




 本文提出了一种针对稀疏图数据库的高效相似性搜索算法,通过构建k-邻接树索引,实现快速筛选候选集。算法结合图分解与子树方法,利用下界公式过滤大量非匹配图,显著提升搜索效率。
本文提出了一种针对稀疏图数据库的高效相似性搜索算法,通过构建k-邻接树索引,实现快速筛选候选集。算法结合图分解与子树方法,利用下界公式过滤大量非匹配图,显著提升搜索效率。
文章简介:
- 文章标题: Efficiently Indexing Large Sparse Graphs for Similarity Search
- TKDE 2010
- link(提示:校内传送门)
文章正文总结:
为什么要构建类似字符串的Q-GRAM的邻居树?从直观上理解,如果俩个图之间的编辑操作越少,那么就有相当多的邻居树是保持不变的。言外之意是,有很多公共的邻居树。文中描述如下:

The lower bound lemma guarantees the absence of false negatives 文章的false negatives是什么意思?
After that, we store them in the first layer of the lattice, and then relabel each vertex in the graph set by the ID of their 1-AT是什么意思?在1邻居树的构建时候,给每个1邻居树一个唯一的ID,在2邻居树构建时候,使用1邻居树的ID,并且构建完一个2邻居树,为其分配一个唯一的ID
 读图相似度的文章,经常遇到受到Q-gram[2]模型的启发,提出新的模型的方法。网络上的解释一般都是n-gram的方法,原始方法在一个1948年的文献中提到过,有时间还得细细研究。
读图相似度的文章,经常遇到受到Q-gram[2]模型的启发,提出新的模型的方法。网络上的解释一般都是n-gram的方法,原始方法在一个1948年的文献中提到过,有时间还得细细研究。
算法1 算法2

为了使用下界的公式,需要计算查询图
Q
Q
Q和图集中
G
G
G的公共
k
−
a
d
j
a
c
e
n
t
k-adjacent
k−adjacent,这里为了方便解释,假说
k
=
2
k=2
k=2。则需要建立俩个索引表
i
n
d
Q
,
i
n
d
G
ind_{Q},ind_{G}
indQ,indG,表的格式如上所示。分别比较俩个索引表的
(
3
,
4
)
(3,4)
(3,4)的两列,就可以计算出俩个图的公共邻居树
2
−
a
d
j
a
c
e
n
t
2-adjacent
2−adjacent。如果图
G
G
G满足下界的公式,则图
G
G
G是候选集,否则不加入候选集。
问题
- 每一个图都要建立一个table吗?在没有进行优化之前是的
- 算法1中 W V V W_V{V} WVV符号意思?
如何维护索引?
如果图数据库中有1000个图,我们是不是要创建1000个latttice,然后再建立1000个index_table?这种成本会很大,因此我们需要维护索引。
索引的维护需要首先表现在lattice上面,因为有了lattice才会有对应的索引表。作者在文章中提出在每个k-adjacent上使用计数器。使用计数器去记录这k-adjacent出现的次数,如果在lattice中插入新的k-ad树,就加1,后续所有插入到这颗树上的操作都加1;当遇到删除操作的时候,就减去1。如果计数器的值是1,并且遇到了删除的情况,那么这颗k-ad树就应该从lattice中删除。如果按照这种逻辑,在图集上缓慢的搜索过程就可以避免了。
使用倒排索引
如果我们将图集中的每个图都视为以k-AT为关键词的关键词集,则可以将k-AT索引组织为倒排索引,以避免缓慢的顺序搜索
We use their IDs as the keywords and record their references in the graph set into the inverted list of this keyword
我们将其ID用作关键字,并将其图集中的引用记录在该关键字的反向列表中
During a query processing, we first generate all the -ATs of the query and use the ID of the -AT as the keywords to pick up specific inverted lists in the inverted table, then execute a join operation on those inverted lists using (the Probe-Count Algorithm)
在查询处理期间,我们首先生成查询的所有k-AT,然后将k-AT的ID作为关键字来使用反向表中的特定反向列表,然后使用Probe 计数[参考文献25]算法.

