







前言
本篇主要是为之后 SpringBoot 结合 DDD 领域驱动设计落地实践 的相关章节而服务,对于前面章节讲过的内容,后面不在赘述.
分页查询
定义分页查询通用模型
Note:
这里先简单提一嘴,之后直接将领域设计详细案例,不用记概念,简单知道一下即可,在代码层面会分为4层
- api 层:用来接收外部请求(前端请求).
- biz 层:业务编排层,与传统的三层架构中的 service(所有业务逻辑堆一起)不一样的是,这里是对拆分的业务逻辑进行编排.
- domain 层:领域层,是无状态的(不与数据库进行交互),对自己的领域数据进行纯内存操作.
- repo 层:仓储层,与数据库进行交互
- service 层:服务层,允许有状态(与数据库交互),对复杂业务逻辑的整合.
1)自定义一个数据类 PageResp,用来封装在 repo 层分页查询的结果.
data class PageResp<T> (
var result: List<T> = emptyList(), // 结果数据
var hasMore: Boolean = false, // 是否有更多数据
var nextStart: Long = 0, // 下一个数据的起始偏移量
var total: Long? = null // 数据总量
) {
companion object {
private const val serialVersionUID: Long = 260564179048006430
/**
* 不用计算总数的分页查询(一般用于用户侧)
*/
fun <T> ok(more: Boolean, nextStart: Long, objectList: List<T>): PageResp<T> {
return PageResp(hasMore = more, nextStart = nextStart, result = objectList)
}
/**
* 计算总数的分页查询(一般用户运营测(公司内部人员))
*/
fun <T> ok(more: Boolean, nextStart: Long, objectList: List<T>, total: Long?): PageResp<T> {
return PageResp(hasMore = more, nextStart = nextStart, result = objectList, total = total)
}
fun <T> empty(): PageResp<T> {
return PageResp()
}
}
}
2)说明:
- result:用来保存从数据库中查询出的结果.
- hasMore:此次分页查询后,是否还有更多数据(下一分页查询是否还能查到数据),外部(例如前端)可以根据此字段判断是否还要再分页查询下一页.
- nextStart:下一次分页查询的起始偏移量,可以理解为就是 mysql 查询中的 offset 值,外部(例如前端)下一次再进行分页查询时,直接带入此值作为 offset 即可.
- total:总数,是可选的. 因为有些时候并不需要这个值,并且
select count(*)操作是有额外开销的(数量大的时候尤为明显).
案例所需环境
后续的案例,主要是使用 MyBatis Plus 实现的,这里我给出必备环境(你拷贝过去直接可以运行).
1)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.7</version>
<relativePath/>
</parent>
<groupId>org.cyk</groupId>
<artifactId>tpl</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>tpl</name>
<description>tpl</description>
<properties>
<java.version>21</java.version>
<kotlin.version>2.2.20</kotlin.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-kotlin</artifactId>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-reflect</artifactId>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib</artifactId>
</dependency>
<!-- mybatis plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.14</version>
</dependency>
<!-- mysql 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-test-junit5</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>${project.basedir}/src/main/kotlin</sourceDirectory>
<testSourceDirectory>${project.basedir}/src/test/kotlin</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-plugin</artifactId>
<configuration>
<args>
<arg>-Xjsr305=strict</arg>
</args>
<compilerPlugins>
<plugin>spring</plugin>
</compilerPlugins>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-allopen</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
</project>
2)配置文件(也可以用 yml,确实有很多好处,不过个人比较在意可读性,比 yml 的缩进可读性好太多了)
server.port=8080
spring.application.name=tpl
# mysql
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=1111
# mybatis plus
mybatis-plus.global-config.db-config.id-type=auto
mybatis-plus.configuration.map-underscore-to-camel-case=true
mybatis-plus.configuration.cache-enabled=false
mybatis-plus.type-aliases-package=org/cyk/tpl/infra/repo
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
mybatis-plus.global-config.db-config.id-type=auto:主键生成策略为 id 自增mybatis-plus.configuration.map-underscore-to-camel-case=true:自动下划线转驼峰mybatis-plus.type-aliases-package=org/cyk/tpl/infra/repo:mapper 注解扫描路径mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl:打印执行 sql(生产环境要去掉)
3)DO 模型(这个模型和数据库字段一一映射)
import com.baomidou.mybatisplus.annotation.TableId
