



数据样式:
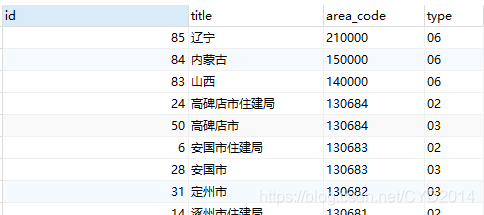
sql:
SELECT id,title,area_code,type
FROM (select id,title,area_code,type from dictionary_data where area_code having 1 order by area_code DESC) b
GROUP BY type;
 该博客探讨了一段复杂的SQL查询,它从dictionary_data表中选取id、title和area_code字段,通过area_code进行过滤和排序,然后按type进行分组。博客内容涉及数据库管理和信息检索,是数据库技术人员的宝贵资源。
该博客探讨了一段复杂的SQL查询,它从dictionary_data表中选取id、title和area_code字段,通过area_code进行过滤和排序,然后按type进行分组。博客内容涉及数据库管理和信息检索,是数据库技术人员的宝贵资源。
数据样式:
sql:
SELECT id,title,area_code,type
FROM (select id,title,area_code,type from dictionary_data where area_code having 1 order by area_code DESC) b
GROUP BY type;
 5836
5836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























