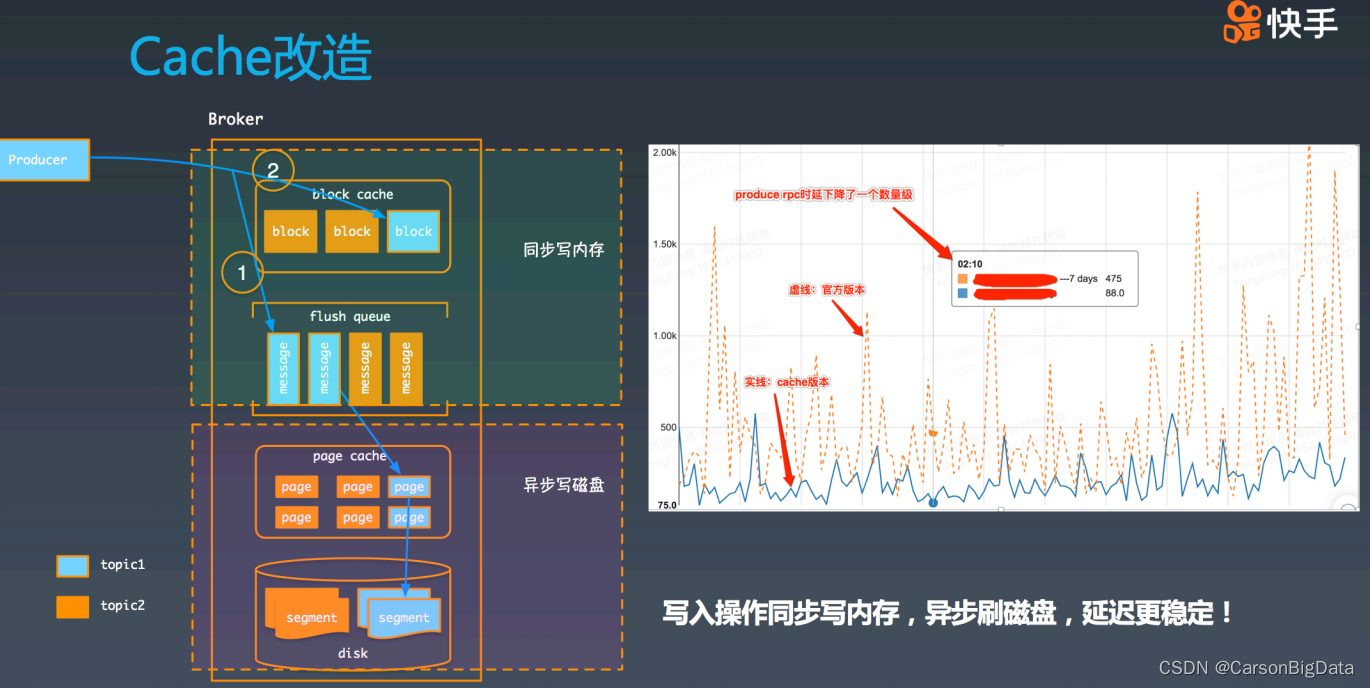
除此之外,再看下改进后的 broker,从这个图中可以看出,produce 整个写⼊过程,先是同
步写⼊内存,然后再被异步刷⼊磁盘。虽然 page cache 的模式也是类似这种,但是 pagecache 会存在⼀定不稳定性(可能会触发同步写盘)。这个是我们上线 Kafka cache 版本前
后的 produce p999 的延迟对⽐。从图中可以看到:Kafka cache 版本⽐原来版本的延迟低
了很多,且稳定性有极⼤改进。
引⼊该⽅案存在的问题
1. ⽬前快⼿只提出了⼀个⾃⼰管理Cache的⽅案,没有公开源码,我们需要⾃⼰写代码实
现
2. 我们集群Kafka的版本⽬前不统⼀,在实现这个⽅案之前需要统⼀Kafka版本






















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