import com.baomidou.mybatisplus.annotation.TableName
import com.baomidou.mybatisplus.core.mapper.BaseMapper
import com.baomidou.mybatisplus.extension.kotlin.KtQueryWrapper
import org.apache.ibatis.annotations.Mapper
import org.springframework.stereotype.Repository
import java.util.Date
/*
create table article_info(
id int auto_increment comment '文章id',
user_id int not null comment '用户id',
title varchar(128) not null comment '标题',
content text not null comment '内容',
state int not null comment '状态 1正常 2封禁',
created_at bigint not null comment '创建时间',
updated_at bigint not null comment '修改时间',
primary key (id),
key idx_user_id (user_id),
key idx_state(state)
);
*/
@TableName("article_info")
data class ArticleInfoDo(
@TableId
val id: Int,
val userId: Int,
val title: String,
val content: String,
val state: Int,
val createdAt: Long,
val updatedAt: Long,
)
4)这里我造了一些假数据,方便后续的分页查询效果的演示
insert into article_info values
(null, 100, '标题1', '这是一个长文本1', 1, 1762593905459, 1762593905459),
(null, 100, '标题2', '这是一个长文本2', 1, 1762593905459, 1762593905459),
(null, 100, '标题3', '这是一个长文本3', 1, 1762593905459, 1762593905459),
(null, 100, '标题4', '这是一个长文本4', 1, 1762593905459, 1762593905459),
(null, 100, '标题5', '这是一个长文本5', 1, 1762593905459, 1762593905459),
(null, 100, '标题6', '这是一个长文本6', 1, 1762593905459, 1762593905459),
(null, 100, '标题7', '这是一个长文本7', 1, 1762593905459, 1762593905459),
(null, 100, '标题8', '这是一个长文本8', 1, 1762593905459, 1762593905459),
(null, 100, '标题9', '这是一个长文本9', 1, 1762593905459, 1762593905459),
(null, 100, '标题10', '这是一个长文本10', 1, 1762593905459, 1762593905459),
(null, 200, '标题11_200', '这是一个长文本...', 1, 1762593905459, 1762593905459);
5)文章领域模型.
从数据库中查询出来会映射到 DO 模型上(DO 模型不参与业务代码),需要将 DO 通过手写 map 转化成 领域模型,再参与业务代码.
这里做主要是为了对数据库字段的兼容,因为领域模型中的字段值可能会是另一个实体类(子领域).
后续章节会有实际案例,敬请期待~
enum class ArticleInfoState(
val code: Int
) {
// 正常
NORMAL(1),
// 禁用
BAN(2),
;
companion object {
fun ofOrThrow(code: Int): ArticleInfoState = entries.firstOrNull { it.code == code }
?: throw IllegalArgumentException("非法 state")
}
}
data class ArticleInfo(
val id: Int? = null,
val userId: Int,
val title: String,
val content: String,
val state: ArticleInfoState,
val createdAt: Date = Date(),
val updatedAt: Date = createdAt,
)
分页查询方式一(无 total)
1)代码:
@Mapper
interface ArticleInfoMapper: BaseMapper<ArticleInfoDo>
@Repository
class ArticleInfoRepoImpl(
private val articleInfoMapper: ArticleInfoMapper
): ArticleInfoRepo {
override fun pageWithHasMore(cmd: PageArticleInfoCmd): PageResp<ArticleInfo> {
val start = cmd.start.takeIf { it >= 0 } ?: 0
val limit = cmd.limit.takeIf { it in (0 .. 100) } ?: 24
val qw = KtQueryWrapper(ArticleInfoDo::class.java)
qw.eq(ArticleInfoDo::userId, cmd.userId)
qw.like(cmd.title.isNullOrBlank().not(), ArticleInfoDo::title, cmd.title)
qw.eq(cmd.state != null, ArticleInfoDo::state, cmd.state!!.code)
qw.orderBy(true , true, ArticleInfoDo::id) // id 正序
qw.last("limit ${limit + 1} offset $start")
val result = articleInfoMapper.selectList(qw)
val hasMore = result.size > limit
if (hasMore) {
result.removeLast()
}
return PageResp.ok(
more = hasMore,
nextStart = (start + limit).toLong(),
objectList = result.map { map(it) }
)
}
private fun map(it: ArticleInfoDo): ArticleInfo = with(it) {
ArticleInfo(
id = id,
userId = userId,
title = title,
content = content,
state = ArticleInfoState.ofOrThrow(state),
createdAt = Date(createdAt),
updatedAt = Date(updatedAt),
)
}
}
2)说明:
- 注意 start、limit 的越界情况,避免一次查询过大,导致大量慢查询.
