




 本文详细介绍了如何在YARN中配置日志聚合功能,包括设置日志存储时间、检测间隔及存储目录,以及如何通过配置mapred-site.xml来管理MapReduce作业历史记录。此外,还探讨了Uber模式的启用及其对小任务执行效率的影响。
本文详细介绍了如何在YARN中配置日志聚合功能,包括设置日志存储时间、检测间隔及存储目录,以及如何通过配置mapred-site.xml来管理MapReduce作业历史记录。此外,还探讨了Uber模式的启用及其对小任务执行效率的影响。
聚合日志:搜集每一个 container的log信息(较为细粒度的日志信息),并可以移动到hdfs等文件系统中。适合用于追踪每个container的情况。
在yarn-site.xml文件增加如下配置 并分发到另外的机子上 重启集群
[root@hadoop01 ~]# scp /usr/local/hadoop-2.7.1/etc/hadoop/yarn-site.xml hadoop02:/usr/local/hadoop-2.7.1/etc/hadoop/
配置:
<!--是否开启聚合日志-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--指定聚合日志存储时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!--聚合日志检测时间间隔-->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<!--指定userlog的保存时长-->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<!--聚合日志所保存的目录-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yarn/logs</value>
</property>
mapred-site.xml
<configuration>
<!--指定MapReduce的运行框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!-- MapReduce JobHistory Server地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MapReduce JobHistory Server Web UI地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<!-- MapReduce作业产生的日志存放位置 -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/mr-history/tmp</value>
</property>
<!-- 开启日志聚合 由mrjobhistory管理的日志-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/mr-history/done</value>
</property>
</configuration>
哦哦 对了要启动历史服务记录昂这个别忘了
启动 历史服务
mr-jobhistory-daemon.sh start historyserver
这样重启集群后 跑一个MapReduce任务 去查看19888端口的web ui
随便跑一个自带jar
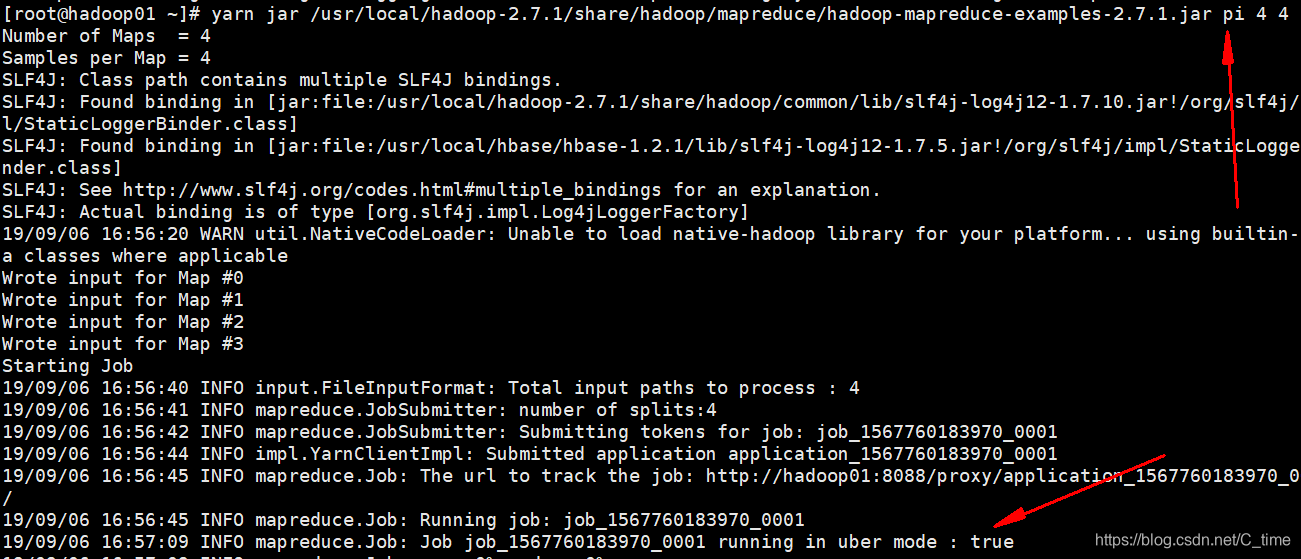
yarn jar /usr/local/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 4 4
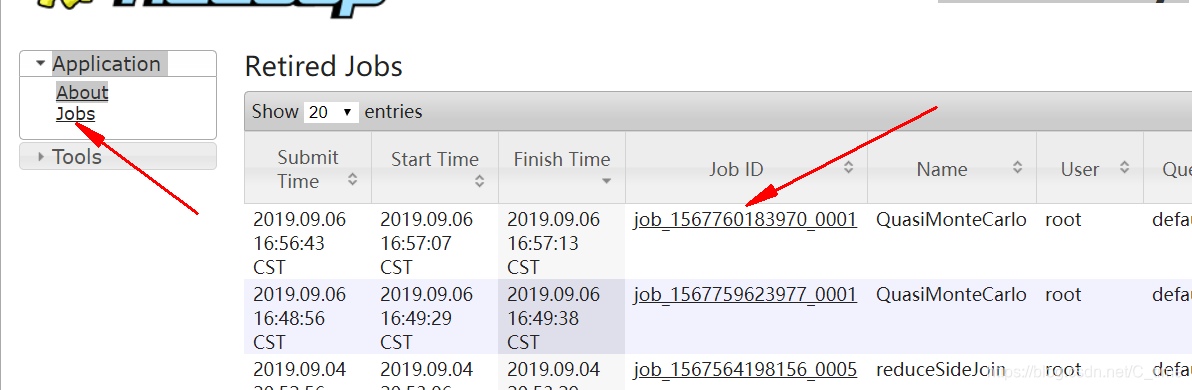
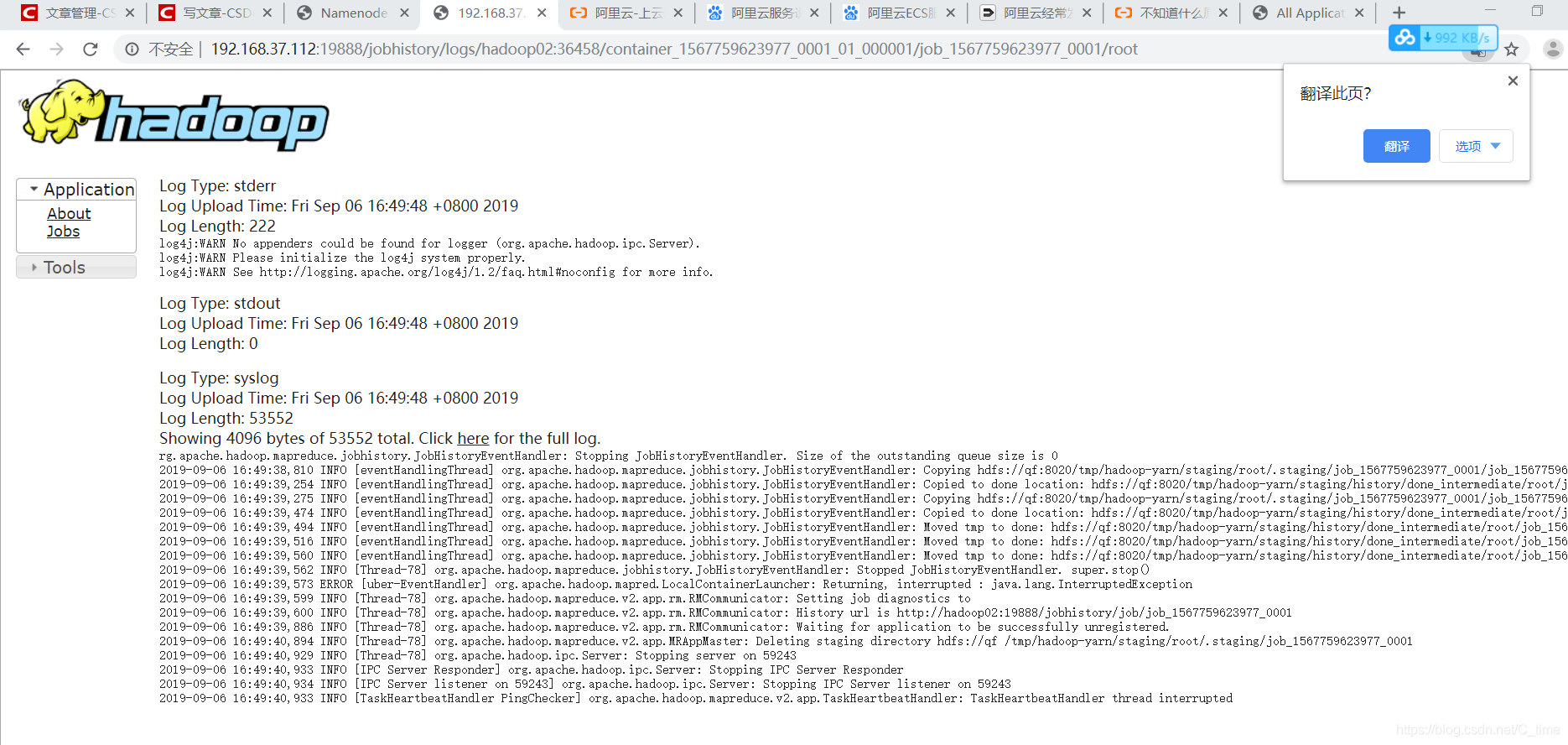