实验
数据集
1.NCI/NIH AIDS Antiviral Screen data set
2.Protein Interaction Data set DIP (short for Database
of Interacting Proteins).
对比方法
实验角度
1.评测索引的性能


2. 索引查询、过滤的能力
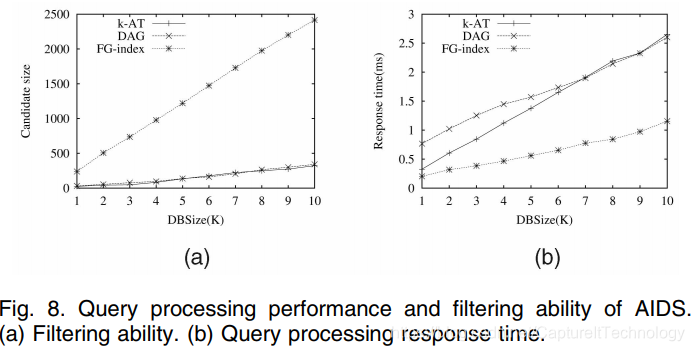
3. 索引的可伸缩性

文章总结
1. 解决问题:
在稀疏图数据库中进行相似度搜索,搜索结果是满足编辑阈值的结果集。提出了一个下界的公式,,用来filter查询图Q的候选集:
∣
k
−
A
T
S
(
g
1
)
∩
k
−
A
T
S
(
g
2
)
∣
≥
∣
V
(
g
1
)
∣
−
Δ
(
g
1
,
g
2
)
∗
2
(
δ
(
g
1
)
−
1
)
k
−
1
|k-ATS(g_1)\cap k-ATS(g_2)|\\\geq |V(g_1)|-\Delta(g_1,g_2)*2(\delta(g_1)-1)^{k-1}
∣k−ATS(g1)∩k−ATS(g2)∣≥∣V(g1)∣−Δ(g1,g2)∗2(δ(g1)−1)k−1
其中,k是邻居树的深度,
δ
\delta
δ是图最大的度,K-ATS()表示为k邻居树的集合,
Δ
(
g
1
,
g
2
)
\Delta(g_1,g_2)
Δ(g1,g2)每个搜索算法需要给定图编辑阈值。
举个例子,假如查询图
Q
Q
Q有关信息为
∣
V
Q
∣
=
100
,
δ
(
Q
)
=
2
,
|V_Q|=100,\delta (Q)=2,
∣VQ∣=100,δ(Q)=2,数据库有一个图
g
g
g的信息为
∣
3
−
K
A
T
(
Q
)
∩
3
−
K
A
T
(
g
)
∣
=
30
|3-{KAT(Q)} \cap3-KAT(g)|=30
∣3−KAT(Q)∩3−KAT(g)∣=30,那么经过上面不等式计算,图
g
g
g不满足不等式,所以这个图被过滤掉。
2. 使用的方法:
前人一般解决图相似度查询有俩种方法,一种是通过频繁子树的特征挖掘,一种是通过图分解的方法。但是俩者都有缺点。前者依赖挖掘频繁子树时选取的特征,并且在挖掘出频繁子树之后需要进行高成本的构建和维护成本;后者在图分解中不能利用图中经常存在的信息(frequency information)提高图相似度搜索的效率。而本文使用第二种方法,但是在策略上有改进。通过把每个图分解为k-adjacent树,分解的结构由k-AT进行索引。文中引理 ∣ k − A T S ( g 1 ) ∩ k − A T S ( g 2 ) ∣ ≥ ∣ V ( g 1 ) ∣ − Δ ( g 1 , g 2 ) ∗ 2 ( δ ( g 1 ) − 1 ) k − 1 |k-ATS(g_1)\cap k-ATS(g_2)|\\\geq |V(g_1)|-\Delta(g_1,g_2)*2(\delta(g_1)-1)^{k-1} ∣k−ATS(g1)∩k−ATS(g2)∣≥∣V(g1)∣−Δ(g1,g2)∗2(δ(g1)−1)k−1的下届排除了 " f a l s e n e g a t i v e s " "false negatives" "falsenegatives"的存在。虽然提出的方法不仅仅使用了图分解的方法,还使用了基于子树的方法,但是可以通过调整k的值去控制分解的结果,同时可以充分利用分解子图的经常存在的信息去提高筛选阶段的效率。
3. 文章不足:
3.1 我的看法:
文章中是通过构建索引
k
−
a
d
j
a
c
e
n
t
k-adjacent
k−adjacent树,用来进行过滤筛选不符合下界公式的图数据。也是属于一种过滤-验证的思想,但是这种树的使用范围只局限与稀疏图。对于非稀疏图,文章的讨论不多,只是强调了
k
=
1
k=1
k=1时候可以满足算法运行的要求。对于非稀疏图,文章通过论证说明了
∣
k
−
A
T
S
(
g
1
)
∩
k
−
A
T
S
(
g
2
)
∣
≥
∣
V
(
g
1
)
∣
−
Δ
(
g
1
,
g
2
)
∗
2
(
δ
(
g
1
)
−
1
)
k
−
1
|k-ATS(g_1)\cap k-ATS(g_2)|\\\geq |V(g_1)|-\Delta(g_1,g_2)*2(\delta(g_1)-1)^{k-1}