- 分页查询时的 limit 这里会 +1,也就是将来会多查询一个,这样做主要是为了判断是否还有更多数据(是否能进行下一次分页查询). 也就是说 如果此次分页查询的数据量 大于 分页请求中 limit,说明还有更多数据,就可以通过 hasMore 告诉外部(例如前端),还可以进行下一次分页查询.
- 如果 hasMore 为 true(还能进行下一次分页查询),记得最后需要删除查询结果的最后一个数据(这最后一个数据,本来就是用来计算 hasMore 才用到的)
- 这样一个优雅的分页查询就实现了.
这种分页查询的方式是不知道 total 的,比较适合对于用户侧的查询(页面上不需要展示 total),因为用户侧的请求量一般是要比企业内部人员请求量要大的多的,并且在分页查询时如果还需要知道 total 就需要额外的开销(数据量大的情况下可能反而会拖慢分页查询).
Ps:这里有人可能会说了:“为什么不用 mybatis plus 提供的分页查询插件?”
- 我嫌麻烦,还要额外配置一个插件,引入一个 依赖…
https://baomidou.com/plugins/pagination/- mybatis plus 提供的分页插件是基于页码的,个人习惯基于偏移量 offset
3)单测效果
@Test
fun testHasMore() {
val cmd = PageArticleInfoCmd(
start = 0,
limit = 5,