然后登陆19888端口就可以看到日志信息 点Jobs 然后找第一个 刚刚跑的任务 点进去 找logs 就可以看到了
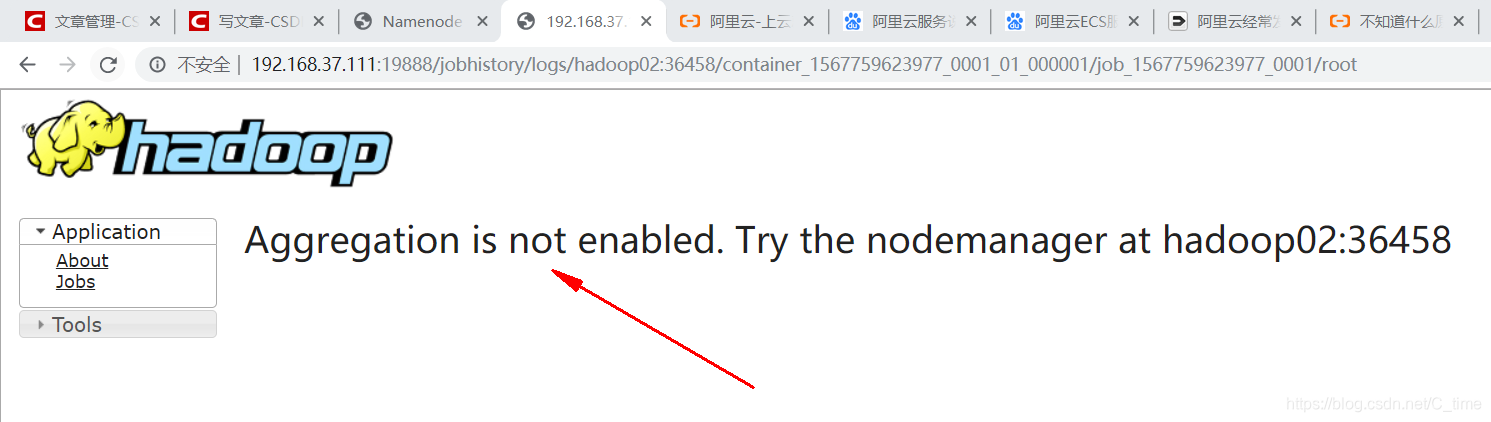
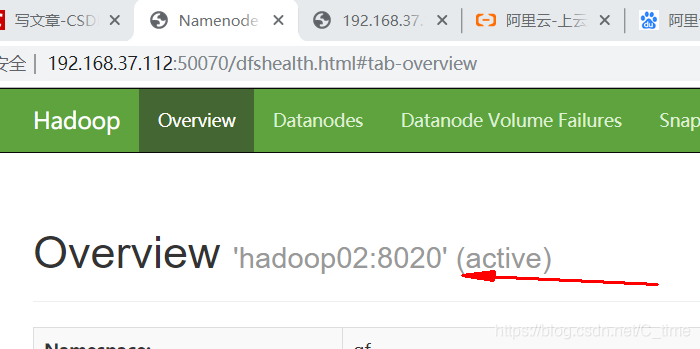
对了要用active的节点地址登陆
不然看不到 反正我没看到

用standby节点登陆告诉你这个
uber模式:允许小作业按序列在单个jvm中运行。
在mapred-site.xml中去添加配置(同步发送并重启):
<!--在mapred-site.xml中去添加配置(同步发送并重启):-->
<!-- uber模式:允许小作业按序列在单个jvm中运行。 -->
<!--开启 就是让一些小任务在一个container排队运行 不用一个task开启一个container了 -->
<!--比如说有三个小task每个运行要30秒 而开一个container要50秒 不开uber要90+150 开了就是50+90-->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- 下面是三个限制条件 要都满足才行 不满足就不启用uber模式 -->
<!-- maptask不超过9过 就可以使用uber -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- reduce任务不超过1个 就可以使用uber模式 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- (没有指定 默认块大小) 一个task没有超过默认大小 就可以使用uber -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>
小任务 你看开启了

















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