∣k−ATS(g1)∩k−ATS(g2)∣≥∣V(g1)∣−Δ(g1,g2)∗2(δ(g1)−1)k−1的有效性;其次,k值的选取必须依靠实验的经验获得,无理论分析,如果给定数据集分析不透彻,必然增加应用时成本。同时,在文章"Graph Similarity Search with Edit Distance Constraint inLarge Graph Databases"中,作者提出,当k的值稍微一大,比如大于2,任何编辑操作将会影响非常多的k-adjacent树,这也说明了下界很loose。
3.2 作者提出的不足:
3.2.1 文章的下届估计很松散:
∣
k
−
A
T
S
(
g
1
)
∩
k
−
A
T
S
(
g
2
)
∣
≥
∣
V
(
g
1
)
∣
−
Δ
(
g
1
,
g
2
)
∗
2
(
δ
(
g
1
)
−
1
)
k
−
1
|k-ATS(g_1)\cap k-ATS(g_2)|\\\geq |V(g_1)|-\Delta(g_1,g_2)*2(\delta(g_1)-1)^{k-1}
∣k−ATS(g1)∩k−ATS(g2)∣≥∣V(g1)∣−Δ(g1,g2)∗2(δ(g1)−1)k−1。原因是因为文章一直都假设在一个图中,编辑操作
G
E
O
GEO
GEO总是以相同的概率作用在顶点和边上。但事实上,由于图的不平衡性,编辑操作覆盖顶点和边的概率不同。因此,为了收缩下界,可以使用泊松分布模型;
3.2.2 在过滤阶段,
k
−
a
d
j
a
c
e
n
t
k-adjacent
k−adjacent作为一种树模型,相比于图模式它的过滤性能还是很弱,这个缺点导致了结果的误报。因此,使用其他方法15去解决这个问题;
在文章多层索引中提到:通过分别从g∈G和查询图q计算最小的k-AT树数,提出了基于计数的GED下界。但是,如果g或q具有高阶顶点或GED阈值τ大,则该GED下界将变得松散,从而使k-AT仅适用于非常稀疏的图。
参考文献:
-
TreePi: A Novel Graph Indexing Method
文章参考文献[13] S. Zhang, M. Hu, and J. Yang, “Treepi: A Novel Graph Indexing Method,” Proc. IEEE 23rd Int’l Conf. Data Eng., pp. 966-975, 2007. 文章中提出了一种基于频繁特征子树挖掘的索引方法 T r e e P i TreePi TreePi去第一次减少数据库的搜索范围,同时使用了 C e n t e r D i s t a n c e C o n s t r a i n t Center Distance Constraint CenterDistanceConstraint方法第二次减小了搜素空间,最后使用新颖的子图同构测试比较数据库中剩下图的相似度。
1.1 缺点:方法的有效性和效率都取决于所选择的特征。
1.2 频繁子树挖掘的算法时间长,很难构建和维护 -
参考文献15“Graph Indexing: Tree + DeltaGraph,” P. Zhao, J.X. Yu, and P.S. Yu, Proc. 33rd Int’l Conf. Very Large Data Bases, pp. 938-949,2007.
-
参考文献18 “Efficient Query Processing on Graph Databases” J. Cheng, Y. Ke, W. Ng, , ACM Trans. Database Systems, vol. 34, no. 1, pp. 1-44, 2009.
-
参考文献10 "Algorithm and Experiments in Testing Planar Graphs for Isomorphism"J.P. Kukluk, L.B. Holder, D.J. Cook, J. Graph Algorithms and Applications, vol. 8, no. 3, pp. 313-356, 2004.
-
参考文献2 “On Using q-Gram Locations inApproximate String Matching,”E. Sutinen and J. Tarhio, Proc. Third Ann. European Symp.Algorithms, pp. 327-340, 1995
-
参考文献25 Efficient Set Joins on Similarity Predicates,”S. Sarawagi and A. Kirpal, “ Proc. ACM SIGMOD, pp. 743-754, 2004

















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