userId = 100,
title = "标题",
state = ArticleInfoState.NORMAL,
)
val r = articleInfoRepo.pageWithHasMore(cmd)
println("==================================================")
println("hasMore: ${r.hasMore}")
println("nextStart: ${r.nextStart}")
r.result.forEach {
println("==================================================")
println(it)
}
println("==================================================")
}
当 start = 0、limit = 5 时,查询结果如下:
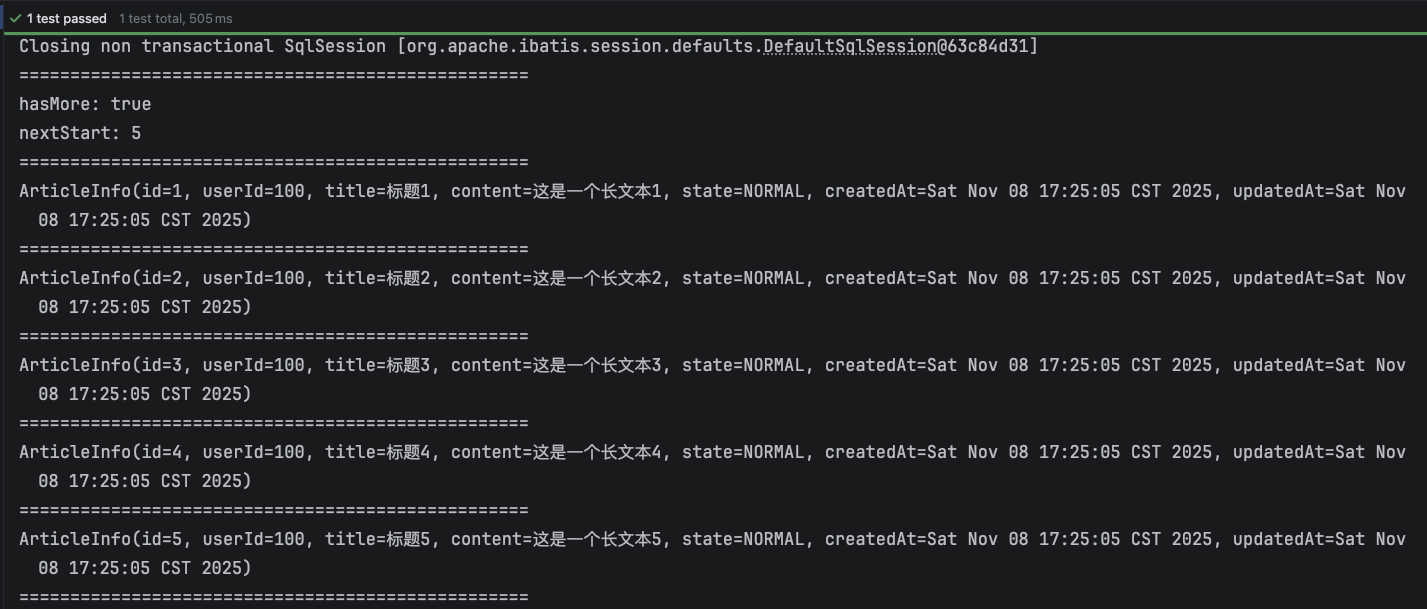
通过上述 hasMore 可以知道,可以进行下一次分页查询. 通过 nextStart 可以知道下一次分页查询 start = 5. limit = 5 保持不变,查询结果如下:
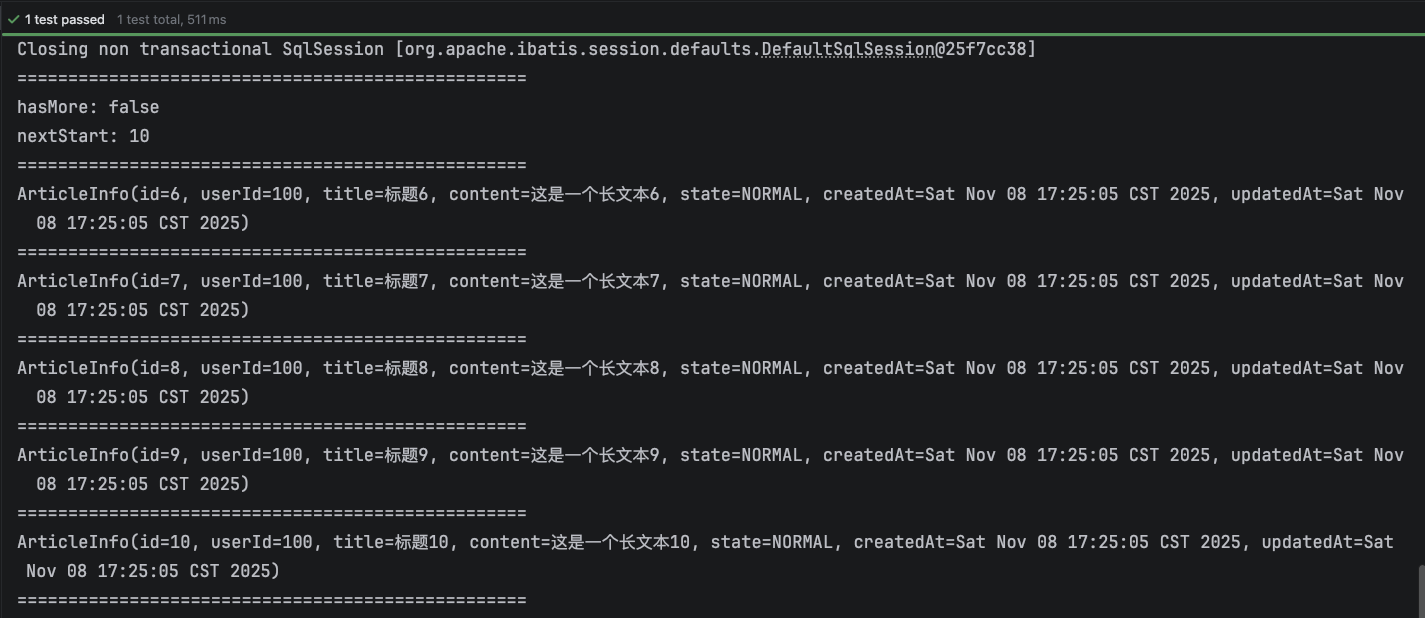
通过上述 hasMore 可以知道,没有更多数据了,无须进行下一次分页查询.
分页查询方式二(有 total)
1)代码
@Mapper
interface ArticleInfoMapper: BaseMapper<ArticleInfoDo>
@Repository
class ArticleInfoRepoImpl(
private val articleInfoMapper: ArticleInfoMapper
): ArticleInfoRepo {
override fun pageWithTotal(cmd: PageArticleInfoCmd): PageResp<ArticleInfo> {
val start = cmd.start.takeIf { it >= 0 } ?: 0
val limit = cmd.limit.takeIf { it in (0 .. 100) } ?: 24
val qw = KtQueryWrapper(ArticleInfoDo::class.java)
qw.eq(ArticleInfoDo::userId, cmd.userId)
qw.like(cmd.title.isNullOrBlank().not(), ArticleInfoDo::title, cmd.title)
qw.eq(cmd.state != null, ArticleInfoDo::state, cmd.state!!.code)
qw.orderBy(true , true, ArticleInfoDo::id) // id 正序
val total = articleInfoMapper.selectCount(qw)
if (total == 0L) {
return PageResp.empty()
}
qw.last("limit $limit offset $start")
val result = articleInfoMapper.selectList(qw)
val hasMore = total > start + limit
return PageResp.ok(
more = hasMore,
nextStart = (start + limit).toLong(),
objectList = result.map { map(it) },
total = total
)
}
private fun map(it: ArticleInfoDo): ArticleInfo = with(it) {
ArticleInfo(
id = id,
userId = userId,
title = title,
content = content,
state = ArticleInfoState.ofOrThrow(state),
createdAt = Date(createdAt),
updatedAt = Date(updatedAt),
)
}
}
2)说明:
- 首先验证 start limit 越界情况,避免查询过大.
- 先构造查询条件,但不要加上
limit offset分页条件(不然你计算的总数就是这一页的总数…),用来先计算总数据量,如果数据量为0,就没必要再查了,直接返回空列表 - 查询完总数之后,再给查询条件加上
limit offset构造分页请求(这里 limit 就不用 +1 了,因为可以直接根据 total 计算出 hasMore),进行分页查询. - hasMore 的计算:只要
total > start + limit即可,start 你可以直接理解为之前分页查询的总共查出了多少数据,limit 理解为这次分页查询的数据量(这里也可以用 result.size(),但是你可以思考一下,虽然limit >= result.size()对于计算 hasMore 本质是没区别的). - 至此,分页查询完成
拓展:通过分页查询,查询出所有数据
有些时候,我们想查询出符合条件的所有数据,但是如果一次查询不带上 limit offset,可能会查询过慢. 因此就需要通过多次分页查询,来查询出所有数据.
打个比方:你有 20 个大快递,你一个人一次取完所有的扛回家,不得把你累死. 所以只有你一个人的情况下,比较好的方案就是分几次取拿,一次拿 3~4个. MySQL 也是如此,你每次插叙都会造成 IO、消耗网络带宽,一次拿的东西太多了,可能扛不住(不如分批多次拿).
代码如下:
private fun queryAll(): List<ArticleInfo> {
val resultList = mutableListOf<ArticleInfo>()
var start = 0
val limit = 2 // 这里是为了掩饰效果,所以 limit 设置的比较小. 实际开发中比较多的会设置成 200(当然也要结合你的数据量来决定)
// 第一次分页请求,主要为了拿到 total,方便计算出剩余分页次数
val firstReq = PageArticleInfoCmd(
start = start,
limit = limit,
userId = 100,
title = "标题",
state = ArticleInfoState.NORMAL,
)
val firstResp = articleInfoRepo.pageWithTotal(firstReq)
resultList.addAll(firstResp.result)
// 没有更多了,直接返回
if (firstResp.hasMore.not()) {
return resultList
}
val total = firstResp.total!!
// 计算还需要分页查询的次数
// loop 粗略计算次数多了一点没关系,因为分页查询过程中如果判断没有更多了,就直接退出循环了,主要是为了避免 while(true) 这种写法
val loop = total / limit
for (i in 1 .. loop) {
start += limit
val nReq = firstReq.copy(
start = start,
)
val nResp = articleInfoRepo.pageWithHasMore(nReq)
resultList.addAll(nResp.result)
if (nResp.hasMore.not()) {
return resultList
}
}
return resultList
}
说明:第一次查询,主要是为了得到 total 值,用来计算总共需要进行多少次分页查询可以拿到所有数据,之后每次分页查询就可以通过 pageWithHasMore 来实现(之后的每次分页查询就没必要计算 total 了).
“为什么不用 while(true) 的写法?这样岂不是都不用查 total.”
这,你自己写 demo,自己玩没事,但是如果是公司的代码,可千万别这么写,你说万一他要是死循环了呢?导致你生产环境的 应用 挂了,这责任,你可担不起. 再退一步讲,当前你的代码用 while(true) 确实没事,但要是你的sb同事并不知情,直接改了你的 repo,造成了死循环呢?所以,保险起见,一般情况下尽量不要写 while(true)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











